
20190901(小明种苹果)
代码1
用struct AppleTree记录苹果树的相关信息,比如一开始的总苹果树,总共疏果的个数。苹果树编号从1开始
1 | struct AppleTree{ |
有数据AppleTree trees[]。然后写一个cmp函数,对所有的AppleTree进行排序。
1 | //freopen("D://input.txt","r",stdin); |
20190902(小明种苹果续)
代码1
我们设置一个结构体struct AppleTree来表示每个苹果树的id,一开始苹果树,疏果的个数,掉落的个数。
1 | struct AppleTree{ |
在第一次统计之后,以后每遇到疏果值,就累加shuguoNum,每遇到统计值a,就计算totNum-shuguoNum-dropNum-a,就得到当前的掉落的苹果个数,累加至dropNum。
如何计算相邻连续三棵苹果树发生苹果掉落情况的组数?int E,对于每个tree[i],0<=i<=n-1,计算它前面的,它,它后面的是否都掉落了,若是,则累加组数E。
1 | //freopen("D://input.txt","r",stdin); |
测试用例
1 | 4 |
20190903(字符画)
代码1
我用array<int,3> picture[][] 来表示图画,用array<int,3> curBack 记录当前的背景颜色, 默认是0,0,0 。由于每一行有m/p个小区域,然后整个图画被分为n/q行,因此我要遍历m*n/(p*q)次,这样遍历:先遍历一行,看一个区域的颜色,若它的颜色跟当前的curBack相同,则直接输出空格,否则,更改终端的背景色(若颜色正好为黑色,则使用重置终端),然后输出空格,遍历了一行后,若与默认背景色不同,则重置终端,最后输出换行符。
对于输入,要判断三种情况:#abcd #abc #a
1 | //freopen("D://input.txt","r",stdin); |
80分。
20190904(推荐系统)
代码1
设计一个结构体struct Commodity,表示商品,设有属性:商品的类别,商品编号,商品的得分。
1 | struct Commodity{ |
有一个set<Commodity> cmdSet ,存有每个商品的信息,显然需要指定比较函数,先按score,然后按照type,然后按照id。如果要删除或增加,只需要正常操作就好了。如果要查询,则用迭代器从头开始查,若某类商品已经选择够了,则跳到下一类商品继续查,直到达到了总的查询商品数或遍历完毕, 在这个过程中,保存商品类别到商品编号集合的映射, vector<set<int>> ans,不用map<int,vector<int>> ans的原因是,它较慢。
1 | //freopen("D://input.txt","r",stdin); |
这个代码是通过的。我以前犯的错误是删除:我才用迭代的方式逐个去比较每个商品的type与id和给的type与id是否相同,然后删除,但是这样会很耗时,所以0分了,正确的做法是,对每个type建立id到score的映射,也就是unordered_map<int,int> idToScore[MAXM],这样的话,可以使用函数cmdSet.erase(Commodity(type,id,score)) 来删除,效率更高。
20190905(城市规划)
代码1
设置一个邻接表vector<vector<int>> dis 表示相邻两个点之间的最短路径,当然一开始只有直接相连的两个点的最短距离,之后可以用floyd算法算出每两个点之间的最短距离。设置一个vector<int> imp 表示重要的点的集合,然后不断选出K个点,计算它们的两两之间距离总和。
关于如何选出K个点,可以使用递归的方式。
具体如何写递归,可以看代码具体实现
1 | //freopen("D://input.txt","r",stdin); |
0分。超时
代码2
但是floyd算法太慢了,由于这个题本身考虑的是树,所以可以用每个点的BFS来求最短路径,把floyd算法替换掉。
1 | //freopen("D://input.txt","r",stdin); |
0分。还是超时。
代码3
这题采用动态规划的方法,但是这个动态规划是最难的。dp[i][j] 表示以i为根节点的子树中选j个重要节点时,这个子树内选中的重要节点的两两距离之和,再加上,子树内j个重要节点到达剩余K-j个重要节点需要经过的子树内路径的长度之和。

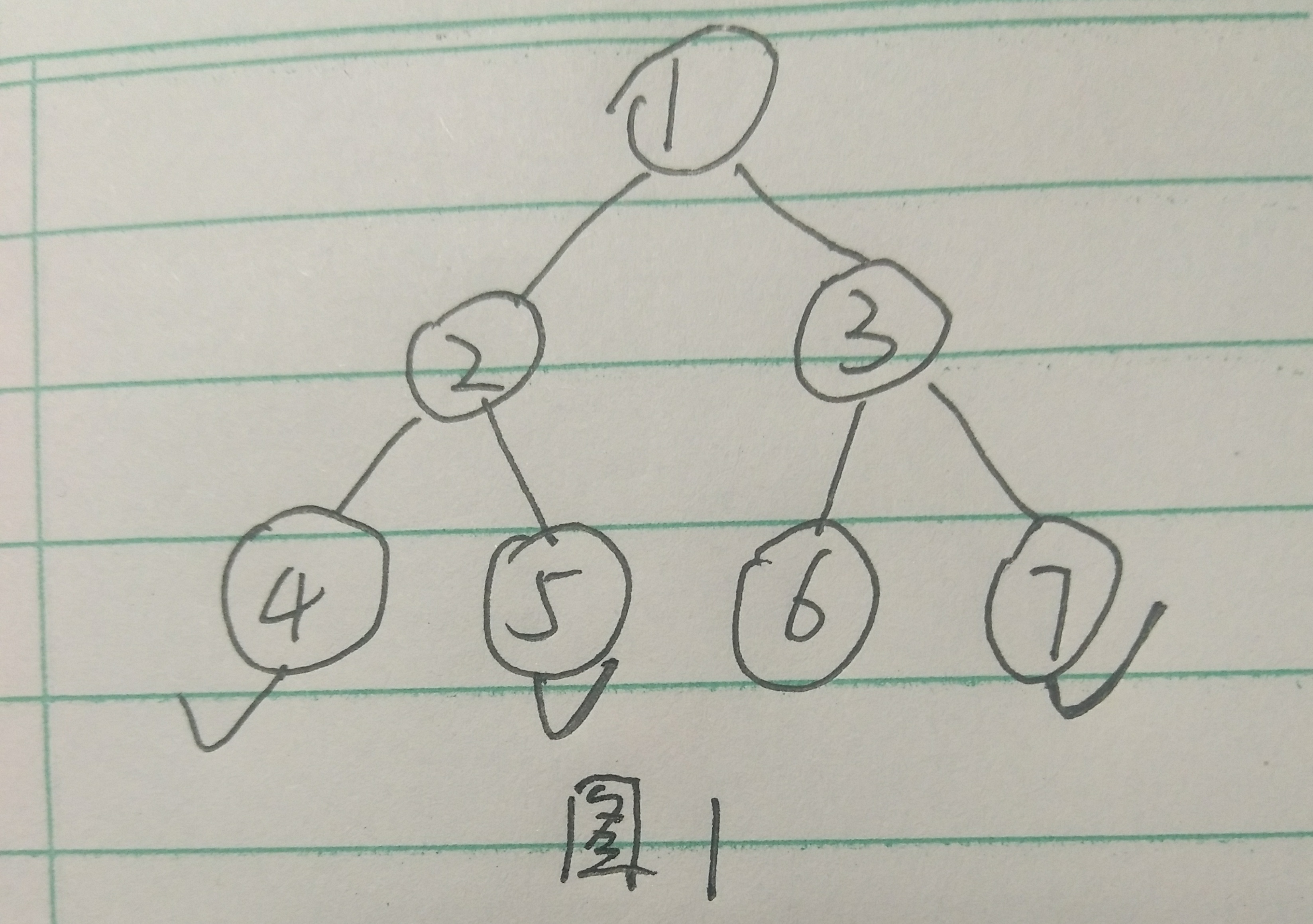
例如图1,要选出3个重要节点。在1子树中,dp[1][2] = 2+2+2,(注意,这里的dp[1][2]没有计算完,只是中间值,后面还要考虑(3,6,7)部分才能得到最终解),第一个2表示4和5之间的距离,第二个2表示4为了到达剩余的3-2=1个重要节点所需要经过的<4,2,1>这个1子树内路径的长度之和,也就是1=<4,2,1>的长度 (3-2);对于第三个2,表示5为了到达剩余的3-2个重要节点所需要经过的<5,2,1>这个1子树内路径的长度之和,也就是1=<5,2,1>的长度 (3-2)。
但是如何用递推的方式求dp[i][j] 呢。对于图1的2子树,dp[2]的计算由它的子树4和5的dp计算而来。dp[i]初始为{0, -1, -1},表示i子树选中0个重要节点时,dp值为0,选中1个和2个重要节点时,dp值为-1,也就是表示2子树内选择不出这么多的重要节点。下面是计算过程的样例。
- 计算dp[4]为
{0, 0, -1} - 更新dp[2]为
{0, 2, -1}, 这个结果是(2,4)部分的dp[2]的结果。 - 计算机dp[4]为
{0, 0, -1} - 更新dp[2]为
{0, 2, 4},这时,要合并(2,4)部分和(5)部分。(2,4)部分有1个选中的重要节点,(5)部分有1个选中的重要节点,因此(2,4,5)可以有2个选中的重要节点,dp[2][2] = dp[2][1] + dp[5][1] + 2。2代表5到达另外两个重要节点,所要经过的2次<5,2>路径的长度之和。dp[2][1]=0+1+1,dp[5][1]=0,所以dp[2][2] = 0+1+1+0+1+1,第1个1和第3个1组成2,表示4和5之间的距离,第2个1表示4到达另外一个重要节点要经过的<4,2>路径长度,第4个1表示5到达另外一个重要节点要经过的<5,2>路径长度。
还有一个问题,要更新dp[i]时,从dp[i][k]更新到dp[i][1] 还是从dp[i][1] 更新到dp[i][k]。答案是前者,如果要用后者,可以开一个dp2,然后计算完成后,把dp2赋值到dp就好了。
还有一个情况,万一2子树的根节点2就是重要节点呢?我们之前的计算只考虑2子树的子树的重要节点情况对于2子树的影响,但是没有考虑2节点本身。假如2子树的子树有2个重要节点,那么2子树的dp[2][2]可以为选择2节点和子树中的1个节点组成的2个选中的重要节点,说不定这种情况就比选择2子树的子树中的2个重要节点的情况要好。而且,2子树也可以有选择3个重要节点的情况,也就是子树中的2个加上2节点的1个。
还有就是最优性原理的证明。dp[i][j]的j个重要节点是来自不同的子树的,那么不同的情况选出不同的dp[i][j] 的值,当然最小的那个就是最优的,假如后面的最优决策中用到了这个dp[i][j],那么是否说明这个dp[i][j]就是最优的?是的。为什么?因为dp[i1][j1] = dp[i][j] + dp[i1][j2] + num 这个公式是进行推导dp的递推式,假如后面的决策最优,那么dp[i][j]也最优。
1 |
|