
概述
从9月2号到月6号,进行了简单的学院实习,这段时间主要是做了:
- VMware CentOS7虚拟机的网络配置,包括桥接模式和NAT模式,
- hadoop伪分布式集群的配置,
- hadoop完全分布式集群的配置,
- mapreduce实战
用到的资源文件都在百度网盘上:链接:https://pan.baidu.com/s/1JLTTnNINlBHlGTktUjU57w
提取码:zxxp
百度网盘上就是hadoop文件,jdk,VMware,CentOS7等。
VMware CentOS7虚拟机的网络配置
虚拟机的三种网络连接模式
安装VMware,在Windows上配置网络, 然后在VMware上安装了CentOS7虚拟机后可以正常联网的。
打开设置/网络和Internet设置/更改适配器选项,在我的电脑上会看到以下界面:


WLAN属性使用Intel(R) Dual Band Wireless-AC 7265 无线网卡,MAC地址是:D4-25-8B-8A-76-EA。此连接使用下列项目中包含:Microsoft网络客户端,VMware Bridge Protocol,Internet协议版本4(TCP/IP4)。我发现,这个网卡与以太网属性使用的网卡不一样,当然MAC地址也不会一样。
然后就有VMware Network Adapter VMnet1和VMware Network Adapter VMnet8两块虚拟网卡,分别用于虚拟机的host-only网络连接模式和NAT模式。除此之外,还有虚拟机的桥接模式。
桥接模式(Bridged)
网上一图搞懂桥接模式。

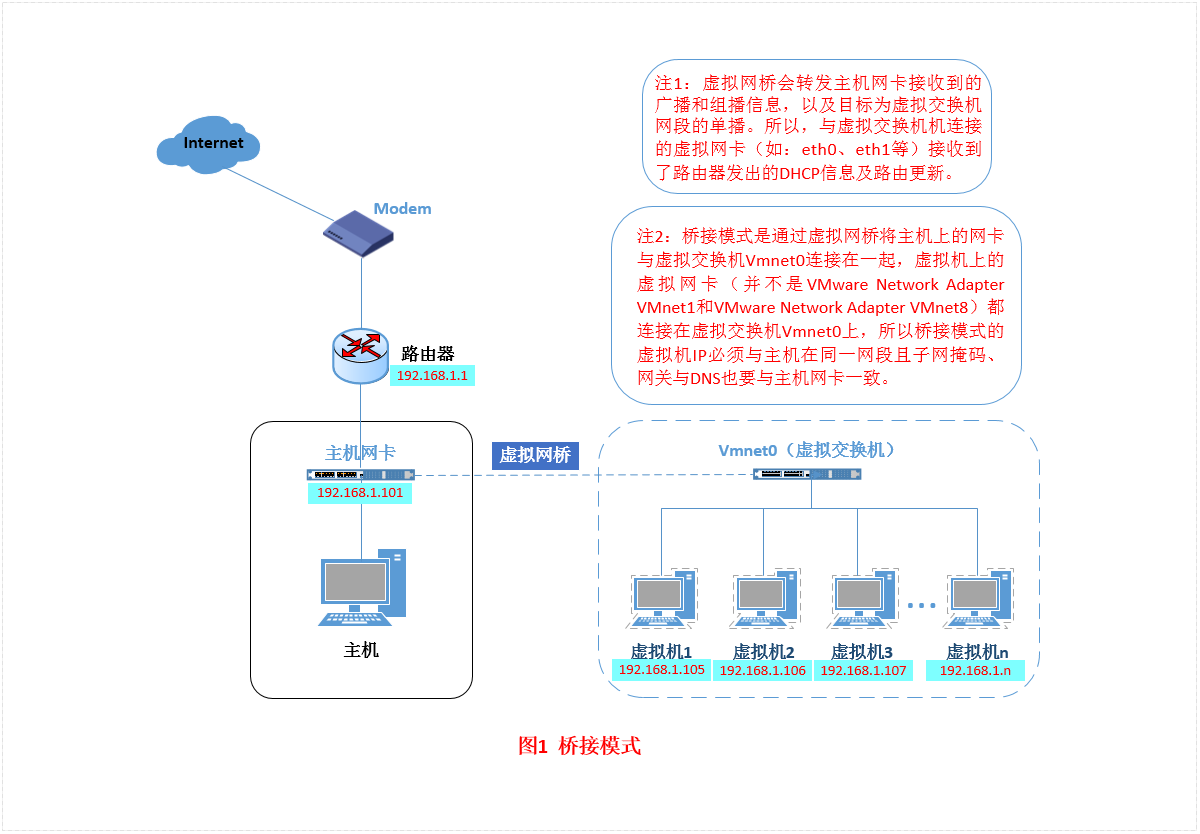
VMnet0是虚拟机使用的虚拟交换机,而不是虚拟网卡。每台使用桥接模式的虚拟机都有虚拟网卡(如eth0,eth1等),这些虚拟网卡连接到虚拟交换机VMnet0。
桥接模式完全使用主机网卡(WLAN或以太网)的网络配置,因此网关,掩码,DNS要和主机网卡一致。查看主机网卡配置可以直接在 设置/网络和Internet设置/更改适配器选项 里面查看,或者在cmd下运行ipconfig。
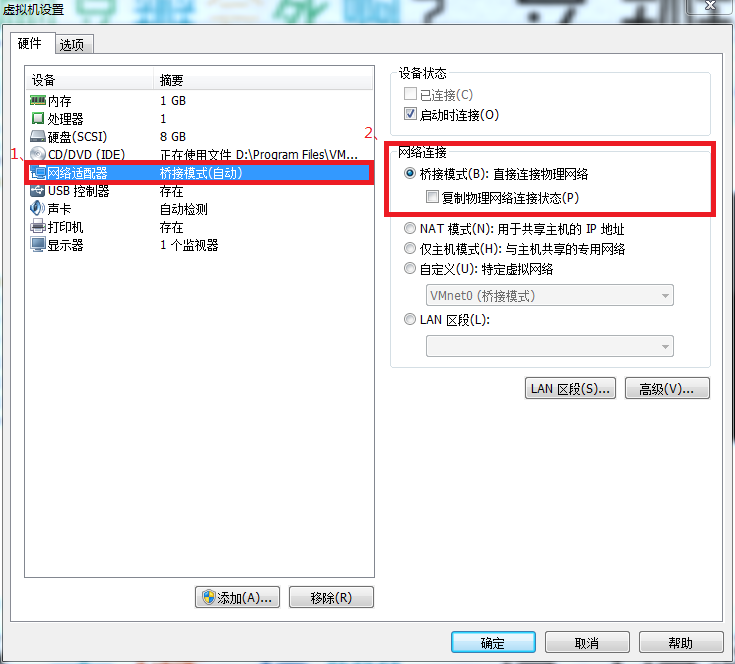
在开启虚拟机之前右击虚拟机(如hadoop01)来更改网络适配器,网络连接选择桥接模式。

然后进入虚拟机之后,CentOS7有这样一个文件/etc/sysconfig/network-scripts/ifcfg-Wired_connection_1 ,对linux网络设置下的更改将写到这个文件中,也可以直接在这个文件中进行配置,我的配置是下面的。
1 | HWADDR=00:0C:29:D1:E3:E6 |
配置完成之后重启网络服务,应该就可以ping通网络了。
1 | systemctl stop NetworkManager.service |
如果这个时候不能成功,可能就是VMware/编辑/虚拟网络编辑器的设置有问题。


看到了桥接到 这几个字,不要选自动。上面我们看到windows下WLAN使用Intel(R) Dual Band Wireless-AC 7265 无线网卡,由于我的电脑目前连接的是手机热点,应该使用无线网卡,所以这里选择第3项:Intel(R) Dual Band Wireless-AC 7265。
NAT模式(地址转换模式)
使用NAT只为一个原因:网络IP资源紧张

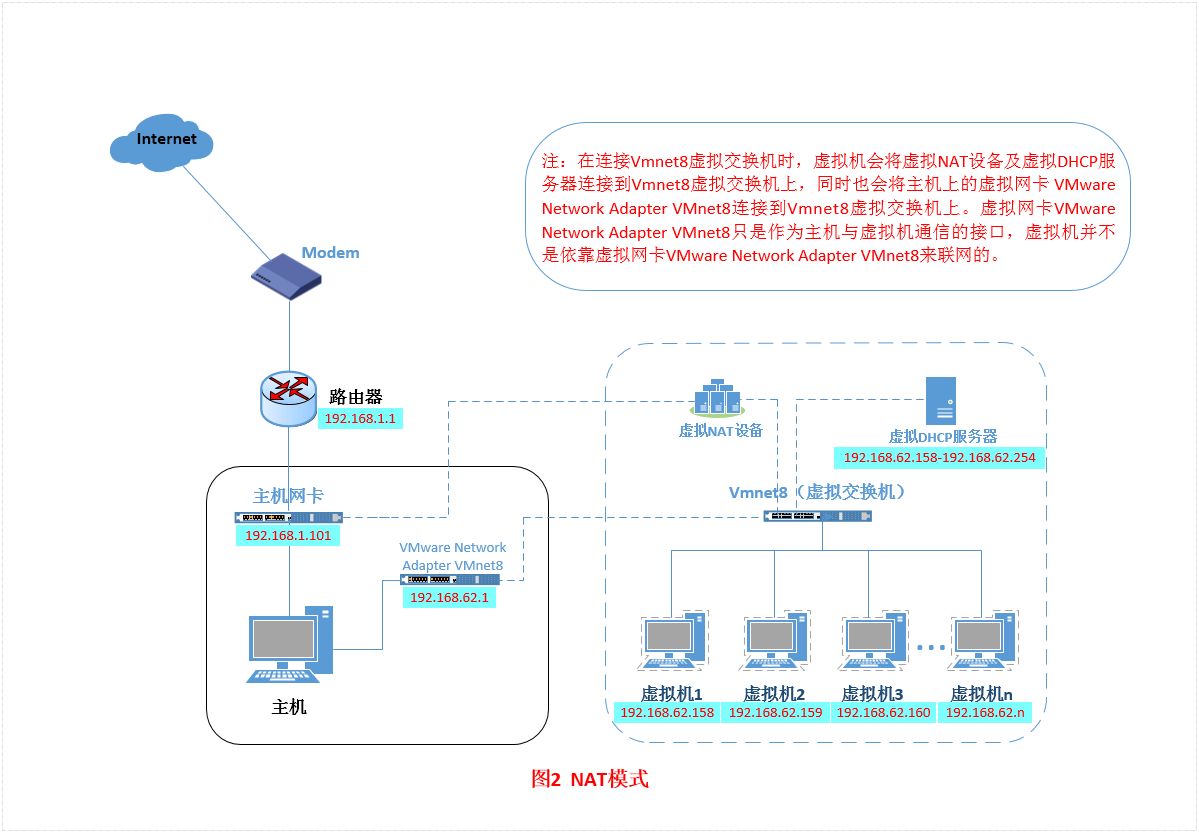
这张图比较好理解虚拟机和主机是如何部署虚拟机的NAT网络连接模式的。
主机网卡直接与虚拟NAT设备相连,然后虚拟NAT设备与虚拟DHCP服务器一起连接在虚拟交换机VMnet8上,所以即使禁用VMware Network Adapter VMnet8虚拟网卡,虚拟机也可以连接到外网,但是主机上的远程连接工具如secureCRT就无法连接到虚拟机了。
配置
首先配置windows下的设置/网络和Internet/,右击以太网或者WLAN,选择共享,然后勾住允许其他网络用户通过此计算机的Internet连接来连接,然后家庭网络连接选择VMware Network Adaper VMnet8,然后右击右击VMware Network Adaper VMnet8 虚拟网卡,双击Internet协议版本4(TCP/IP4),然后就可以编辑VMware Network Adaper VMnet8的IP地址了,使用与主机不同的网段。
打开VMware,点击编辑/虚拟网络编辑器,选择NAT模式,然后编辑子网IP和子网掩码,NAT设置和DHCP设置。

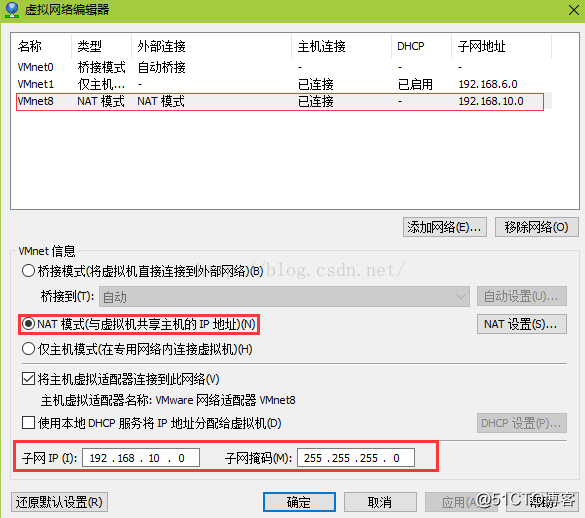
NAT设置是为了编辑NAT虚拟设置对内端口,也就是虚拟机网关,的IP地址。DHCP设置是为了编辑自动分配IP地址的范围,可以不用配置DHCP设置,因为等下使用静态方式配置虚拟机IP,而不是DHCP模式。
接下来配置虚拟机的 /etc/sysconfig/network-scripts/ifcfg-ens33文件,
1 | DEVICE="ens33" |
为什么使用BOOTPROTO=static,因为要记录每台主机的主机名与IP的映射关系,如果使用DHCP模式,那么主机的IP就会总是变化。
然后重启网络服务,就可以ping通外网了(虽然实际上,总会有那么一段玄学时间,ping不通baidu,却可以ping通网关)。
关闭防火墙
如果不关闭虚拟机上的防火墙,可能从外面Ping不同虚拟机。
1 | systemctl stop firewalld.service |
修改主机名
1 | vi /etc/sysconfig/network |
1 | vi /etc/hostname |
hadoop伪分布式
hadoop伪分布式就是在一台主机上安装5台虚拟机,然后同时开启所有虚拟机,就可以运行mapreduce。5台主机使用NAT模式进行网络连接。首先配置hadoop01虚拟机,然后再拷贝到hadoop02-04。
单一主机的配置
环境变量
通过secuerFX把windows下的jdk1.8.0_144, hadoop2.7.2传到虚拟机上,安装jdk和hadoop。
把jdk解压到/home/app下:
1 | tar -zxvf jdk-8u144-linux-x64.tar.gz -C /home/app |
然后改jdk1.8.0_144文件夹名为jdk1.8
添加JAVA环境变量:
1 | vi /etc/profile |
把hadoop解压到/home/app下:
1 | tar -zxvf hadoop-2.7.2.tar.gz -C /home/app |
添加HADOOP的环境变量:
1 | vi /etc/profile |
然后进入/home/app/hadoop-2.7.7/ 文件夹,这是hadoop的根目录,进行相关文件的配置。
hadoop-env.sh
etc/hadoop/hadoop-env.sh 的配置
1 | #修改JAVA_HOME为 /home/app/jdk1.8 |
core-site.xml
etc/hadoop/core-site.xml 的配置
1 | # configuration元素的配置 |
由于配置了hadoop运行产生的文件存放的位置是/home/app/data/tmp,所以要创建此文件夹。
hdfs-site.xml
etc/hadoop/hdfs-site.xml 的配置
1 | <configuration> |
看到这里namenode和datanode的文件存放地方,所以我们要提前mkdir这个对应的文件夹。
在namenode的主机(在哪台主机运行bin/hdfs namenode -format哪台就是namenode)创建/home/app/data/name和/home/app/data/data和/home/app/data/tmp 3个文件。
在5台datanode创建:/home/app/data/data和/home/app/data/tmp2个文件。
yarn-site.xml
etc/hadoop/yarn-site.xml 的配置
1 | <configuration> |
etc/hadoop/yarn-env.sh 的配置
1 | #修改JAVA_HOME 为 /home/app/jdk1.8 |
mapred-site.xml
将 etc/hadoop/mapred-site.xml.template改为etc/hadoop/mapred-site.xml,然后配置
1 | <configuration> |
slaves
配置datanode有哪些, vi etc/hadoop/slaves
1 | hadoop01 |
说明5个主机都是namenode。
hosts
在etc/hosts中配置5台虚拟机的名字与ip的映射关系。追加
1 | 192.168.137.101 hadoop01 |
拷贝到所有主机
将hadoop01拷贝到hadoop02-05:在VMware/hadoop01(右击)/管理/克隆。然后在hadoop02-05更改相关的配置:/etc/sysconfig/network,/etc/sysconfig/network-scripts/ifcfg-ens33,/etc/hostname,都是修改主机名和IP地址。
ssh免密登录
为了使虚拟机之间,顺利通信,需要设置ssh免密登录,表现就是在第一次配置的时候需要输入每个主机的密码,但是之后就不需要了。
由于在5台虚拟机上配置ssh的操作完全一样,所有我们打开secureCRT,连接到所有主机,然后在下面的空白板右击,选择发送到所有会话,然后就可以在下面写命令,然后所有虚拟机都执行。
1 | ssh-keygen #生成公钥和私钥 |
cd ~/.ssh ls 可以看到下面的文件:
1 | authorized keys #可以登录的机器名 |
ssh 192.168.137.102或者ssh hadoop02 可以登录到hadoop02
scp [要发送的文件地址] [ip | 主机名]:文件夹地址
发送文件到另外一台主机
启动
接下来,启动hdfs集群,在hadoop01的/home/app/hadoop-2.7.2下:
1 | bin/hdfs namenode -format #在哪台虚拟机上运行,哪台虚拟机就是namenode |
这样的话,namenode和datanode就在所有虚拟机上的对应主机启动起来了,虽然只在hadoop01运行了上述命令,但是影响到了全部5个主机,因为配置文件制定5个虚拟机要干什么,然后通过虚拟机主机名找到ip地址,然后通过ssh与其他主机通信,打开对应的进程。
由于在yarn-site.xml中配置了hadoop02是resource manager,所以,在hadoop02那里运行
1 | sbin/start-yarn.sh |
这样,resource manager和node manager就在5台虚拟机的对应主机上启动了。
在每台主机上输入下面的命令,可以看到哪些进程在运行。比如,hadoop01就应该有namenode, datanode, node manager, 在hadoop02上就应该有datanode, node manager, resource manager
1 | jps |
在windows下的浏览器那里输入:
1 | 192.168.137.101:50070 |
可以查看hdfs的运行情况。
hadoop分布式配置
与伪分布式配置完全一样,但是由于要5台不同主机上的虚拟机进行通信,所以不能使用NAT网络连接模式,因为你不能从一个内网ping另一个内网,因此要配置虚拟机为桥接网络连接模式,然后对应地更改相关配置。
运行mapreduce项目
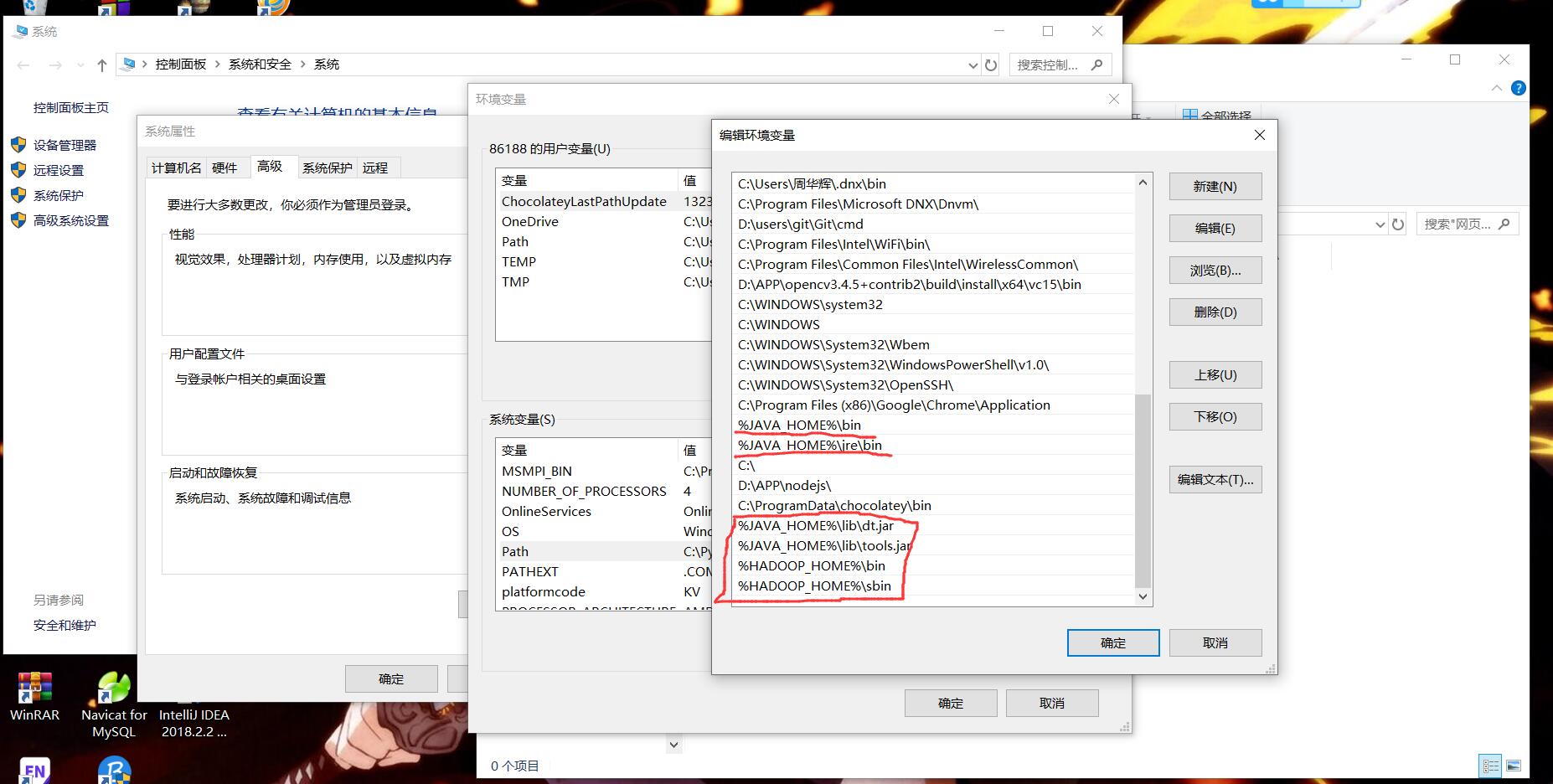
环境
windows下安装jdk1.8.0_144和hadoop-2.7.2的windows10下编译好的包。然后配置JAVA_HOME和HADOOP_HOME,以及一些环境变量。

IntelliJ IDEA
安装IntelliJ IDEA。


在IDEA上创建maven项目,如上图所示,后面自己起个项目名字,如SNS。然后在右下角点击enable auto import。


然后编写pom.xml,pom.xml在/SNS/下,/SNS/下面还有.idea,src,targe,SNS.iml。pom.xml是为了指定
1 |
|
由于上面点击了enble auto import,然后又在pom.xml里面指定了一些hadoop的包,然后IDEA就可以自动从maven上下载相应的hadoop包,等待一会就好了。
wordcount程序

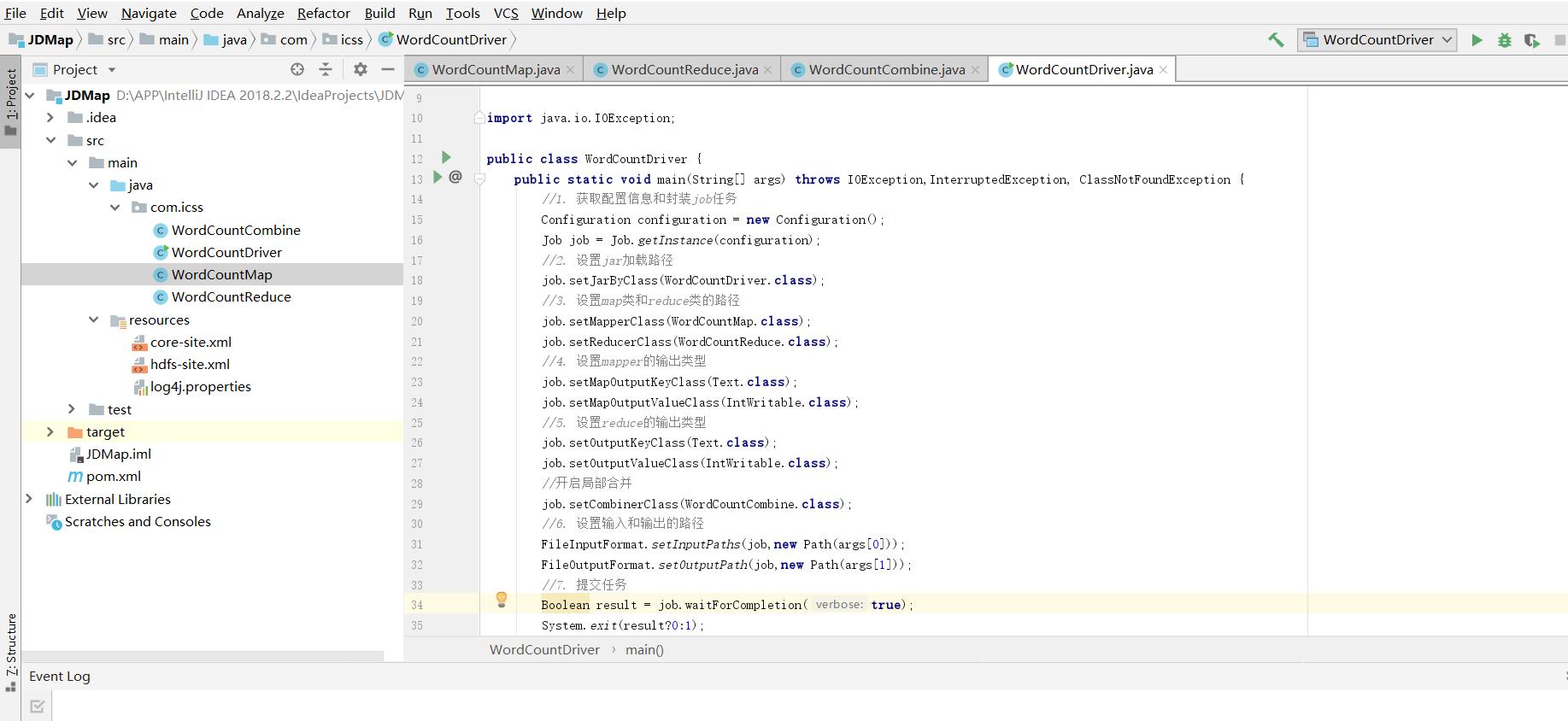
上面是这个IDEA maven项目的大致结构,但是我不知道这些resources里面的文件是干嘛的。下面是所有程序。
1 | //WordCountMap |
1 | //WordCountCombine |
1 | //WordCountReduce |
1 | //WordCountDriver |
1 | <--core-site.xml--> |
1 | <---hdfs-site.xml--> |
log4j.properties
1 | log4j.rootLogger=INFO,stdout |
为了运行这个mapreduce代码,要制定输入参数,也就是main函数的参数,在通过下面的方式指定。两个参数分别是输入文件和输出文件夹地址,这两个都是hadoop01虚拟机底下的文件夹,注意:输入文件夹里面不能有文件夹,只能有文件。

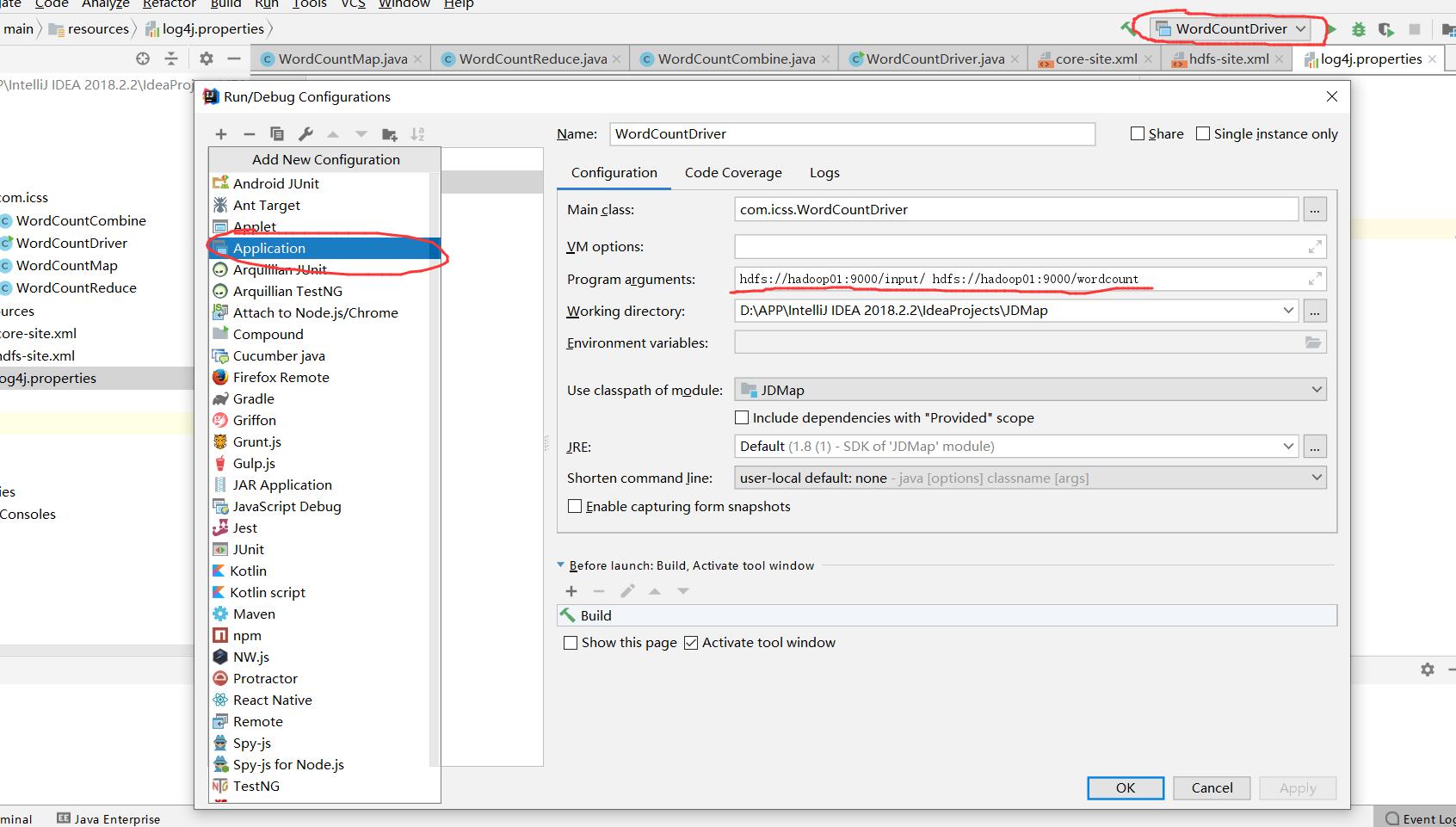
我们已经打开了所有的虚拟机的datanode, namenode, 各种manager,已经配置好了IDEA maven项目,然后在上面的输入文件夹里面加入一些文件,比如/input/word.txt,就可以运行这个项目了,可以在/wordcount/里面产生part-t-00000文件,里面是结果。
查看结果
可以在hadoop01虚拟机里的/home/app/hadoop-2.7.2/下运行:
1 | bin/hdfs dfs -cat hdfs://dadoop01:9000/wordcount/part-r-00000 |
就可以查看wordcount结果。在这里,我们也可以看到hdfs命令与linux命令基本一致,如hdfs dfs -cat和 cat。