
目录结构
- aclocal.m4:config 用的文件的一部分
- config/:config 用的文件的目录
- config.log:
- configure:configure 文件
- configure.in:configure 文件的雏形
- contrib/:contribution 程序
- COPYRIGHT:版权信息
- doc/:文档目录
- GUNMakefile:第一级目录的 Makefile
- GUNMakefile.in:Makefile 的雏形
- HISTORY:修改历史
- INSTALL:安装方法简要说明
- Makefile:Makefile模版
- README:简单说明
- src/:源代码目录
src/的源码目录:
- backend/:后端的源码目录
- include/:头文件,backend等的代码的头文件包含在include里面。其组织虽然与backend的目录结构类似,但是并非完全相同,基本上来说下一级的子目录不再设下一级目录。
- common/:通用库代码
- bin/:psql 等 UNIX命令工具的代码
- pl/:存储过程语言的代码
- port/:平台移植相关的代码
- template/:平台相关的设置值
- test/:各种测试脚本
- timezone/:时区相关代码
- tools/:各自开发工具和文档
- tutorial/:教程
- fe_utils/:通用工具
- interfaces/:前端相关的库的代码
- Makefile:Makefile
- Makefile.global:make 的设定值(从configure生成的)
- Makefile.global.in:Configure使用的Makefile.global的雏形
- Makefile.shlib:共享库用的Makefile
- nls-global.mk:信息目录用的Makefile文件的规则
- DEVELOPERS:面向开发人员的注释
src/backend/源码目录:
- access/:各种存储访问方法(在各个子目录下) common(共同函数)、gin (Generalized Inverted Index通用逆向索引)、gist (Generalized Search Tree通用索引)、 hash (哈希索引)、heap (heap的访问方法)、index (通用索引函数)、 nbtree (Btree函数)、transam (事务处理)
- bootstrap/:数据库的初始化处理(initdb的时候)
- catalog/:系统目录,系统表操作
- commands/:SELECT/INSERT/UPDATE/DELETE以为的SQL文的处理
- common.mk:
- executor/:执行器(访问的执行)
- foreign/:FDW(Foreign Data Wrapper)处理
- lib/:共同函数
- libpq/:C/C++库函数,处理与客户端间的通信,几乎所有的模块都依赖它。
- main/:主程序模块,负责将控制权转到Postmaster进程或Postgres进程。
- Makefile: makefile
- nodes/:构文树节点相关的处理函数
- optimizer/:优化器
- parser/:SQL构文解析器
- po/: 语言文件配置
- port/:平台相关的代码
- postmaster/:postmaster的主函数 (常驻postgres)
- regex/:正则处理
- replication/:streaming replication
- rewrite/:规则及视图相关的重写处理
- snowball/:全文检索相关(语干处理)
- storage/: 共享内存、磁盘上的存储、缓存等全部一次/二次记录管理(以下的目录)、buffer/(缓存管理)、 file/(文件)、freespace/(Fee Space Map管理)、 ipc/(进程间通信)、large_object /(大对象的访问函数)、 lmgr/(锁管理)、page/(页面访问相关函数)、 smgr/(存储管理器)
- tcop/:postgres (数据库引擎的进程)的主要部分,它调用Parse,Optimizer,Executor和Commands
- tsearch/:全文检索
- utils/ 各种模块(以下目录) adt/(嵌入的数据类型)、cache/(缓存管理)、 error/(错误处理)、fmgr/(函数管理)、hash/(hash函数)、 init/(数据库初始化、postgres的初期处理)、 mb/(多字节文字处理)、misc/(其他)、mmgr/(内存的管理函数)、 resowner/(查询处理中的数据(buffer pin及表锁)的管理)、sort/(排序处理)、time/(事务的 MVCC 管理)
在/src/bin下面还有一些有用的模块:
- psql:数据库交互工作
- initdb:初始化数据库集簇
Postgres架构
PostgreSQL数据库是一种极好可以运行在各种平台上的免费的开放源码的对象关系数据库,它是一种以关系数据库和SQL为基础,扩展了抽象数据类型,从而具备面向对象特性的数据库。

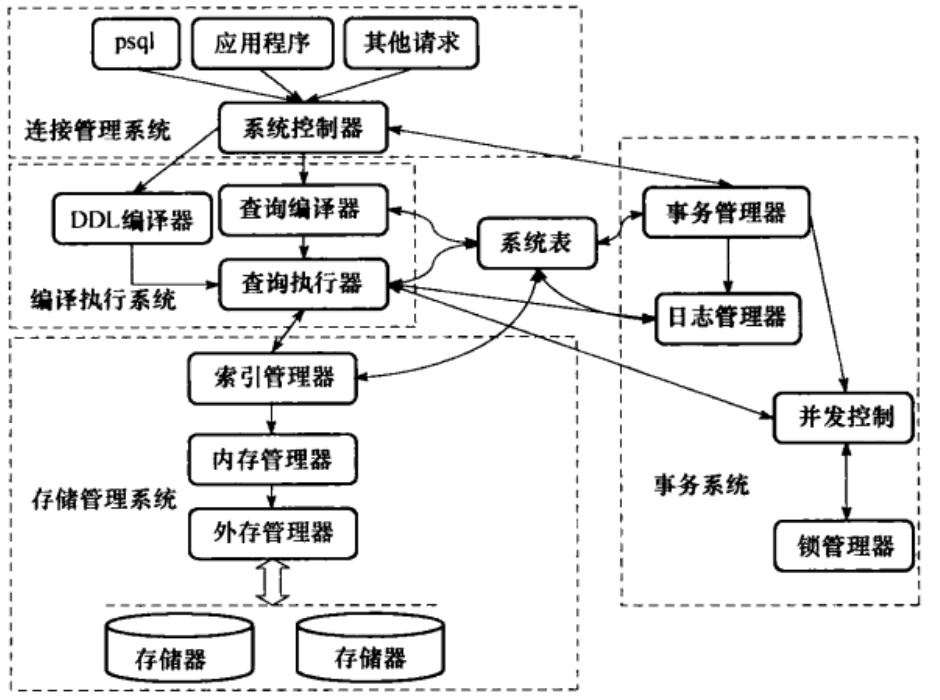
PostgreSQL由连接管理系统(系统控制器),编译执行系统,存储管理系统,事务系统,系统表五大部分组成。
连接管理系统接受外部操作对系统的请求,对操作请求进行预处理和分发,起系统逻辑控制作用;
编译执行系统由查询编译器,查询执行器组成,完成操作请求在数据库中的分析处理和转化工作,最终实现物理存储介质中数据的操作;
存储管理系统由索引管理器,内存管理器,外存管理器组成,负责存储和管理物理数据,提供对编译查询系统的支持;
事务系统由事务管理器,日志管理器,并发控制,锁管理器组成,日志管理器和事务管理器完成对操作请求的事务一致性支持,锁管理器和并发控制提供对并发访问数据的一致性支持;
系统表是PostgreSQL数据库的元信息管理中心,包括数据库对象信息和数据库管理控制信息。系统表管理元数据信息,将PostgreSQL数据库的各个模块有机地连接在一起,形成一个高效的数据管理系统。
系统表是PostgreSQL数据库存放结构元数据的地方,他在PostgreSQL中表现为存放有系统信息的普通表或者视图(用户可以删除,重建)。
系统表保存了数据库的所有元数据,所以系统运行时对系统表的访问是非常频繁的。为了提高系统性能,在内存中建立了共享的系统表,使用Hash表提高查询效率。
主要系统表功能
1 pg_namespace 存储命名空间
2 pg_tablespace 存储表空间信息
3 pg_database 存储当前数据集簇中数据库的信息。
4 pg_class 存储表及与表类似结构的数据库对象信息,包含,索引,序列,视图,复合数据类型,TOAST表等。
5 pg_type 存储数据类型信息。
6 pg_attribute 存储表的属性信息。
7 pg_index 存储索引的具体信息。
PostgreSQL数据库系统的主要功能都集中于Main模块中的main函数,在初始化数据库集簇,启动数据库服务器时,都将从这里开始执行。Main模块主要的工作是确定当前的操作系统平台,并据此做一些平台相关的环境变量设置和初始化,然后通过对命令行参数的判断,将控制转到相应的模块中去。下图是main函数的调用流程。
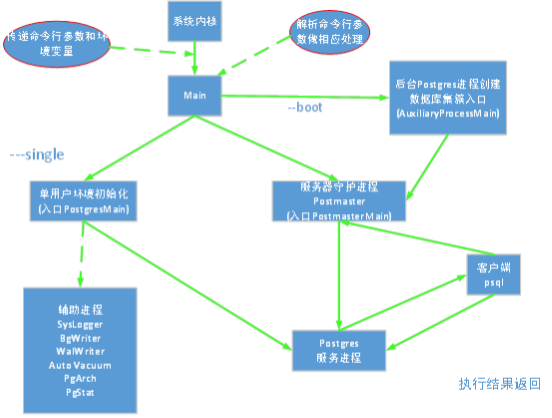
PostgreSQL守护进程Postmaster为用户连接请求分配后台(background)Postgres服务进程,还将启动相关的后端(backend)服务进程:SysLogger(系统日志进程),PgStat(统计数据收集进程)等。
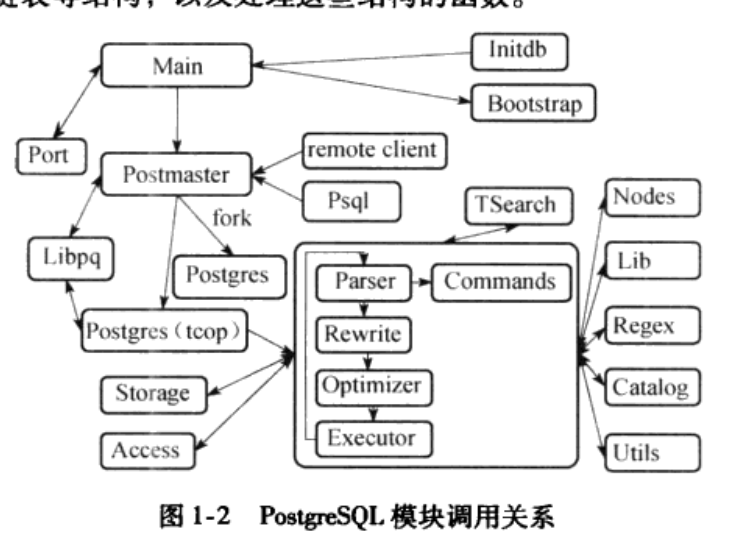
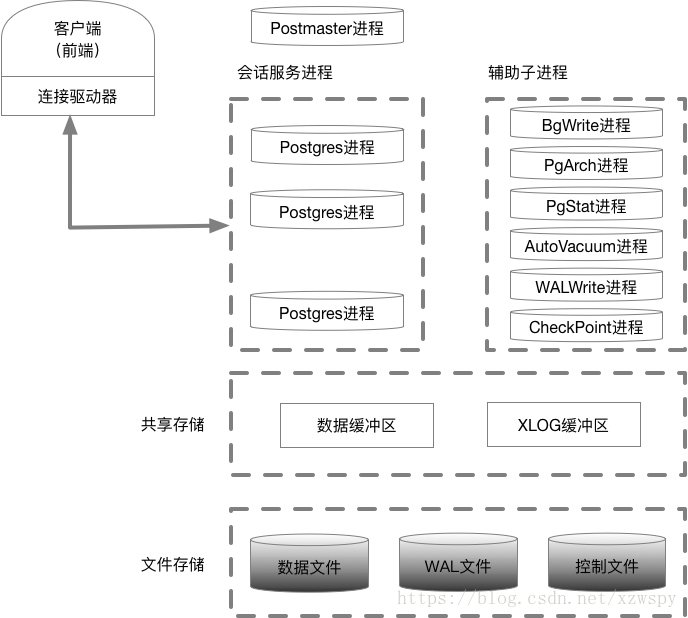
下图为PG 8.0中各个文件夹(模块)之间的调用关系:

下图是PostgreSQL的后台流程图:

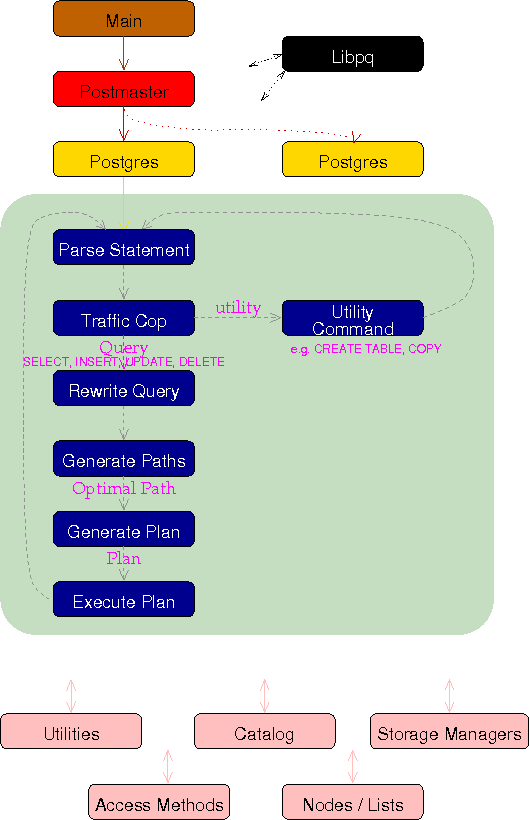
用户调用接口库(ODBC, libpq)把用户请求通过网络发送给Postmaster。
PostgreSQL的物理架构非常简单,它由共享内存、一系列后台进程和数据文件组成。 (如下图)

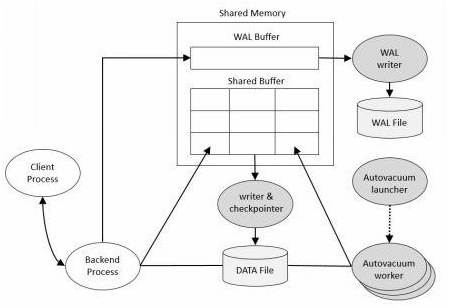

Memory Architecture
【1】中有很好的图

共享内存是服务器服务器为数据库缓存和事务日志缓存预留的内存缓存空间。其中最重要的组成部分是Shared Buffer和WAL Buffer。
Shared Buffer
Shared Buffer的目的是减少磁盘IO。为了达到这个目的,必须满足以下规则:
- 当需要快速访问非常大的缓存时(10G、100G等)
- 如果有很多用户同时使用缓存,需要将内容尽量缩小
- 频繁访问的磁盘块必须长期放在缓存中
WAL Buffer
WAL Buffer是用来临时存储数据库变化的缓存区域。存储在WAL Buffer(Write-ahead log)中的内容会根据提前定义好的时间点参数要求写入到磁盘的WAL文件中。在备份和恢复的场景下,WAL Buffer和WAL文件是极其重要的。
Clog
【1】Commit Log(CLOG) keeps the states of all transactions (e.g., in_progress,committed,aborted) for Concurrency Control (CC) mechanism.
Postgres进程类型
在【1】官网上有很重要的一句话:A collection of multiple processes cooperatively managing one database cluster is usually referred to as a ‘PostgreSQL server’

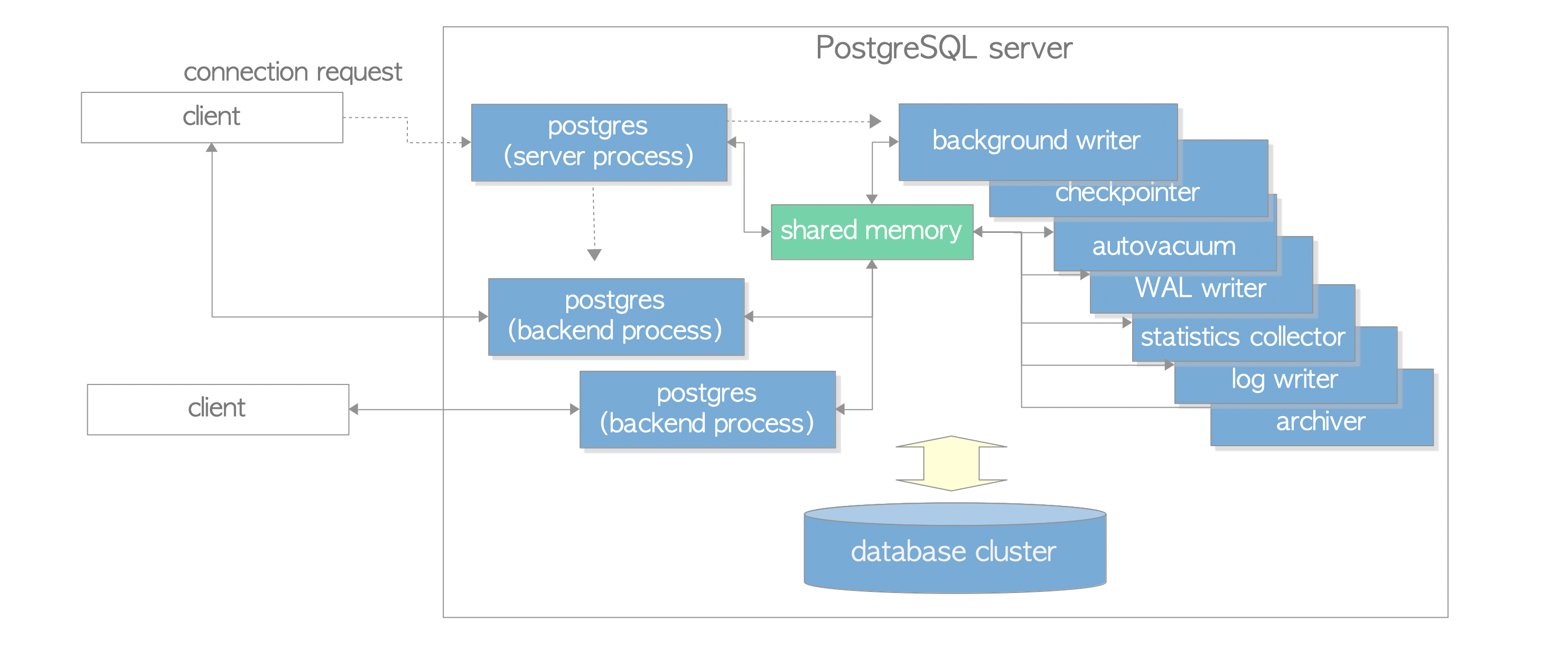
- A postgres server process is a parent of all processes related to a database cluster management.
- Each backend process handles all queries and statements issued by a connected client.
- Various background processes perform processes of each feature (e.g., VACUUM and CHECKPOINT processes) for database management.
- In the replication associated processes, they perform the streaming replication. The details are described in Chapter 11.
- In the background worker process supported from version 9.3, it can perform any processing implemented by users. As not going into detail here, refer to the official document.
PostgreSQL有四种进程类型
- Postmaster (Daemon) Process(主后台驻留进程)
- Background Process(后台进程)
- Backend Process(后端进程)
- Client Process(客户端进程)
Postmaster Process
主后台驻留进程是PostgreSQL启动时第一个启动的进程。启动时,他会执行恢复、初始化共享内存。正常服役期间,当有客户端发起链接请求时,它还负责创建后端进程。用户可以通过postmaster,postgres或者pg_ctl命令启动Postmaster。
管理后端的常驻进程,也称为’postmaster’。其默认监听UNIXDomain Socket和TCP/IP(Windows等,一部分的平台只监听tcp/ip)的5432端口,等待来自前端的的连接处理。监听的端口号可以在PostgreSQL的设置文件postgresql.conf里面可以改。
一旦有前端连接过来,Postmaster会根据连接的起始消息对客户端的身份进行验证。验证通过后,postgres会通过fork生成子进程。没有Fork的windows平台的话,则利用createProcess()生成新的进程。这种情形的话,和fork不同的是,父进程的数据不会被继承过来,所以需要利用共享内存把父进程的数据继承过来。
如果通过pstree命令查看进程之间的关系,你会发现Postmaster进程是其他所有进程的父进程。


Postmaster除了接收客户的消息,还有如下功能:
- 管理整个系统范围的操作,例如中断操作,并指派一个合适的子进程区处理它们;
- 在起始时建立共享内存和信号库;
在/src/backend/postmaster文件夹下,包含下列文件:
- postmaster进程源文件 postmaster.c
- 统计数据收集进程的源文件 pqstat.c
- 预写式日志归档进程的源文件 pgarch.c
- 后台写进程的源文件 bgwrite.c
- 系统日志进程的源文件 syslogger.c
- 系统自动清理进程的源文件 autovacuum.c
初始化内存上下文
调用MemoryContextInt()函数创建TopMemoryContext和ErrorContext,然后调用AllocSetContextCreate()函数以TopMemoryContext为根结点创建PostmasterContext,最后将全局指针CurrentMemoryContext指向PostmasterContext。
配置GUC参数
在初始化内存环境之后,需要配置Postmaster运行时所需的各种参数。
由GucContext定义的参数的六种类型
- PGC_INTERNAL: 参数只能内部进程定义
- PGC_POSTMASTER:参数只能在Postmaster通过读取配置文件和用户命令行来进行配置
- PGC_SIGHUP: 参数只能在postmaster启动时配置,或者改变了数据文件并发送信号SIGHUP通知Postmaster或Postgres的时候进行配置
- PGC_BACKEND: 参数只能在启动时读配置文件设置,或由客户端进行连接请求时设置。已经启动的后台进程将忽略此类参数的改变
- PGC_USERSET: 可以在任何时候配置
- PGC_SUSET: 参数只能在启动时配置或由超级用户通过SQL语言(SET命令)进行设置
描述参数来源
1 | typedef enum{ |
每一种数据类型的GUC参数都由共性部分和特性部分组成。共性部分由config_generic结构体定义;参数类型config_type是个enum类型,有五种:PGC_BOOL, PGC_INT, PGC_REAL, PGC_STRING和PGC_ENUM。
postmaster配置参数的基本操作是:
- 初始化GUC参数。涉及到
build_guc_variables(),initializeGUCOptions(),系统调用getenv(),SetConfigOption() - 配置GUC参数。postmaster解析命令行并进行配置,设计
getopt()和SetConfigOption() - 读取配置文件。配置文件中的参数不能覆盖之前通过命令行设置的参数。涉及到
SelectConfigFiles()
创建监听套接字
主要数据结构:
- ListenAddresses
- ListenSocket[MAXLISTEN]
- struct addrinfo:
getaddrinfo()函数返回与协议无关的套接字时需要关心的信息,如IP,端口等。
使用SplitIdentifierString()解析ListenAddress;调用StreamServerPort()在服务器地址上创建监听套接口,并将套接字描述符保存在ListenSocket[]中;之后会依次调用Socket(),bind(), listen()系统函数;之后reset_shared()创建用于进程间通信的共享内存和信号量;在这之后装载用户认证文件pg_hba.conf和pg_ident.conf,初始化BackendList后台进程双向链表。
注册信号处理函数
信号由一个进程发送给另外一个进程。Postmaster定义了三个信号集:BlockSig, UnBlockSig, AuthBlockSig。PG_SETMASK()用于屏蔽所有信号,在设置信号处理函数时使用;pqsignal()注册某个信号的处理函数。
辅助进程启动
这里面提到非阻塞IO模式
选项标志变量autovacuum_start_daemon根据GUC配置进行设置,值为真表示autovacuum启动;track_counts是一个GUC选项,标志PgStat是否会进行统计信息的收集。
装载客户端认证文件
其中,pg_hba.conf是基于主机认证的配置文件;pg_ident.conf是基于身份认证的配置文件。
循环等待客户端连接
服务进程是Postgres;客户端进程可以是psql进程。
流程是:
- Postmaster调用
ServerLoop()来循环等待客户端的连接请求; - 其中,调用
initMasks()来初始化Postmaster所关心的读文件描述符集; - 接下来,进入死循环当中,调用
select系统函数等待客户端提出连接请求; - 调用
select()系统函数正常返回后,说明ListenSocket[]中有监听套接字有用户连接请求,接着调用ConnCreate()在CurrentContextMemory内存上下文中创建struct Port结构体; - 调用
BackendStartup()启动后台进程接替Postmaster与用户进行连接,这时Postmaster关闭与用户的连接,释放Port结构体; - 调用
BackendStartup()根据Port结构体来启动一个Postgres进程:首先调用PostmasterRandom()为即将创建的子进程生成一个随机数,并分配一个struct Backend结构 - Postgres进程调用
BackendInitialize()获取用户端的相关信息,填写port结构体,调用ClientAuthentication()进行用户认证,调用BackendRun()来设置postgres运行时的命令行参数,调用PostgresMain()进入到Postgres的执行入口。 - 父进程将随机数和子进程pid填入Backend结构中,在把Backend加入到
BackendList链表中,进行管理。
Backend Process
【1】中有很重要的一段化:If many clients such as WEB applications frequently repeat the connection and disconnection with a PostgreSQL server, it increases both costs of establishing connections and of creating backend processes because PostgreSQL has not implemented a native connection pooling feature. Such circumstance has a negative effect on the performance of database server. To deal with such a case, a pooling middleware (either pgbouncer or pgpool-II) is usually used.
Background Process
PostgreSQL操作需要的后台进程列表如下:
| 进程 | 作用 |
|---|---|
| logger | 将错误信息写到log日志中 |
| checkpointer | 当检查点出现时,将脏内存块写到数据文件 |
| writer | 周期性的将脏内存块写入文件 |
| wal writer | 将WAL缓存写入WAL文件 |
| Autovacuum launcher | 当自动vacuum被启用时,用来派生autovacuum工作进程。autovacuum进程的作用是在需要时自动对膨胀表执行vacuum操作。 |
| archiver | 在归档模式下时,复制WAL文件到特定的路径下。 |
| stats collector | 用来收集数据库统计信息,例如会话执行信息统计(使用pg_stat_activity视图)和表使用信息统计(pg_stat_all_tables视图) |
Background Writer process
- Writer process在适当的时间点把共享内存上的缓存写往磁盘。通过这个进程,可以防止在检查点的时候(checkpoint),大量的往磁盘写而导致性能恶化,使得服务器可以保持比较稳定的性能。Background writer起来以后就一直常驻内存,但是并非一直在工作,它会在工作一段时间后进行休眠,休眠的时间间隔通过
postgresql.conf里面的参数bgwriter_delay设置,默认是200微秒。 - 这个进程的另外一个重要的功能是定期执行检查点(checkpoint)。检查点的时候,会把共享内存上的缓存内容往数据库文件写,使得内存和文件的状态一致。通过这样,可以在系统崩溃的时候可以缩短从WAL恢复的时间,另外也可以防止WAL无限的增长。 可以通过
postgresql.conf的checkpoint_segments、checkpoint_timeout指定执行检查点的时间间隔。
Writer进程是把共享内存中的脏页写到磁盘上的进程。它的作用有两个:一是定期把脏数据从内存缓冲区刷出到磁盘中,减少查询时的阻塞;二是PG在定期作检查点时需要把所有脏页写出到磁盘,通过BgWriter预先写出一些脏页,可以减少设置检查点(CheckPoint,数据库恢复技术的一种)时要进行的IO操作,使系统的IO负载趋向平稳。BgWriter是PostgreSQL8.0以后新加的特性,它的机制可以通过postgresql.conf文件中以”bgwriter_”开头配置参数来控制。

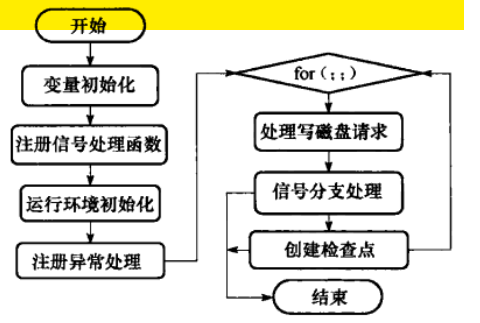
有关BgWriter的参数在postgres.conf中定义了一些:bgwriter_delay,bgwriter_lru_maxpages,bgwriter_lru_multiplier。在BgWriter中每隔bgwriter_delay时间可能不会写脏页(一般写脏页),因为检查到需要创建检查点,这时就不要写脏页了,处理“创建检查点”的工作,详情在后面。
- 变量初始化:定义局部变量,完成部分全局变量的赋值操作。(什么是全局变量,是所有进程共享的变量吗?)
- 注册信号处理函数:在信号处理函数中设置一些位:比如
got_SIGHUP,checkpoint_requested,shutdown_requested。这些位在后面的“处理信号分支”中要处理。 - 运行环境初始化:通过
ResourceOwnerCreate()创建一个名为Background Writer的资源跟踪器,然后为BgWriter创建运行上下文,并切换到它。 - 注册异常处理:结合系统调用
setjmp()和longjmp()完成异常处理. - 处理写磁盘请求:调用
AbsorbFsyncRequest(),处理fsync请求队列,将请求发送到本地的SMGR。 - 处理信号分支:每次循环都要检测信号标志变量进行相应处理。比如,
got_SIGHUP为true表示重新读取配置文件。 - 创建检查点。如果没有创建检查点请求或者创建检查点时间间隔未到,就调用
BgBufferSync()写脏页。否则执行创建检查点操作,分为三个阶段:检查点类型设置,执行检查点创建操作,检查检查点是否创建成功。(两种检查点类型:do_checkpoint, do_restartpoint有什么区别)。下面是检查点创建流程:

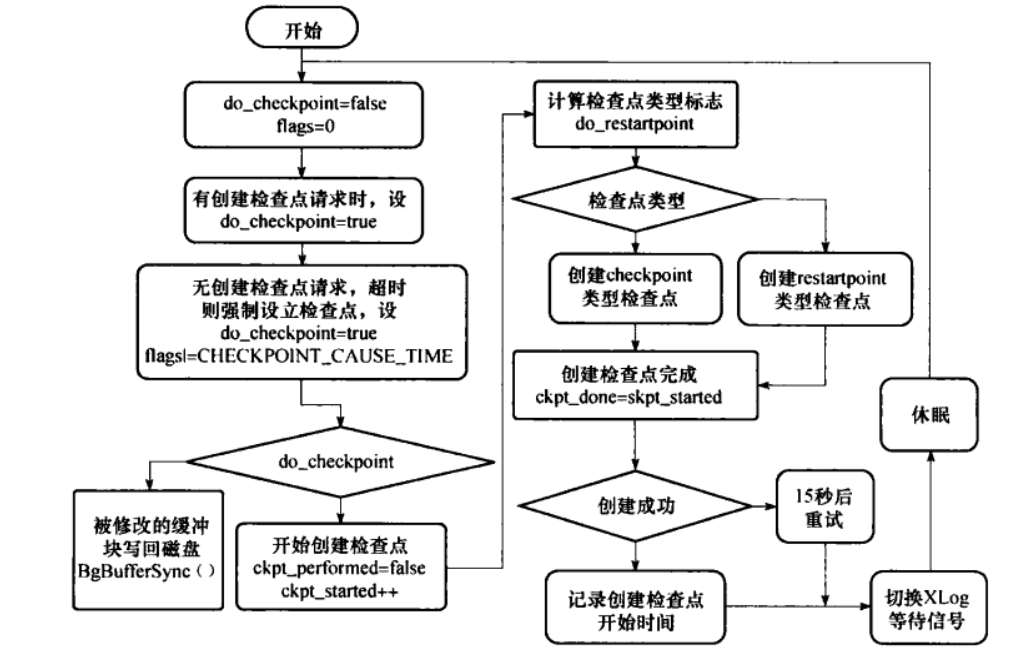
在执行创建检查点阶段,将根据do_restartpoint状态创建检查点或者重启点。在检查点创建后直接设置ckpt_performed为true;而在重启点中将根据创建检查点成功与否标志设置ckpt_performed。
WAL writer process
WAL writer process把共享内存上的WAL缓存在适当的时间点往磁盘写,通过这样,可以减轻后端进程在写自己的WAL缓存时的压力,提高性能。另外,非同步提交设为true的时候,可以保证在一定的时间间隔内,把WAL缓存上的内容写入WAL日志文件。
预写式日志WAL(Write Ahead Log,也称为Xlog)的中心思想是对数据文件的修改必须是只能发生在这些修改已经记录到日志之后,也就是先写日志后写数据(日志先行)。使用这种机制可以避免数据频繁的写入磁盘,可以减少磁盘I/O。数据库在宕机重启后可以运用这些WAL日志来恢复数据库。postgresql.conf文件中与WalWriter进程相关的参数如下:
- wal_level:控制wal存储的级别。wal_level决定有多少信息被写入到WAL中。 默认值是最小的(minimal),其中只写入从崩溃或立即关机中恢复的所需信息。replica 增加 wal 归档信息 同时包括 只读服务器需要的信息。(9.6 中新增,将之前版本的 archive 和 hot_standby 合并)
- logical: 主要用于logical decoding 场景
- fsync:该参数直接控制日志是否先写入磁盘。默认值是ON(先写入),表示更新数据写入磁盘时系统必须等待WAL的写入完成。可以配置该参数为OFF,表示更新数据写入磁盘完全不用等待WAL的写入完成。
- synchronous_commit:参数配置是否等待WAL完成后才返回给用户事务的状态信息。默认值是ON,表明必须等待WAL完成后才返回事务状态信息;配置成OFF能够更快地反馈回事务状态,也就是异步提交。(所以到底是同步提交还是异步提交好呢)
- wal_sync_method:WAL写入磁盘的控制方式,默认值是fsync,可选用值包括open_datasync、fdatasync、fsync_writethrough、fsync、open_sync。open_datasync和open_sync分别表示在打开WAL文件时使用O_DSYNC和O_SYNC标志;fdatasync和fsync分别表示在每次提交时调用fdatasync和fsync函数进行数据写入,两个函数都是把操作系统的磁盘缓存写回磁盘,但前者只写入文件的数据部分,而后者还会同步更新文件的属性;fsync_writethrough表示在每次提交并写回磁盘会保证操作系统磁盘缓存和内存中的内容一致。
- full_page_writes:表明是否将整个page写入WAL。
- wal_buffers:用于存放WAL数据的内存空间大小,系统默认值是64K,该参数还受wal_writer_delay、commit_delay两个参数的影响。
- wal_writer_delay:WalWriter进程的写间隔时间,默认值是200毫秒,如果时间过长可能造成WAL缓冲区的内存不足;时间过短将会引起WAL的不断写入,增加磁盘I/O负担。
- commit_delay:表示一个已经提交的数据在WAL缓冲区中存放的时间,默认值是0毫秒,表示不用延迟;设置为非0值时事务执行commit后不会立即写入WAL中,而仍存放在WAL缓冲区中,等待WalWriter进程周期性地写入磁盘。
- commit_siblings:表示当一个事务发出提交请求时,如果数据库中正在执行的事务数量大于commit_siblings值,则该事务将等待一段时间(commit_delay的值);否则该事务则直接写入WAL。系统默认值是5,该参数还决定了commit_delay的有效性。
- wal_writer_flush_after:当脏数据超过阈值时,会被刷出到磁盘。
使用WAL的好处是
- 显著地减少了写磁盘地次数,因为在日志提交的时候只需要把日志文件刷新到磁盘,而不是事务修改的所有数据文件;
- 在多用户环境里,许多事务的提交可以用日志文件的一次
fsync来完成; - 而且日志文件是顺序写的,因此同步日志的开销远比同步数据块的开销小。
- 它避免了其他服务进程在事务提交时需要同步地写入预写式日志到磁盘,也使得事务提交记录不是在提交时同步地写入磁盘,而是在一个已知的预先设置的时间异步地写入。
- WAL日志存放在数据库集簇($PGDATA/)下的
pg_xlog(现在是pg_wal)目录中,它存储很多段文件,每个不超过16MB。 - xlog.h文件中描述了日志记录头格式。
一个段文件的名字由24个十六进制的字符组成,分为三个部分:时间线,日志文件标号,日志文件的段标号。
默认的WAL缓冲区大小是8个8KB,即64KB。
Archive process
Archive process把WAL日志转移到归档日志里。如果保存了基础备份以及归档日志,即使实在磁盘完全损坏的时候,也可以回复数据库到最新的状态。
类似于Oracle数据库的ARCH归档进程,不同的是ARCH是吧redo log进行归档,PgArch是把WAL日志进行归档。再深入点,WAL日志会被循环使用,也就是说,过去的WAL日志会被新产生的日志覆盖,PgArch进程就是为了在覆盖前把WAL日志备份出来。归档日志的作用是为了数据库能够使用全量备份和备份后产生的归档日志,从而让数据库回到过去的任一时间点。
PgArch进程通过postgresql.conf文件中的如下参数进行
stats collector process
统计信息的收集进程。收集好统计表的访问次数,磁盘的访问次数等信息。收集到的信息除了能被autovaccum利用,还可以给其他数据库管理员作为数据库管理的参考信息。
PgStat进程是PostgreSQL数据库的统计信息收集器,用来收集数据库运行期间的统计信息,如表的增删改次数,数据块的个数,索引的变化等等。收集统计信息主要是为了让优化器做出正确的判断,选择最佳的执行计划。postgresql.conf文件中与PgStat进程相关的参数。
logger process(Syslogger)
把postgresql的活动状态写到日志信息文件(并非事务日志),在指定的时间间隔里面,对日志文件进行rotate.
需要在Postgres.conf中logging_collection设置为on,此时主进程才会启动Syslogger辅助进程。
AutoVacuum launcher
autovacuum launcher process是依赖于postmaster间接autovacuum进程。而其自身是不直接启动autovacuum进程的。通过这样可以提高系统的可靠性。
在PG数据库中,对数据进行UPDATE或者DELETE操作后,数据库不会立即删除旧版本的数据,而是标记为删除状态。这是因为PG数据库具有多版本的机制,如果这些旧版本的数据正在被另外的事务打开,那么暂时保留他们是很有必要的。当事务提交后,旧版本的数据已经没有价值了,数据库需要清理垃圾数据腾出空间,而清理工作就是AutoVacuum进程进行的。postgresql.conf文件中与AutoVacuum进程相关的参数有:
- autovacuum: 是否启动系统自动清理功能,默认是on
- autovacuum_max_workers: 设置系统自动清理工作进程(AutoVacuum Process)的最大数量
- autovacuum_naptime: 设置两次系统自动清理操作之间的间隔
- autovacuum_vacuum_threshold和autovacuum_analyze_threshold: 设置当表上被更新的元组的数量超过这些阈值时分别需要执行vacuum和analyze
- autovacuum_freeze_max_age: 设置需要强制对数据库进行清理的XID上限值
AutoVacuum
autovacuum worker process进程实际执行vacuum的任务。有时候会同时启动多个vacuum进程。
checkpoint
检查点是系统设置的事务序列点,设置检查点保证检查点前的日志信息刷到磁盘中。postgresql.conf文件中与之相关的参数有:m
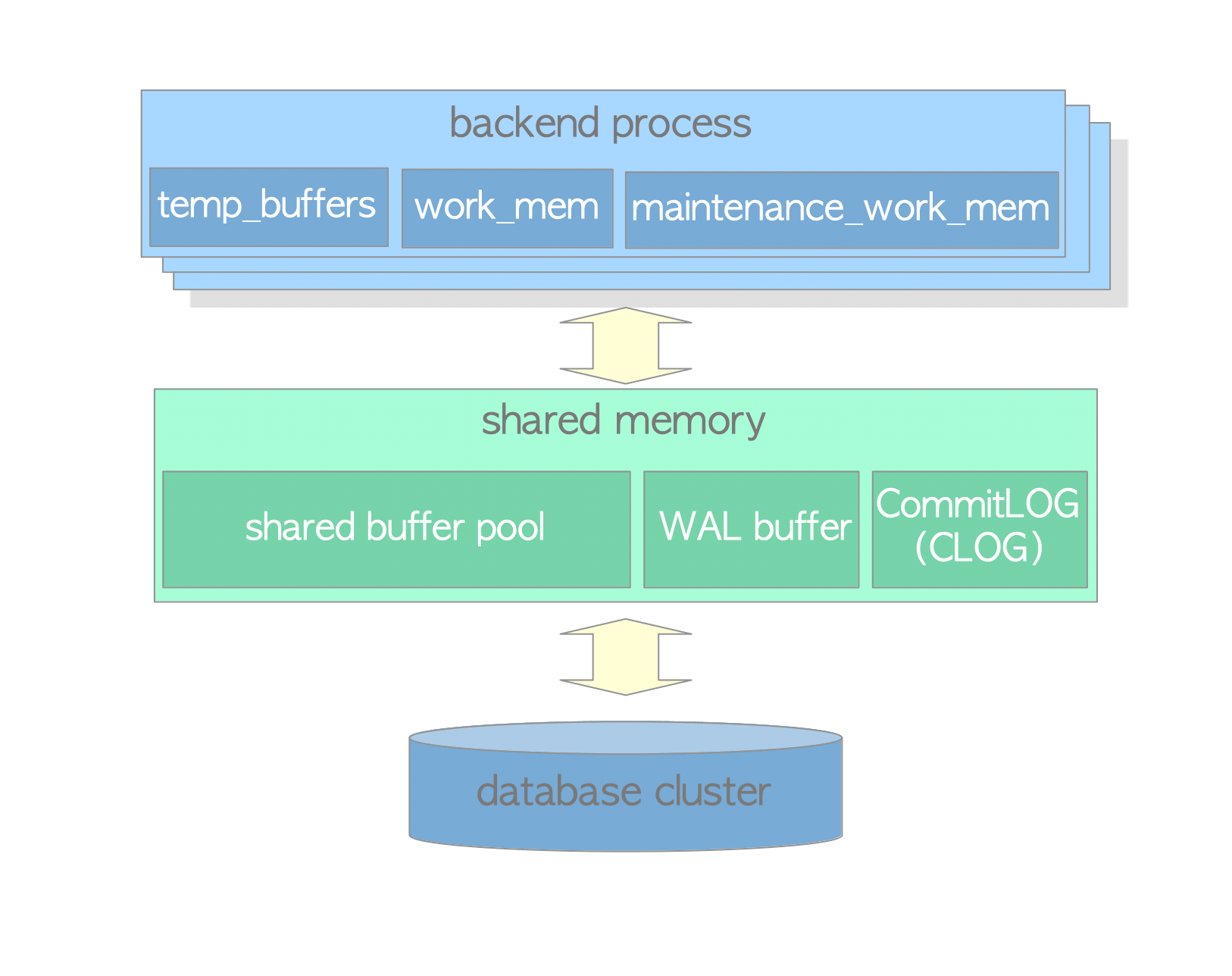
Backend Process(Postgres进程)
最大后台链接数通过max_connections参数设定,默认值为100。后端进程用于处理前端用户请求并返回结果。查询运行时需要一些内存结构,就是所谓的本地内存(local memory)。本地内存涉及的主要参数有:
- work_mem:用于排序、位图索引、哈希链接和合并链接操作。默认值为4MB。
- maintenance_work_mem:用于vacuum和创建索引操作。默认值为64MB。
- temp_buffers:用于临时表。默认值为8MB。
源码位于src/backend/tcop文件夹下:
- postgres.c: Postgres的入口文件,负责管理查询的整体流程
- pquery.c 执行一个分析好的查询命令
- utility.c:对于非查询命令进行处理的
- dest.c:处理Postgres和远端客户的一些消息通信操作,并负责返回命令的执行结果。
数据库结构
想要理解PostgreSQL的数据库结构,需要先了解一些重要的概念。
数据库相关概念:
- PostgreSQL由一系列数据库组成。一套PostgreSQL程序称之为一个数据库群集。
- 当initdb()命令执行后,template0 , template1 , 和postgres数据库被创建。
- template0和template1数据库是创建用户数据库时使用的模版数据库,他们包含系统元数据表。
- initdb刚完成后,template0和template1数据库中的表是一样的。但是template1数据库可以根据用户需要创建对象。
- 用户数据库是通过克隆template1数据库来创建的;
表空间相关概念:
- initdb后马上创建pg_default和pg_global表空间。
- 建表时如果没有指定特定的表空间,表默认被存在pg_default表空间中。
- 用于管理整个数据库集群的表默认被存储在pg_global表空间中。
- pg_default表空间的物理位置为$PGDATA/base目录。
- pg_global表空间的物理位置为$PGDATA/global目录。
- 一个表空间可以被多个数据库同时使用。此时,每一个数据库都会在表空间路径下创建一个新的子路径。
- 创建一个用户表空间会在$PGDATA\pg_tblspc目录下面创建一个软连接,连接到表空间指定的目录位置。
表相关概念:
- 每个表有三个数据文件。
- 一个文件用于存储数据,文件名是表的OID。
- 一个文件用于管理表的空闲空间,文件名是OID_fsm。
- 一个文件用于管理表的块是否可见,文件名是OID_vm。
- 索引没有_vm文件,只有OID和OID_fsm两个文件
其他需要注意的地方
表和索引创建时文件名是OID,此时的OID和pg_class.relfilenode的值是一样的。不管怎样,当我们执行重写操作时(truncate,cluster,vacuum full,reindex等),被修改对象的relfilenode值也会被修改,文件名也会随着reffilenode值一起改变。我们可以通过pg_relation_filepath(‘
数据库集簇的逻辑结构
参考:https://www.cnblogs.com/feishujun/p/PostgreSQLSourceAnalysis_intro01.html
Postgresql的所有数据都存储在数据目录里面,这个数据目录通常会用环境变量PGDATA来引用。
PGDATA中除了表空间pg_default和pg_global的物理目录(PGDATA/base,PGDATA/global)还保存有数据库集簇的配置文件和其他子目录:

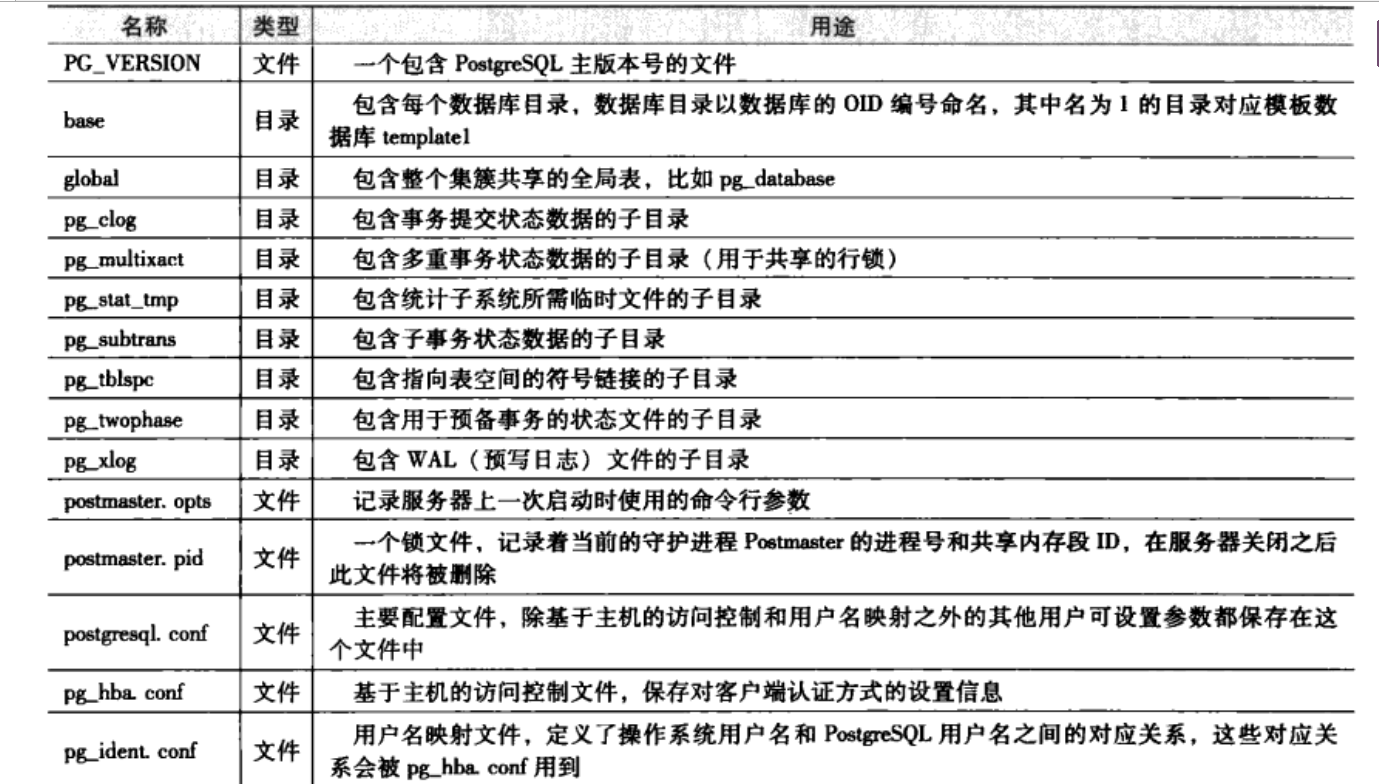
系统表
系统表存储各种数据库对象的元信息,数据库对象可以是数据库,表,元组,索引,表空间等。
系统表由SQL命令关联的系统表操作自动维护系统表信息,比如创建数据库语句会向pg_database系统表中插入一行,并且在磁盘上创建该数据库。
内存中建立了共享的系统表cache,使用Hash函数和Hash表来提高查询效率,因为系统运行时对系统表的访问是非常频繁的。
系统表定义文件和函数实现文件:
- 在
/src/include/catalog下有若干以pg_xxx开头的.h文件,定义了系统表,其中的indexing.h文件定义了所有的系统表索引,toasting.h定义了所有系统表的TOAST表。 - 实现文件在
/src/backend/catalog目录下。
系统表在initdb阶段完成创建。
主要系统表功能
pg_namespace
pg_namespace表中只存储了每个命名空间的名字,所有者的OID以及对该命名空间的访问权限列表,也没有存储明明空间下的所有对象啊。
pg_tablespace
整个集簇范围内共享的系统表,表空间。决定数据库对象的存放位置,比如把一个经常访问的索引访放在/testDir的表空间,并且一个很贵的SSD是挂载在/testDir目录的,那样的话,访问这个索引的性能就提高了。
pg_database
整个集簇范围内共享的系统表。
数据库是定义在某个表空间下的。
pg_database中有一个属性叫做datfrozenxid,类型是TransactionId,所有在这个事务ID之前的事务,都被替换为一个永久冻结的ID,该属性用来跟踪该数据库是否需要进行vacuum操作。
pg_class
存储表,索引,序列,视图,复合数据类型,TOAST表等数据库对象的元信息。
下面列出一些重要的属性的信息。
| 属性名 | 数据类型 | 注释 |
|---|---|---|
| relam | OID | 对于索引对象,该字段显示索引方式的OID,如B-Tree,Hash等 |
| relfilenode | OID | 对象所在的磁盘文件名称 |
| reltablespace | OID | 对象所在的表空间 |
| relpages | int4 | 对象的磁盘页面数,该属性被计划器使用 |
| reltuples | float4 | 表中的元组数 |
| reltoastrelid | OID | 如果关联了TOAST,则表示TOAST表的OID |
| reltoastidxid | OID | 可能存在的TOAST表的索引的OID |
| relhasindex | bool | 该表是否有索引 |
| relkind | char | 数据库对象的类型,r表示表,I表示索引,S表示序列,v表示视图,c表示复合类型,t表示TOAST表 |
| relnatts | int2 | 属性的数目,隐藏属性不包含 |
| relfrozenxid | xid | 所有在这个事务ID之前的事务,都被替换为一个永久冻结的ID,该属性用来跟踪该表是否需要进行vacuum操作。 |
pg_type
该表中每一个元组表示一个数据类型。
| 属性名 | 数据类型 | 注释 |
|---|---|---|
| typstorage | char | 记录变长类型的存储方式,主要用于TOAST技术,这个属性有四种取值:p,e,m,x。分别对应TOAST技术中的四种变长类型的存储策略 |
pg_attribute
存储表的属性信息。数据库中表的每个属性在pg_attribute中都有一个元组
pg_index
inidb
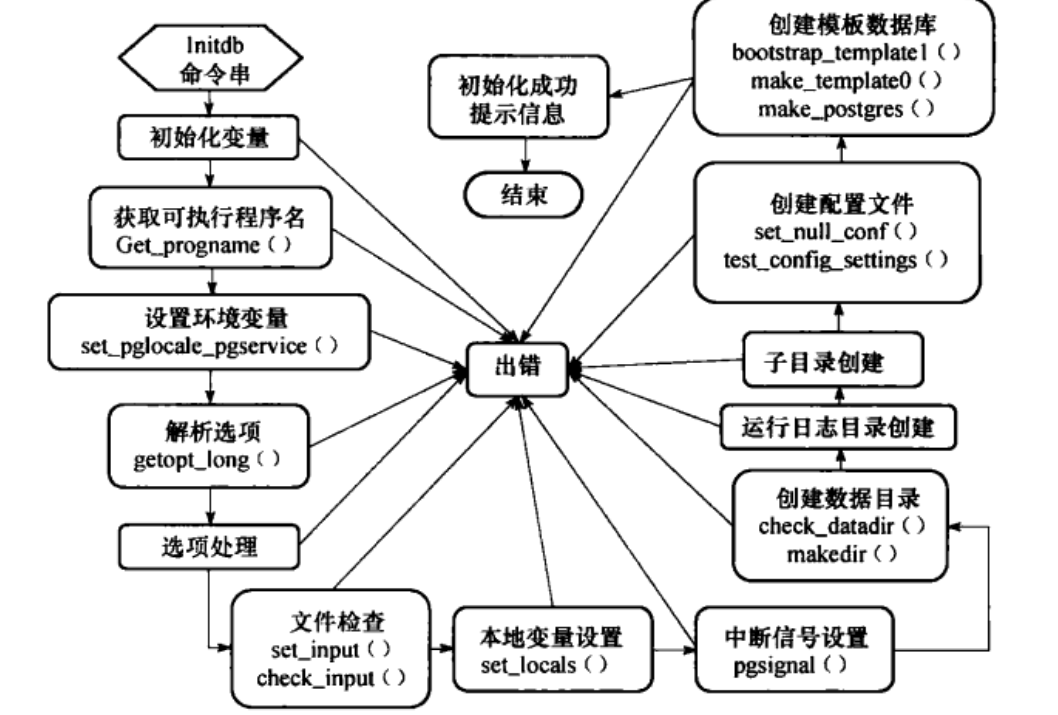
在安装好postgres后,将安装目录下的bin文件夹加入到环境变量中,这个目录中有很多独立的程序。初始化数据库集簇进行初始化,创建模板数据库和系统表,并向系统表中插入初始元组,在这之后,用户创建的各种数据库,表,视图,索引等数据库对象和其他操作,都是在模板数据库和系统表的基础上进行。
postgres.bki
在源代码编译时,genbki.sh脚本(/src/backend/catalog目录下的)读取/src/include/catalog目录下的.h结尾的系统表定义文件创建postgres.bki,并且放在安装树的share子目录下(安装树是不同于PGDATA的另一个目录,编译后的INSTALL阶段会创建该目录)。
在initdb阶段,postgres.bki脚本会被执行,通常是create或insert一些系统关键表。
initdb流程

存储管理

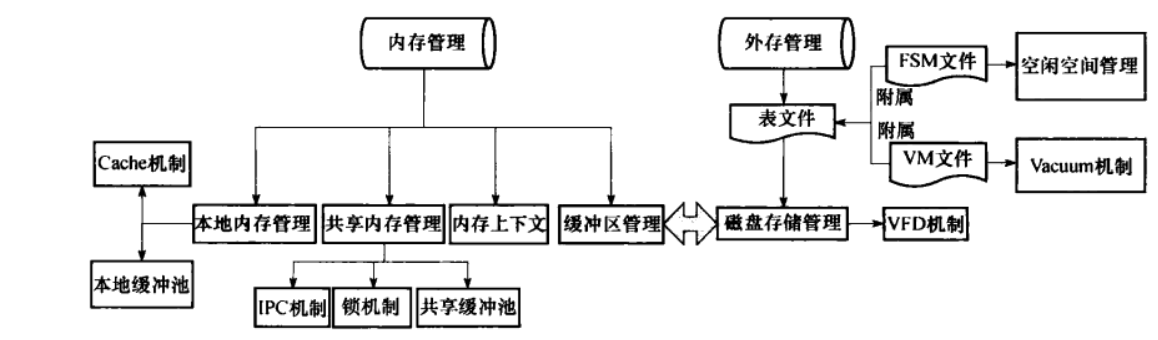
concurrency control
【2】PostgreSQL使用MVCC实现并发控制(Muti-Version Concurrency Control)。
When a transaction reads a data item, the system selects one of the versions to ensure isolation of the individual transaction。The main advantage of MVCC is that readers don’t block writers, and writers don’t block readers。PostgreSQL and some RDBMSs use a variation of MVCC called Snapshot Isolation (SI).
snapshot
【2】 In the READ COMMITTED isolation level, the transaction obtains a snapshot whenever an SQL command is executed; otherwise (REPEATABLE READ or SERIALIZABLE), the transaction only gets a snapshot when the first SQL command is executed。
Write Ahead Logging(WAL)
执行下面的SQL语句
1 | INSERT INTO tbl VALUES ('A'); |
会触发exec_simple_query()函数,下面是这个函数的伪代码
1 | exec_simple_query() @postgres.c |
Page-oriented Log
【3】在明白了XLOG的结构之后,我们就可以来解释什么叫做Page-oriented Log了。从XLOG的信息中,我们不难发现,XLOG描述了一条元组应该被写入到哪个页面的什么位置。从heap_insert的流程中,我们也不难发现,当一条元组写入数据页面后,我们就立即为这次写入操作生成一个XLOG,并写入log buffer。也就是说XLOG描述了页面中的数据变化,这就是Page-oriented Log。与之相对应的是逻辑日志(logic log),逻辑日志通常只是记录一条SQL语句,在redo时,会重新执行这条SQL语句。所以对于Page-oriented Log而言,在redo时元组总是写入到先前写入的那个页面,但对于逻辑日志,redo时的写入就很随意了。
对于Page-oriented Log又分为物理日志和物理逻辑日志两种。前面提到过,对于物理日志会记录元组插入页面中的物理位置(ItemIdData中lp_off的值),而对于物理逻辑日志,只记录元组插入页面中的逻辑位置(ItemIdData自身的偏移)。
对于物理日志而言,由于记录了元组的实际偏移,所以在redo时只用定位到实际位置,然后直接覆盖原有元组(不管元组有没有落盘),这种操作本身是具有幂等性的,不论执行多少次redo结果都一样。但这个方式有一个问题,就是一旦块做了整理(比如:vacuum操作)那么元组的物理位置会发生变化。为了保持精确的物理信息,整理也会产生大量物理日志,这非常影响性能。
所以PostgreSQL采用的是物理逻辑日志,所谓物理是指记录了元组实际插入的数据页,所谓逻辑具体写入到数据页中的什么位置是一个逻辑的值。这样在vacuum的时候只需要保持ItemIdData的位置不变,就没有任何影响。但是物理逻辑日志本身不具有幂等性,如果不加任何处理直接多次redo的话,就会写入多条数据。所以对于物理逻辑日志需要一种手段来判断该XLOG是否需要在对应页面中进行redo操作,这也就是所谓的LSN。这部分内容后面会由专门的文档进行说明。
插入数据源码解读
heap_insert()
在src/backend/access/heap/heapam.c文件中
输入:
- HeapTuple tup是用户要插入的原始数据,不包含tuple头部信息;
1 | 1. heap_prepare_insert() |
构建WAL记录准备(在heap_insert()中写好的):参考【4】。构建后,内存中的XLogRecData链表是什么样:
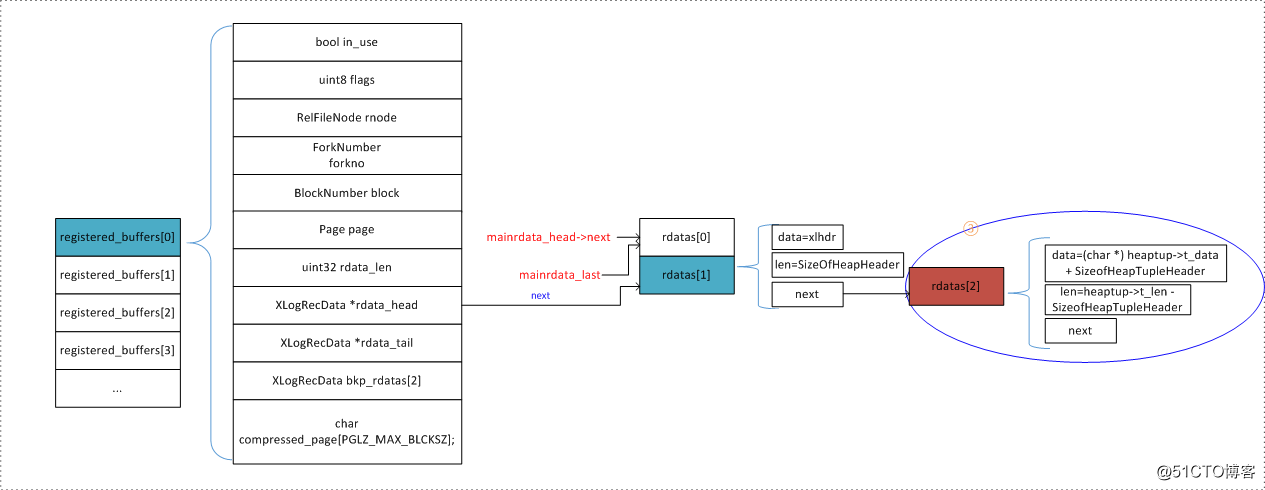
heap_prepare_insert()
把原来的tup里面的数据补充完整,为了之后的元组插入做准备,比如:补充tup的头部信息和toast相关信息
参数:
- TransactionId xid 哪个事务要插入这个tuple
- HeapTuple tup 要插入的tuple,但是只有原始数据,不包含关于头部信息
- options 标志位,比如:指定是否是冻结型插入(什么是冻结型插入?)
- Relation relation 关于要插入的表的模式信息
返回值:
- HeapTuple tup 返回一个准备好的tuple
1 | 1. 暂不支持并行操作; |
RelationGetBufferForTuple()
在src/backend/access/heap/hio.c文件中。
输入:现在是不知道这个tuple应该插入表中的哪个block的,当然也不知道应该插入到共享缓存区中的哪个Buffer;
- Relation relation 要插入的表的模式信息
- Size len 要插入表的长度
- Buffer otherBuffer 见下面的解释
- BulkInsertState bistate 和替换策略有关
- int options 选项:比如是否是冻结型插入,是否使用fsm等
1 | otherBuffer这个参数让人觉得困惑,原因是PG的机制使然 |
1 | Pinned buffers:means buffers are currently being used,it should not be flushed out. |
1 | // hio.h(src/include/access/hio.h) |
1 | 1. 根据otherBuffer判断是不是单纯的insert,不能是update; |
ReadBufferBI()
我们现在知道了blockNumber是什么了,所以可以根据这个来找到对应的Buffer,给这个Buffer增加refcount,并设置bistate的current_buf是这个Buffer。
输入:
- Relation relation
- BlockNumber targetBlock
- BulkInsertState bistate
输出:
- Buffer
1 | 1. if !bistate 如果不是bulk-insert; |
WAL相关源码解读
参考 【3】
XLOG日志的写入其实有两个非常重要的步骤:
- 将XLOG写入log buffer
- 将log buffer中的XLOG落盘
XLog组成
对于XLog日志的物理存储写的很好的文章:PG wal 日志的物理存储分析

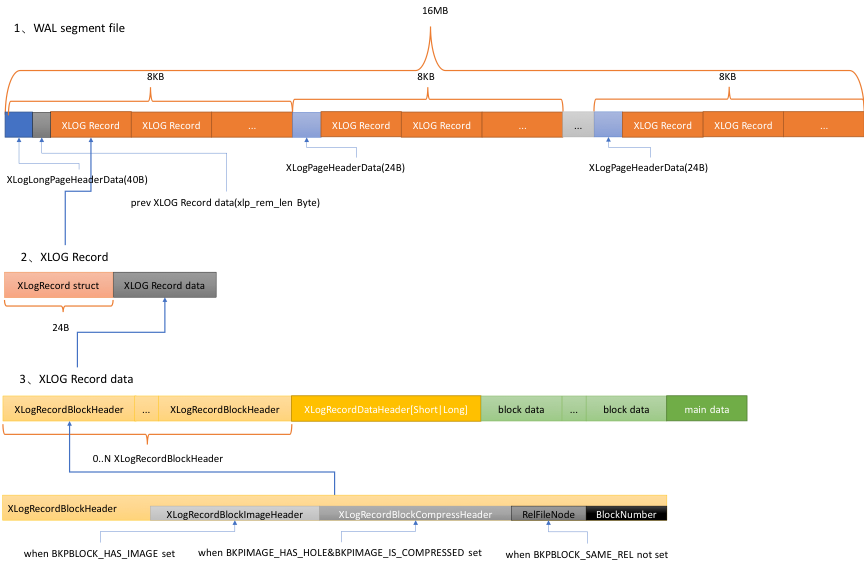
XLog的结构是由以下几个结构体定义的:(参考:【3】)
- struct XLogRecord:XLog的第一个部分,表示XLog头部。
其中,xl_tot_len记录了XLog的总长度;
xl_xid记录产生这个XLog的事务id;
xl_prev表示前一条日志的物理偏移(LSN);
xl_rmid表示资源管理器号,表示当前正在做的是什么操作,当后面恢复的时候就可以调用相应的函数来redo,比如对于insert操作,它的日志的xl_rmid就是RM_HEAP_ID,后面redo时就用heap_redo; - XLogRecordBlockHeader:XLog的第二个部分,称为块头部;
- 紧接着XLogRecordBlockHeader就是RelFileNode和BlockNumber;
- xl_heap_header:XLog的第三个部分的第一部分,存储了heap_tuple的部分头部信息,比如t_infomask2,t_infomask,t_hoff;
- 元组具体数据:XLog的第三个部分的第二个部分;这部分数据和插入元组时写入buffer中的数据完全一样;
- xl_heap_insert:XLog的第四个部分;存储了该元组在物理块中的偏移(是ItemIdData,也即ItemPointer,在页面中的偏移,例如,这个元组在页面中对应第2个ItemPointer,那么在xl_heap_insert中就存储2,而不是元组实体在页面中的偏移);以这种方式记录的日志称为物理逻辑日志;如果记录的是元组实体的偏移,就称为物理日志;
XLogRegister相关函数
XLog在磁盘页中的组织是连续的,比如XLogRecord,然后紧接着存储XLogRecordBlockHeader;但是,在XLog落盘之前,在内存中却不是这么存储的,在内存中是以链表的形式存储;XLogRecData链表链接了XLog的各个部分。
1 | // src/include/access/xlog_internal.h |
XLogRegisterData()
把xl_heap_insert类型的xlrec追加到”main chunk”中
1 | struct xl_heap_insert{ |
1 | /* src/backend/access/transam/xloginsert.c/XLogRegisterData() |
有些注意点:
- rdatas:rdatas数组是为了防止频繁分配和释放空间带来的性能开销,在进程初始化时,又调用InitXLogInsert() 预先分配的一个数组(所以,rdatas可能是在local buffer中的)。在实际使用时,需要注册的数据个数,大于数组大小,则直接报错。
- mainrdata链表:调用XLogRegisterData() 注册的数据,会被链接到mainrdata链表中。mainrdata_len表示mainrdata链表上所有数据的总长度。
XLogRegisterBuffer()
我们不难发现在调用XLogRegisterBufData注册xl_heap_header和元组具体数据之前,先调用了XLogRegisterBuffer。
1 | // src/backend/access/transam/xloginsert.c/XLogRegisterBuffer() |
XLogRegisterBufData()
1 | // src/backend/access/transam/xloginsert.c/XLogRegisterBufData() |
XLogRecordAssemble()
将XLog的四个部分:XLog的header portion(包括XLogRecord,XLogRecordBlockHeader,RelFileNode, BlockNumber,mainrdata_len);xl_heap_header;元组具体数据;xl_heap_insert 链接成链表,每个都存储在XLogRecData结构体中。
在调用XLogRecordAssemble()之前,其实已经调用了很多XLogRegister相关函数,已经将xl_heap_insert链接到mainradata_head链表中,把xl_heap_header,元组具体数据链接到regbuf->rdata_head中;
1 | // src/backend/access/transam.c/XLogRecordAssemble() |
XLogInsertRecord()
要插入XLog buffer的数据都已经准备好了,保存在XLogRecData类型的hdr_rdt链表中,XLogInsertRecord()真正将链表中的数据写入到XLog buffer中。
输入:
- XLogRecData *rdata XLogRecData类型的hdr_rdt链表
1 | // src/backend/access/transam/xlog.c |
引用
https://blog.csdn.net/eagle89/article/details/80390145
https://www.cnblogs.com/igoodful/p/11822247.html
https://blog.csdn.net/xzwspy/article/details/80555624
什么是WAL:https://www.cnblogs.com/hzmark/p/wal.html
数据库集簇:https://www.cnblogs.com/feishujun/p/PostgreSQLSourceAnalysis_intro01.html
【1】https://www.interdb.jp/pg/pgsql02.html#_2.1.
【2】Concurrency Control https://www.interdb.jp/pg/pgsql05.html
【4】PostgreSQL WAL解析:构建WAL记录准备:https://blog.51cto.com/yanzongshuai/2436618
网址
官网:https://www.postgresql.org/
文档:www.interdb.jp/pg/pgsql08.html
yzs大神似乎很会研究PostgreSQL https://blog.51cto.com/yanzongshuai
PostgreSQL WAL解析:构建WAL记录准备 https://blog.51cto.com/yanzongshuai/2436618
postgres预写式日志的内核实现详解-wal记录写入:https://www.chinacion.cn/article/4871.html