
操作系统原理
linux下用户态和内核态的切换
参考“Linux下如何从用户态切换到内核态?”:https://blog.csdn.net/shanghx_123/article/details/83151064
linux命令
sudo
如果你是root用户,可以通过su root命令,然后输入root的密码切换到root用户。
如果你被划进了root用户组:更改/etc/sudors,此时你仍然只有普通用户的权限;但是你可以用命令sudo -i,然后输入你的密码,就可以执行root权限了;如果不用sudo -i,可以使用例如sudo mkdir dir类似的命令,在命令前面加上sudo,让这个命令有root权限。下面是root组用户关于sudo命令的详细介绍。
[sudo su]表示前用户暂时申请root权限,所以输入的不是root用户密码,而是当前用户的密码。sudo是用户申请管理员权限执行一个操作,而此处的操作就是变成管理员。运行结果 PWD=/home/用户名(当前用户主目录) 。
[sudo -i]表示为了频繁的执行某些只有超级用户才能执行的权限,而不用每次输入密码,可以使用该命令。提示输入密码时该密码为当前账户的密码。没有时间限制。执行该命令后提示符变为“#”而不是“$”。想退回普通账户时可以执行“exit”或“logout” 。运行结果 PWD=/root
[sudo !!]以root权限执行上一条命令。
[sudo -u userb ls -l]指定用户执行命令。
[sudo -l]列出目前的权限。
[sudo -u uggc vi ~www/index.html]以 uggc 用户身份编辑 home 目录下www目录中的 index.html 文件
[sudo su] 切换root身份,不携带当前用户环境变量。
[sudo su -]切换root身份,携带当前用户环境变量。
[sudo -i root]与[sudo - root]、[sudo -i] ,[sudo -] ,[sudo root]效果相同 提示输入密码时该密码为当前账户的密码 要求执行该命令的用户必须在sudoers中才可以 su需要的是切换后账户的密码。
chmod
将nvmDir文件夹的组权限加上w。(意味着和nvmDir所有者同组的人可以有写权限了)
1 | chmod g+w /data/yuming/nvmDir |
若加上-R选项,则意味着给目录及其所有子目录和子文件添加同样的权限
1 | chmod g+w -R /data/yuming/nvmDir |
usermod
1 | usermod -G hxlong zhouhuahui # zhouhuahui加入到hxlong组,但是也不在原来的组了 |
id
1 | id zhouhuahui #查看zhouhuahui的用户名,组名等 |
ln
假如/sublime_text/sublime_text是sublime的可执行程序,我如何在命令行中输入subl就可以自动打开这个软件呢?
通过软链接:ln -s /sublime_text/sublime_text /usr/bin/subl就可以实现了。
cat
读取文件内容
比如,读取linux系统的cpu信息:cat /proc/cpuinfo
读取linux系统的发行版信息:cat /etc/os-release
tar
tar -xvf \.tar //解压tar包**
tar -xzvf \.tar.gz // 解压tar.gz**
tar -xjvf \.tar.bz2 //解压 tar.bz2**
tar -xZvf \.tar.Z // 解压tar.Z**
-z参数:表示解压的是dutar.gz文件(如果是tar.bz2就是-j)
-x参数:表示是执行解压缩操作而不是打包操作
-v参数:表示列出解压时的详细消息
-f参数:指定要解压的文件名
ndctl
wget
下载文件:
1 | wget -P {保存文件的目录} {文件下载地址} #如果不指定保存目录,会下载在当前目录下 |
比如:
1 | wget https://ftp.postgresql.org/pub/source/v13.3/postgresql-13.3.tar.gz |
patch:补丁工具
使用diff命令产生补丁,使用patch命令给旧版本代码打补丁。参考【4】。
假设我们在~目录下有两个版本的proj1,分别是proj1_v1.0和proj1_v1.1。
1 | // ~/proj1_v1.0/a/1.c |
1 |
|
1 | // ~/proj1_v1.0/b/1.c |
1 |
|
1 | // ~/proj1_v1.1/a/1.c |
1 |
|
1 | // ~/proj1_v1.1/b/1.c |
1 |
|
我们可以使用diff命令产生从proj1_v1.0到proj1_v1.1的补丁。在~下执行:
1 | diff -Nrua proj1_v1.0 proj1_v1.1 > c.patch # 产生的补丁在c.patch中 |
c.patch中的内容为:
1 | diff -Nrua proj1_v1.0/a/1.c proj1_v1.1/a/1.c |
为了将proj1_v1.0代码更新成proj1_v1.1的代码,需要使用patch命令:
1 | cd proj1_v1.0 |
使用patch命令必须保证被打补丁的项目没有改变,否则,会产生.rej文件
perf: linux原生性能分析工具
如何读懂火焰图?作者:阮一峰 </br>
这篇博客讲了perf的简单使用以及如何读懂火焰图,火焰图示例.
程序员精进之路:性能调优利器—火焰图 腾讯技术工程 </br>
这篇文章对火焰图讲的更加详细,讲解了各种火焰图,比如on-cpu火焰图, off-cpu火焰图, 内存火焰图, hot/cold火焰图;提到了perf和SystemTap两种性能监测工具,SystemTap更加强大,由于我主要使用perf,所以先看perf。
利用perf及FlameGraph生成火焰图 Xiaobai__Lee </br>
--proc-map-timeout 1000 cpu太高的时候,进入该进程要时间,设置跟入该进程的超时时间。
这是一个生成火焰图的脚本示例,它生成正在运行的程序observer的火焰图
1 |
|
grep
1 | ps -aux | grep observer | grep -v grep |
awk
awk是linux下自带的强大的字符处理工具,参考:awk:一个强大的文本分析工具 作者: 阿铭
netstat
网络工具,一般这样用:
1 | sudo netstat -nap |
进程
用户在shell中可以同时执行多个命令。对于耗时很久的命令(如编译大型工程),用户不必傻傻等待命令运行完毕才执行下一个命令。用户在执行命令时,可以在命令的结尾添加“&”符号,表示将命令放入后台执行。这样该命令对应的进程组即为后台进程组。在任意时刻,可能同时存在多个后台进程组,但是不管什么时候都只能有一个前台进程组。只有在前台进程组中进程才能在控制终端读取输入。当用户在终端输入信号生成终端字符(如ctrl+c、ctrl+z、ctr+\等)时,对应的信号只会发送给前台进程组。shell中可以存在多个进程组,无论是前台进程组还是后台进程组,它们或多或少存在一定的联系,为了更好地控制这些进程组(或者称为作业),系统引入了会话的概念。会话的意义在于将很多的工作囊括在一个终端,选取其中一个作为前台来直接接收终端的输入及信号,其他的工作则放在后台执行。
waitpid()
系统调用waitpid,等待子进程退出:
1 | pid_t waitpid(pid_t pid,int *status,int options) |
pid参数的意义:
- pid>0时,只等待进程ID等于pid的子进程,不管其它已经有多少子进程运行结束退出了,只要指定的子进程还没有结束,waitpid就会一直等下去。
- pid=-1时,等待任何一个子进程退出,没有任何限制.
- pid=0时,等待同一个进程组中的任何子进程,如果子进程已经加入了别的进程组,waitpid不会对它做任何理睬。
- pid<-1时,等待一个指定进程组中的任何子进程,这个进程组的ID等于pid的绝对值。
options = WNOHANG表示非阻塞模式。
waitpid()的返回值:
- 当正常返回的时候,waitpid返回收集到的子进程的进程ID;
- 如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;
- 如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
环境变量
环境变量
环境变量是定义在整个计算机全局的变量,保存在文件中。
按照生效范围分类:
- 系统环境变量:对全部用户有效
- 用户环境变量:用户私有的
按照生存周期分类:
- 永久环境变量
- 临时环境变量(比如,我在bash中写的命令
export PATH=$HOME/Desktop/postgres/13.3/bin:$PATH只会在当前的会话中有效)
设置环境变量
bash中设置
1 | export 变量名='值' |
此时设置的是临时环境变量
系统环境变量
系统环境变量对全部的用户生效,设置系统环境变量有三种方法。
- 在
/etc/profile文件中设置。用户登录时执行/etc/profile文件中设置系统的环境变量。但是,linux不建议在/etc/profile文件中设置系统环境变量。 - 在
/etc/profile.d目录中增加环境变量脚本文件,这是Linux推荐的方法。 - 在
/etc/bashrc文件中设置环境变量。该文件配置的环境变量将会影响全部用户使用的bash shell。但是,Linux也不建议在/etc/bashrc文件中设置系统环境变量。
用户环境变量
在用户的主目录,有几个特别的文件,用ls是看不见的,用 ls .bash_* 可以看见,它们设置了用户环境变量。
- 在
.bash_profile中设置(推荐首选) - 在
.bash_logout中设置。当每次退出系统(退出bash shell)时执行该文件。 - 在
.bash_history中保存了用户使用过的历史命令
环境变量生效
1)在Shell下,用export设置的环境变量对当前Shell立即生效,Shell退出后失效。
2)在脚本文件中设置的环境变量不会立即生效,退出Shell后重新登录时才生效,或者用source命令让它立即生效,例如:
1 | source /etc/profile |
linux I/O
普通IO(read()/write())
【3】假设我们使用普通的I/O读取文件,底层是如何工作的呢?
- 进程通过系统调用读取数据
- 进程切换到内核态,通知设备进行读取
- 设备准备好的数据传送到内核空间
- 接收到数据后,内核态进程将数据从内核空间拷贝到用户空间
- 进程切换回用户态,继续执行用户空间的代码:处理数据
- 进程通过系统调用输出数据到设备
- 进程切换到内核态,把数据从用户空间拷贝到内核空间,通知设备进行输出操作
- 设备完成任务后,进程再次从内核态切换回用户态
在上面的过程中,涉及到4次进程模式切换,两次内存拷贝。这些操作对性能会造成一定影响。
sync() fsync() fdatasync()
https://blog.csdn.net/hmxz2nn/article/details/82868980 参考了这篇文章,写的很不错
这几个函数都是针对文件的写操作的。由于write()函数对于数据持久化和一致性不是很友好,因为这个函数返回了,并不代表数据真的就立马写到磁盘中了,因此需要fsync()和fdatasync()函数。这两个函数都是等待数据完全写入磁盘后才返回,否则程序会阻塞。
mmap的msync()
如果采用内存映射文件的方式进行文件IO(使用mmap,将文件的page cache直接映射到进程的地址空间,通过写内存的方式修改文件),也有类似的系统调用来确保修改的内容完全同步到硬盘之上:
1 | int msync(void *addr, size_t length, int flags) |
使用fdatasync优化日志同步
文章开头时已提到,为了满足事务要求,数据库的日志文件是常常需要同步IO的。由于需要同步等待硬盘IO完成,所以事务的提交操作常常十分耗时,成为性能的瓶颈。
在Berkeley DB下,如果开启了AUTO_COMMIT(所有独立的写操作自动具有事务语义)并使用默认的同步级别(日志完全同步到硬盘才返回),写一条记录的耗时大约为5~10ms级别,基本和一次IO操作(10ms)的耗时相同。
我们已经知道,在同步上fsync是低效的。但是如果需要使用fdatasync减少对metadata的更新,则需要确保文件的尺寸在write前后没有发生变化。日志文件天生是追加型(append-only)的,总是在不断增大,似乎很难利用好fdatasync。
且看Berkeley DB是怎样处理日志文件的:
- 每个log文件固定为10MB大小,从1开始编号,名称格式为“log.%010d”
- 每次log文件创建时,先写文件的最后1个page,将log文件扩展为10MB大小
- 向log文件中追加记录时,由于文件的尺寸不发生变化,使用fdatasync可以大大优化写log的效率
- 如果一个log文件写满了,则新建一个log文件,也只有一次同步metadata的开销
IO端口映射与I/O内存映射
参考【1】:首先讲了CPU地址概念和两种编址方式:统一编址和独立编址。
- 统一编址也称为“I/O内存”方式,外设寄存器位于“内存空间”(很多外设有自己的内存、缓冲区,外设的寄存器和内存统称“I/O空间”);
- 独立编址也称为“I/O端口”方式,外设寄存器位于“I/O(地址)空间”,在系统中就存在了另一种与存储地址无关的IO地 址,CPU也必须具有专用与输入输出操作的IO指令(IN、OUT等)和控制逻辑。这为讲I/O内存映射的来由做了铺垫。
虽然intel x86平台使用独立编址方式,但是x86平台普通使用了名为内存映射(MMIO)的技术,该技术是PCI规范的一部分,IO设备端口被映射到内存空间,映射后,CPU访问IO端口就如同访问内存一样。
对于Linux内核而言,它可能用于不同的CPU,所以它必须都要考虑上述两种编址方式,于是它采用一种新的方法,将基于I/O映射方式的或内存映射方式的I/O端口通称为“I/O区域”(I/O region),不论你采用哪种方式,都要先申请IO区域:request_resource(),结束时释放 它:release_resource()。
如果CPU采用统一编址技术,对外设的访问就是I/O内存方式:访问I/O内存的流程是:request_mem_region() -> ioremap() -> ioread8()/iowrite8() -> iounmap() -> release_mem_region() 。
ioremap()用来将IO资源的物理地址映射到内核虚地址空间(3GB - 4GB)中。
如果CPU采用独立编址技术,那么访问I/O端口有两种方式:
- I/O映射方式(I/O-mapped)。不映射到内存空间,直接使用 intb()/outb()之类的函数来读写IO端口
- 内存映射方式(Memory-mapped)。MMIO是先把IO端口映射到IO内存(“内存空间”),再使用访问IO内存的函数来访问 IO端口。
使用I/O内存映射读取文件
【2】普通地使用C语言的fread()或者fwrite()函数都需要将内容拷贝到IO缓冲区以及页高速缓冲区,这就增加了数据拷贝的次数,无形之中增加了CPU和内存的开销。使用内存映射技术可以减少系统调用的次数同时又可以降低数据的拷贝次数。
将文件映射到内存:
- 内存数据与文件数据一一对应
- 通过内存代替read/write系统调用接口来访问文件
- 减少数据拷贝,减少系统调用次数,提高了系统性能
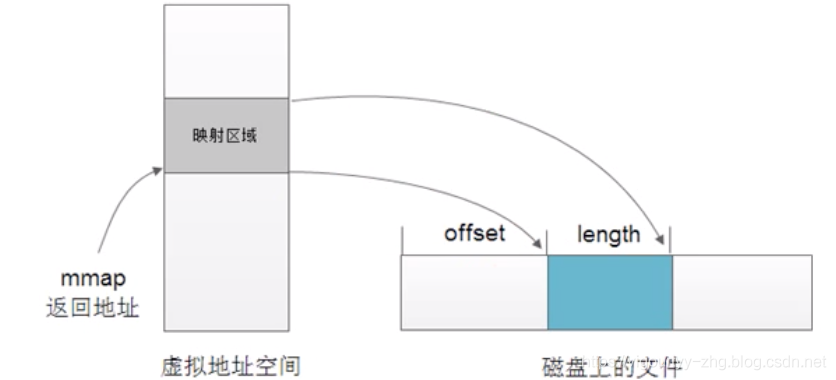
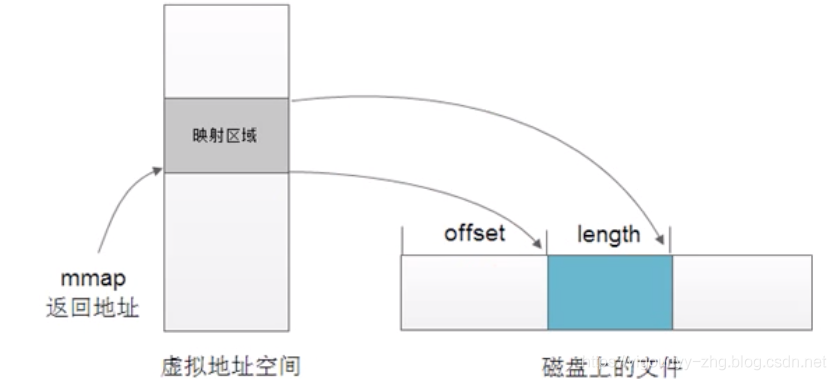
但是我有一个问题没有搞懂:使用用户缓冲的目的就是为了效率,如果不用缓冲了,改用内存映射,那么每次都直接把数据发送到存储器,这样的开销会不会比系统调用和多次拷贝的开销要大。
编程接口:
- 头文件
- 函数使用 void mmap(void addr, size_t length, int prot, int flags, int fd, off_t offset);
- 函数功能:在用户虚地址空间创建一个和实际物理内存相映射的关系。
函数参数: - addr:进程要映射的虚拟内存的起始地址,一般为NULL。操作系统会自动分配一个合适的内存地址。
- length:要映射实际的内存区域大小
- prot:内存保护标志,
PROT_EXEC(页内容可以被执行),
PROT_READ(页内容可以被读),
PROT_WRITE(页内容可以被写),
PROT_NONE(页不可访问) - flags: 映射的对象类型,
MAP_FIXED(如果由addr个length参数指定的内存区重叠与现存的内存区;如果指定的地址不可用,操作将会失败;并且起始地址必须落在页的边界上),
MAP_SHARED(与其它所有映射这个对象的进程共享映射空间。对共享区的写入,相当于输出到文件。直到msync()或者munmap()被调用,文件实际上不会被更新。),
MAP_PRIVATE(建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,) - fd:要映射的文件描述符
- offset:文件偏移地址
- mmap:以页单位操作,参数addr和offset必须按页对齐(4K对齐)
- 返回值:
成功:指向映射后的实际内存的地址
失败:MAP_FAILED
后面讲到了一些编程用例,具体查看【2】。
mmap工作机制
mmap为什么是零拷贝呢?不是很懂
通过调用memory map,我们让操作系统把文件的内容映射到内存,对内存的读写将关联到对应的文件。而应用通过访问用户空间操作这部分内存,避免了内存拷贝操作。
内存映射是文件到内存空间的映射。对于应用来说,和文件建立映射关系的是虚拟地址空间,而不是物理内存或者Heap。当我们建立一个2g大小的映射时,并不是在heap,更不是在物理内存中分配了这么大的空间,仅仅是在虚拟地址空间中划出了这么大一个区域而已,然后为虚拟空间分配一部分物理内存空间,就像页表一样。
应用访问内存映射区域时,操作系统会把虚拟的地址映射成真正的物理内存地址和底层文件的偏移量。如果应用访问的虚拟地址对应的文件内容尚未被装入内存,操作系统通过缺页中断,将内存中的部分内容交换出去,腾出空间将文件的内容读取到内存。
内存映射对性能的提升是有条件的:通过内存映射访问文件,虽然减少了内存拷贝,减少了系统调用引起的进程模式切换,但是过程中需要承担缺页中断的负担;对于小文件的读取,或者对于append模式的文件读写,内存映射的性能未看,未必优于普通io操作。只有对大文件的随机访问,内存映射才可能有明显优势,不过这仍然需要更具体的分析和进一步的的benchmark测试。
但是,对于NVM来说就不同了,mmap可以很好地利用NVM的字节寻址的特点;而且,mmap可以不用为映射的文件分配物理内存空间,直接把数据读写到NVM上的文件。
网络编程
sockaddr_in
sockaddr_in就是为了保存TCP/IP相关的信息:
1 | /* netinet/in.h |
为了将字符串形式的IP地址:SERV_IP和int类型的端口号SERV_PORT存储在sockaddr_in结构体serv_addr中:
1 |
|
sigaction和sigaction()
struct sigaction主要在sigaction信号安装和sigqueue信号发送时会用到,这是linux进程间信号传递的内容;
struct sigaction的源码:
1 | // usr/include/bits/sigaction.h |
由sa_handler指定的处理函数只有一个参数,即信号值,所以信号不能传递除信号值之外的任何信息;由sa_sigaction是指定的信号处理函数带有三个参数,是为实时信号而设的(当然同样支持非实时信号),它指定一个3参数信号处理函数。第一个参数为信号值,第三个参数没有使用(posix没有规范使用该参数的标准),第二个参数是指向siginfo_t结构的指针,结构中包含信号携带的数据值。
属性sa_mask指定在信号处理程序执行过程中,哪些信号应当被阻塞。缺省情况下当前信号本身被阻塞,防止信号的嵌套发送,除非指定SA_NODEFER或者SA_NOMASK标志位。
属性sa_flags中包含了许多标志位,包括刚刚提到的SA_NODEFER及SA_NOMASK标志位。另一个比较重要的标志位是SA_SIGINFO,当设定了该标志位时,表示信号附带的参数可以被传递到信号处理函数中,因此,应该为sigaction结构中的sa_sigaction指定处理函数,而不应该为sa_handler指定信号处理函数。
sigaction()有3个参数:第一个参数是信号的值,第二个是sigaction结构的指针。第二个参数说明了第一个参数指定的信号发生时调用的函数和其它的一些信息。
下面是使用sigaction的例子:
1 |
|
gdb调试
1 | // debug1.c |
在linux bash下执行:cc -o debug1 -DDEBUG=3 debug1.c
结果是:
1 | debug1: Aug 17 2021 at 08:17:47 |
通过指定-DDEBUG选项的值为0, 1, 2或者3,可以有不同的调试输出。
启动gdb
假设已经编译好了a.c文件,然后可执行文件是a
1 | cc -g -o a a.c |
然后:
1 | gdb a |
此时只是启动gdb,但是并没有运行程序
1 | (gdb) |
运行程序
1 | (gdb) run |
栈跟踪
1 | (gdb) backtrace |
通过这个命令可以看到程序是如何到达这个断点的。
检查变量
print语句可以输出程序中的表达式的值。加入程序中有int a[]数组,则可以通过下面的命令输出a[3]的值。
1 | (gdb) print a[3] |
输出a[0]到a[4]
1 | (gdb) print a[0]@5 |
列出程序源代码
1 | (gdb) list |
设置断点
1 | (gdb) break 3 # 在第3行设置断点 |
继续执行:
1 | (gdb) cont |
加入在源码目录运行gdb,可以任意指定某个文件的某个函数,某行设置断点:
1 | break ./src/sql/parser/ob_parser.cpp:ObParser::parse |
1 | break ./src/sql/parser/ob_parser.cpp:210 |
设置源文件读取路径
1 | dir /home/test/zhouhuahui/Github/oceanbase |
1 | show directories # 所有的源文件路径 |
单步执行:
1 | (gdb) next |
info命令:告诉gdb列出所有的断点
1 | (gdb) info break |
disable: disable某个编号的断点,如果想要用这个断点,只需enable
1 | (gdb) disable break 1 # disable第一个断点 |
在某个函数设置断点:
1 | (gdb) break func |
attach
如何用gdb调试已经运行的程序。加入一个程序的pid是1234
1 | (gdb) attach 1234 |
进入代码模式
快捷键ctrl+X+A。
跳出函数
1 | finish |
跳出循环
1 | until |
条件断点
例如程序:
1 |
|
当我用gdb调试输入:
1 | b func if i==50 |
可以在第50个循环处停止:
1 | Breakpoint 2, func (i=50) at demo1.cpp:5 |
问题
当编译时,未加 - g 选项,则进入gdb环境中执行命令会出现No symbol table is loaded. Use the “file” command.提示;
linux工具
gcc
多个源文件的编译:(假如有a.h, a.c, b.c文件)
1 | gcc a.c b.c -o b |
引用
【1】linux中的 IO端口映射和IO内存映射 https://blog.csdn.net/geekster/article/details/11393995
【2】linux 文件IO与内存映射:内存映射 https://blog.csdn.net/Z_Stand/article/details/102305129
包含专栏“linux操作系统:io系统” https://blog.csdn.net/z_stand/category_9403370.html
【3】虚拟内存/用户空间与内核空间/MMap与MUnmap
【4】打补丁patch 命令使用:https://blog.csdn.net/xfxf996/article/details/103851041