
跳表
跳表 (SkipList) 是由 William Pugh 提出的。他在论文呢 《Skip lists: a probabilistic alternative to balanced trees》中详细的介绍了跳表的结构、插入和删除操作的细节。
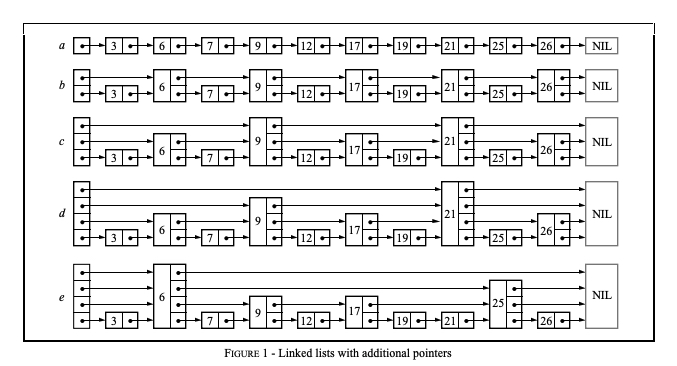
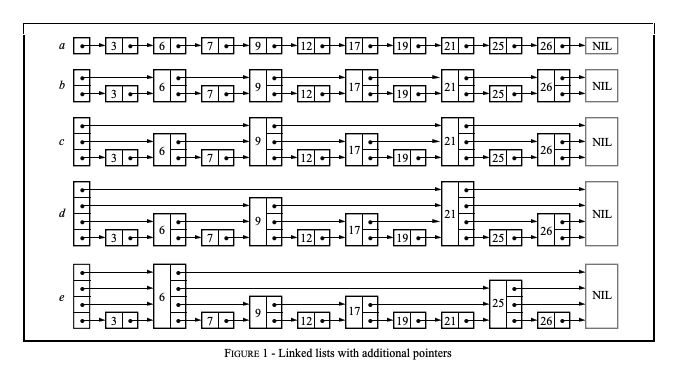
- 图 a 中,所有元素按顺序排列,被存储在一个链表中,则一次查询最多比较 N 个链表节点;
- 图 b 中,每隔 2 个链表节点,新增一个额外的指针,该指针指向间距为 2 的下一个节点,如此以来,借助这些额外的指针,一次查询至多只需要 n/2 + 1 次比较; 图 c 中,在图 b 的基础上,每隔 4 个链表节点,新增一个额外的指针,指向间距为 4 的下一个节点,一次查询至多需要 n/4 + 2 次比较。
跳表查找
为了在跳跃表中搜索一个关键字,我们从顶层开始,直到找到该搜索关键字或一个比关键字小但下一链接又比关键字大的节点,然后向下移一层并重复这个过程。如此继续,直到搜索成功或在底层搜索失败。
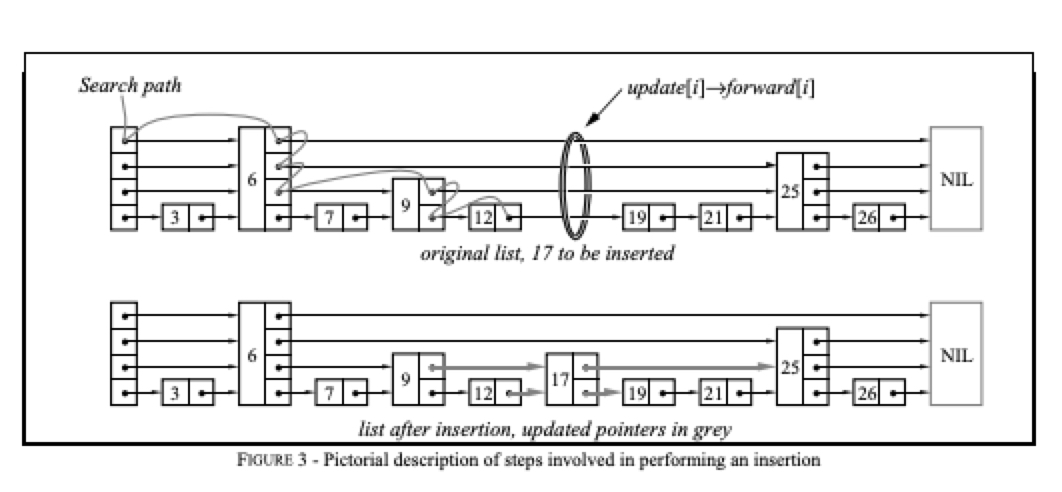
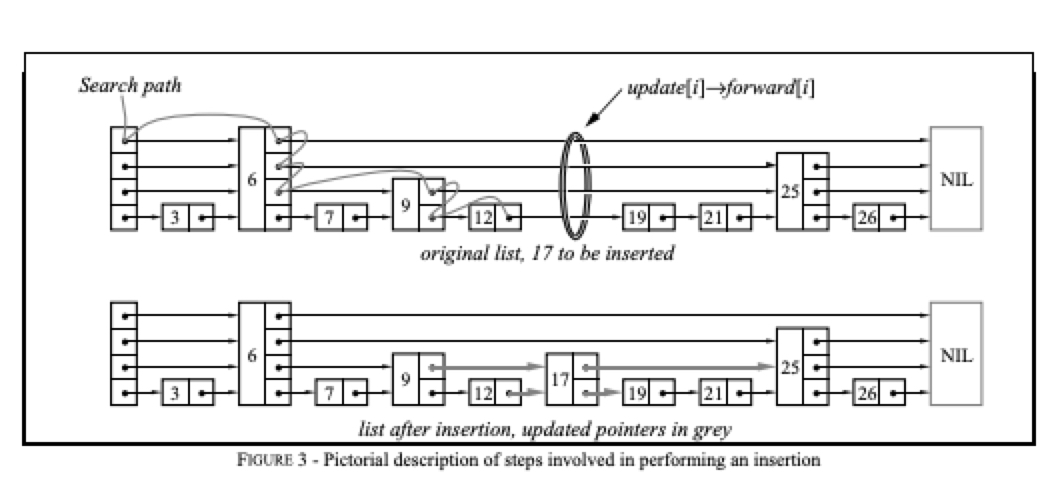
快速查询的效率是:O(log_n)
引用
《拒绝做SQL boy…》中有一章节讲跳表:https://gitbook.cn/books/5f16777f3ff24476fa473e93/index.html#undefined
图解跳表:http://www.360doc.com/content/20/1204/11/13328254_949434656.shtml