
背景
传统的阻塞式IO的特点是:若IO未完成,则应用程序一直被内核挂起,这样的话,只用一个线程处理很多个IO则不太可能,因为当你在等待一个要花很长时间的IO时,其他IO则完全无法处理。如果要处理多个IO,则必须要有多个进程和线程。
IO多路复用

I/O多路复用,I/O就是指的我们网络I/O,多路指多个TCP连接(或多个Channel),复用指复用一个或少量线程。
当调用select的时候告知内核对哪些事件(读就绪,写等)感兴趣以及等待多长时间。
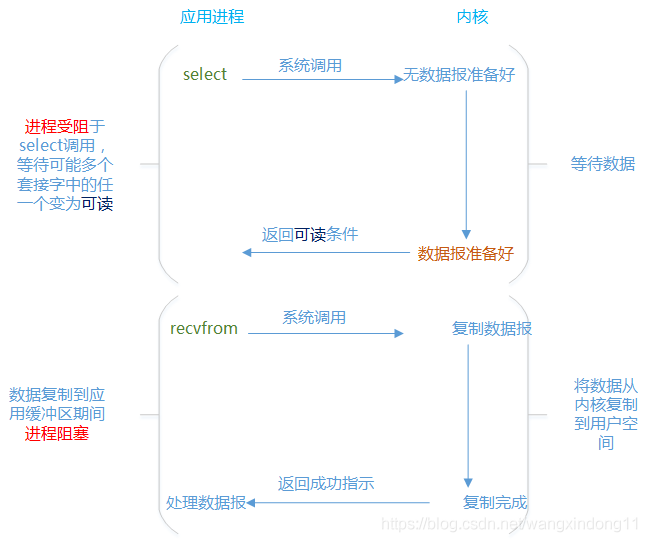
- 当用户进程调用了select,那么整个进程会被block;
- 而同时,kernel会“监视”所有select负责的socket
- 当任何一个socket中的数据准备好了,select就会返回;
- 这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
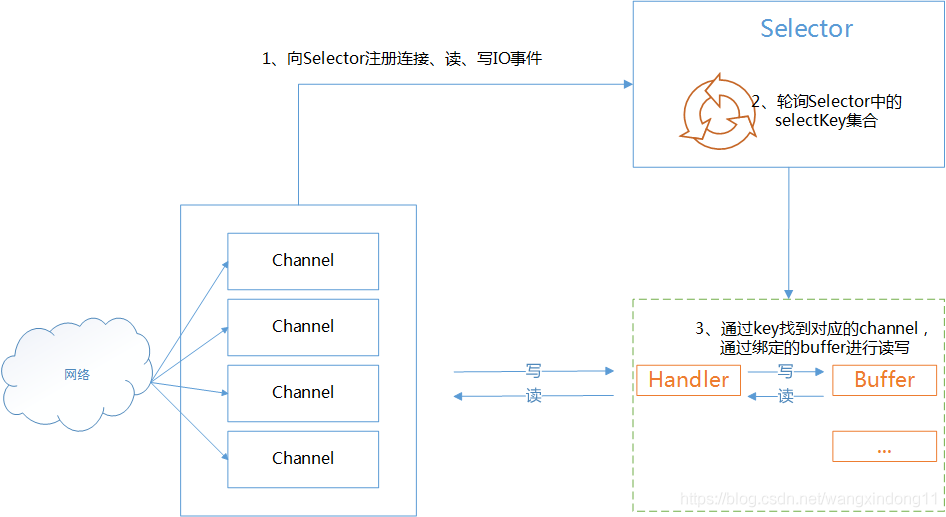
为了方便我们理解select调用,可以参照下面这张图,是jdk的基于I/O多路复用技术的NIO实现。重点在于理解Selector复用器。

阻塞式IO与IO复用
阻塞式I/O和I/O复用,两个阶段都阻塞,那区别在哪里呢?都是阻塞,但是阻塞式I/O如果要接收更多的连接,就必须创建更多的线程。I/O复用模式下大量的连接统统都可以过来直接注册到Selector复用器上面,同时只要单个或者少量的线程来循环处理这些连接事件就可以了,一旦达到“就绪”的条件,就可以立即执行真正的I/O操作。这就是I/O复用与传统的阻塞式I/O最大的不同。也正是I/O复用的精髓所在。
select, poll, epoll
select
select()是一种系统调用,用于IO多路复用技术中选择准备好的socket。但是select有个缺点:
- select是通过监控文件描述符(file descriptor, fd)来实现,如果有一个或以上的文件描述符处于“就绪”(ready)状态,就返回其中一个即可。这些fd在系统内核中是通过何种数据结构存储的呢?是通过bitmap存放的(数据结构为fd_set),它默认大小是1024(对于64bit有2048个)。因此,对于大于1024的fd,基本效果就不可控了,这客观限制了并发量的上限。
- 轮询的时间复杂度是O(n)
- 涉及较多用户态和内核态拷贝
poll
poll对select有了些许改进,如修正了fd数量的上限等等,但其他改进的幅度不大,此处不详谈。
epoll
epoll的优势主要有:
- 修正了fd数量的限制
- 放弃使用bitmap数据结构,底层改用了链表、红黑树.
- 采用事件驱动
- 无需重复拷贝fd
这篇文章写epoll写的太好了:Epoll原理解析。它主要讲了一下几点:
- 网络IO的硬件基础
- 进程阻塞为什么不占用CPU资源
- socket中维护了进程等待队列,用于在就绪后唤起相应的进程
- select的缺点
- epoll的详细思路。解释了epoll比select强大的两个重要原因是:
a) 将“维护等待队列”和“阻塞进程”两个步骤分离
b) 就绪列表:让程序知道哪些socket收到了数据