
往年OB赛题
OB大赛
参考OceanBase大赛miniob代码架构框架设计和说明
参赛宝典
看看参赛宝典
第4章 查询处理
参考查询处理
选择运算
一般情况下,当选择率较低时,基于索引的选择算法要优于全表扫描。但在某些情况下,如选择率较高、或者要查找的元组均匀分散在表中,这时索引扫描法的性能可能还不如全表扫描法,因为还需要考虑扫描索引带来的额外开销。
参赛题目
参考参赛题目
其中,其中必做题的多表查询这道题,我们可以思考一下怎么和后面的查询优化关联。weihan学长说这部分不要用笛卡儿积,要考虑各种join,比如hash join和merge join。
- 在 1b9d1be 这里,做了基础题加上join, insert, null和unique
- dev中commit 7aa5bada5df5bbcd68f3fa63904e4b28021dd753 的已经有140分了
basic
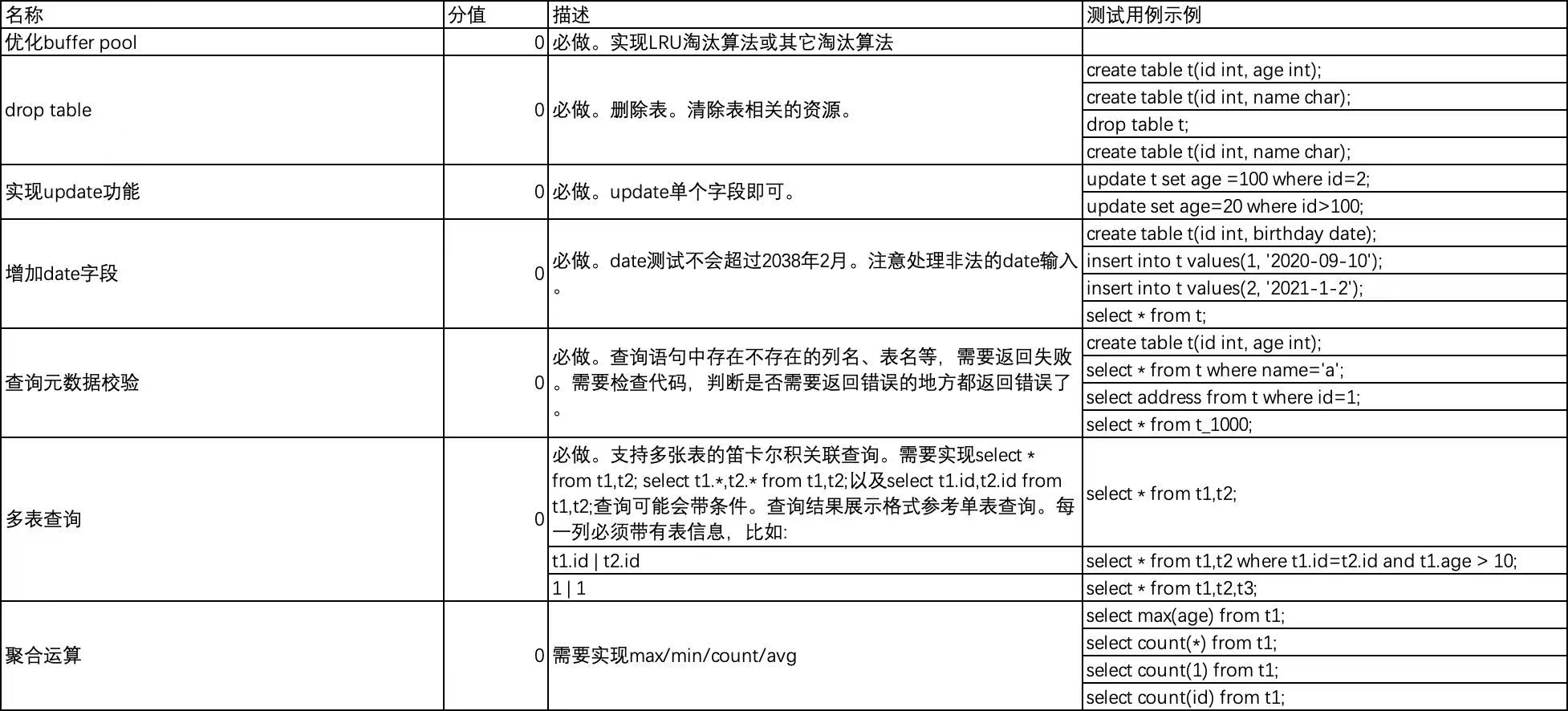
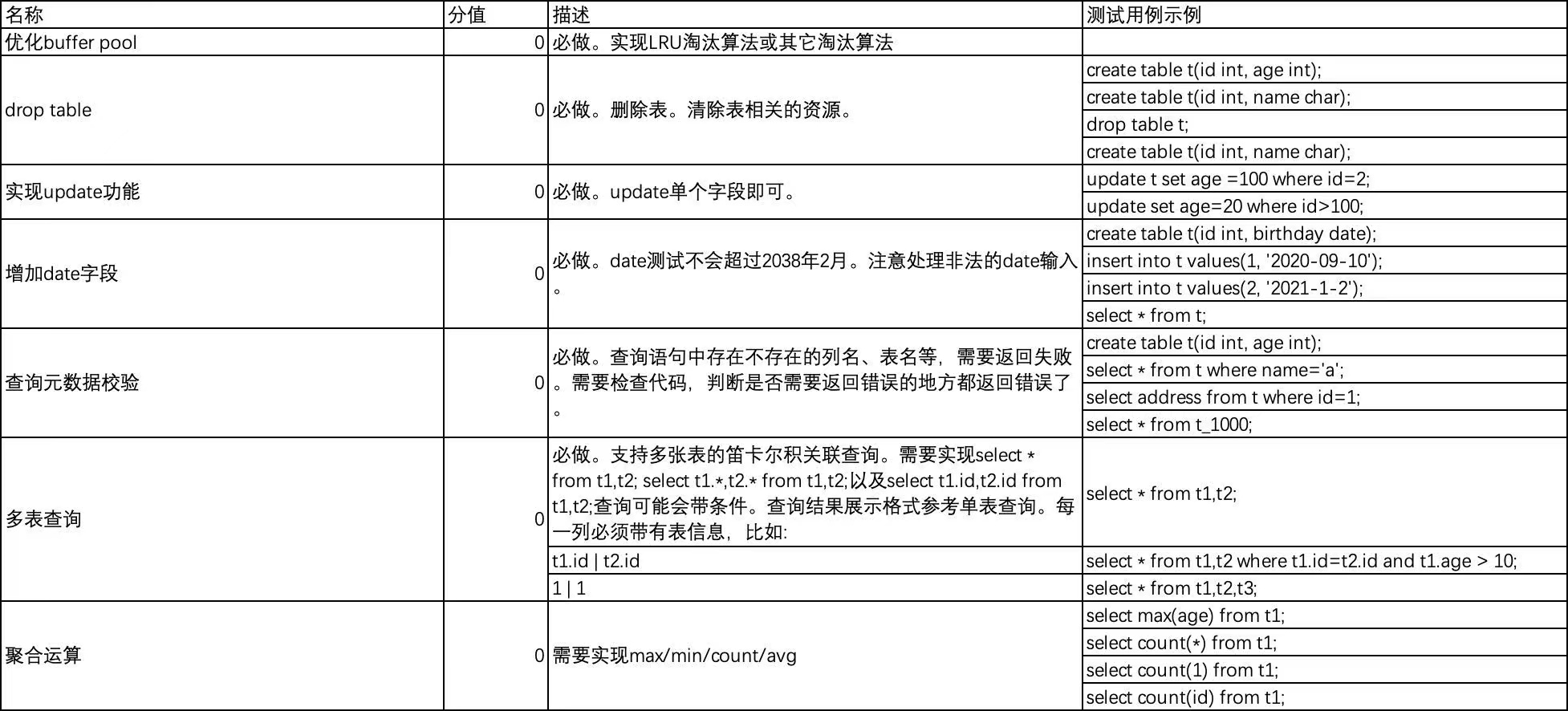
优化buffer pool
在storage/default/disk_buffer_pool.cpp/DiskBufferPool::get_this_page(int file_id, PageNum page_num, BPPageHandle *page_handle)中,是得到一个缓存页面用于判断适不适合插入输入,所以对应的页面被访问过了,因此要更改LRU链表。
1 | Frame *f = bp_manager_.get(file_handle->file_desc,page_num); |
在storage/default/disk_buffer_pool.h/BPManager/get(int file_desc, PageNum page_num),实现了LRU:
1 | Frame *get(int file_desc, PageNum page_num) { |
update
测试用例
增加date字段
语法和词法部分
在sql/parser/lex_sql.l文件中增加词法规则:
1 | [Ii][Nn][Tt] { position=strdup(yytext);RETURN_TOKEN(INT_T);} |
1 | {QUOTE}[0-9]{4}-((0?[1-9])|(1[0-2]))-((0?[1-9])|([12][0-9])|(3[0-1])){QUOTE} {yylval->string=strdup(yytext);position = strdup(yytext);RETURN_TOKEN(DATE);} |
如上述,在int, char, float的基础上增加了数据库列的date属性。也增加了对日期值的判断(比如在insert语句中,可以识别"2010-10-9"是一个单独的TOKEN,为DATE)。
在sql/parser/yacc_sql.y中增加标识TOKEN:
1 | %token |
1 | %token <string> DATE |
语法规则部分:
1 | type: |
1 | attr_def: |
insert语句的推导式是: insert: INSERT INTO ID VALUES row row_list SEMICOLON,row的推导式是:row: LBRACE value value_list RBRACE,因此要在value的推导式中加入对DATE的支持。
1 | value: |
在sql/parser/parse_defs.h中定义date字段的标识(因为create语句在内存中是以Query数据结构的形式保存的,Query中要记录每个列属性的类型,这个列属性的类型就由enum类型的AttrType表示)。
1 | //属性值类型 |
还有要加入value_init_date()函数,具体怎么定义和实现,可以参考value_init_string()的定义和实现。
接下来思考:在各种SQL语句中,它们是怎么支持date字段的。
1 | create table t1(birthday date); |
根据本片文章中源码/调试跟踪/创建表的记录情况,我认为create语句是不会更改的。
select语句部分
我怀疑select语句相关代码可能要更改,在查询到page中的tuple后,要把这个tuple转换为一行字符串的形式输出,而且要按照特定格式输出,此时肯定要判断出date属性类型,然后进行相应操作。
在sql/executor/tuple.cpp/add_record(const char *record)中,是要将page中的一个record转换为Tuple类型(Tuple包含很多TupleValue的指针,依次表示一个元组的很多属性值,TupleValue是属性值的表示),所以在这里要考虑很多属性值类型,然后将record中对应位置的bytes转换为TupleValue
1 | void TupleRecordConverter::add_record(const char *record) { |
但是上述代码没有考虑date属性值类型的情况。
在sql/executor/value.h中定义了不同的TupleValue,比如:
1 | class StringValue : public TupleValue { |
这个是string字符串类型的TupleValue,叫做StringValue。我们需要自己定义一个DateValue的TupleValue。
我觉得insert语句相关代码也要更改,因为要把Query类型的数据结构转换为实际在page中存储的元组,要判断date属性类型,然后进行相应的格式转换。
最后顺藤摸瓜, 找到了这个函数的一行语句: storage/common/table.cpp/insert_record(Trx *trx, int value_num, const Value *values)。
1 | RC rc = make_record(value_num, values, record_data); |
bug
- 类似于
where s="1998-12-9",可能错弄成字符串和date了
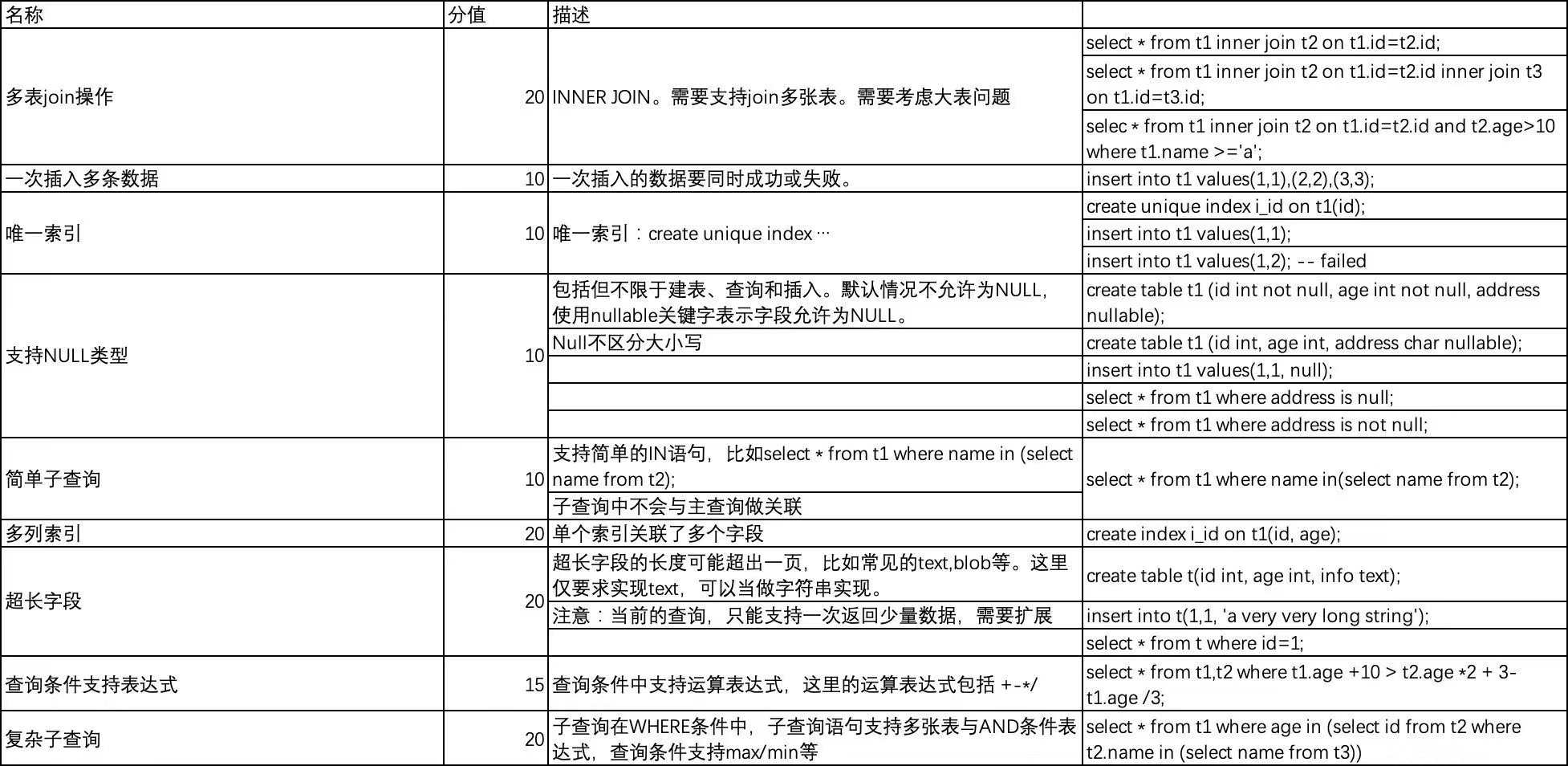
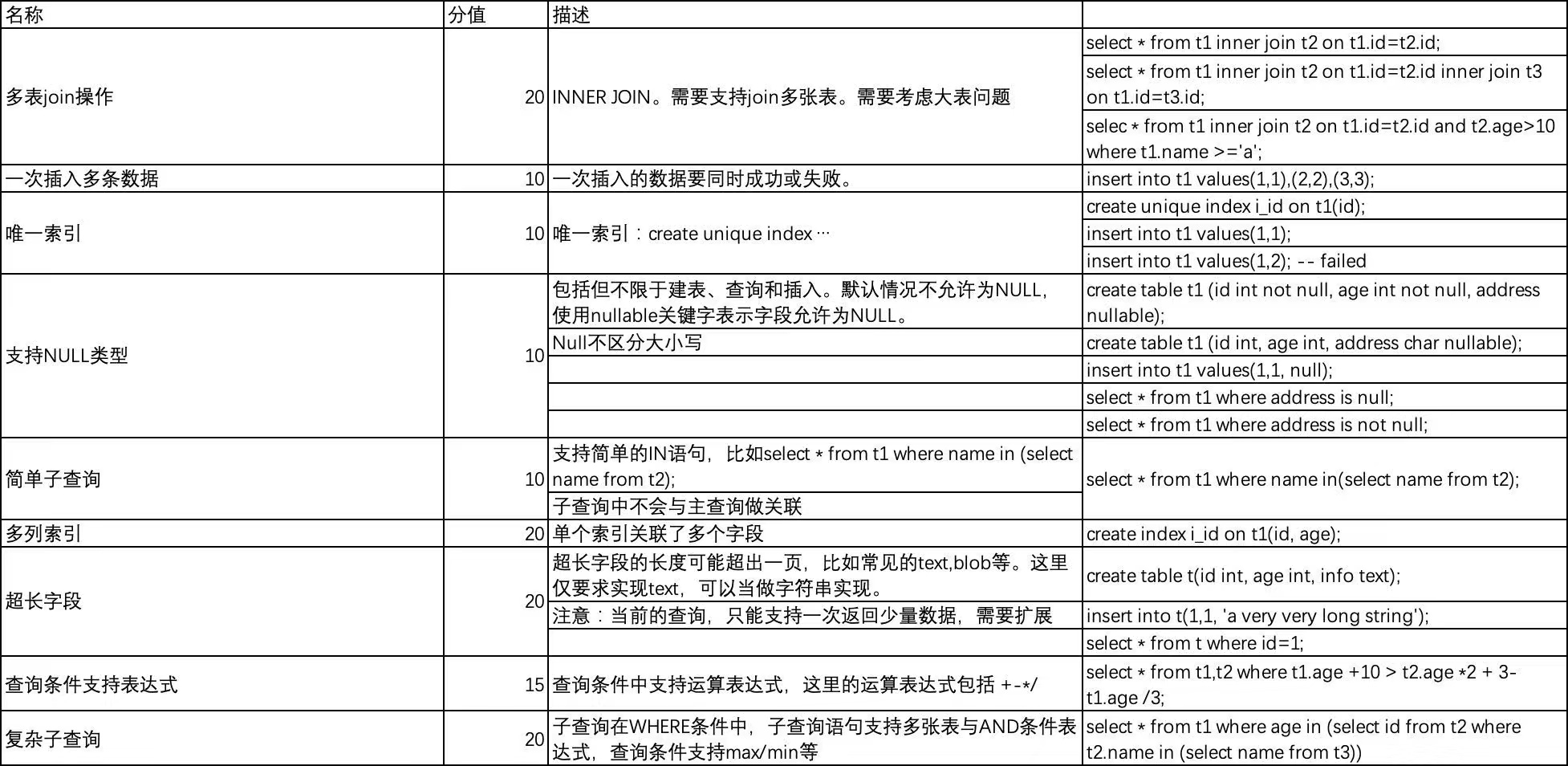
一次插入多条数据
我发现在storage/default/default_handler.cpp/DefaultHandler::insert_record(Trx *trx, const char *dbname, const char *relation_name, int value_num, const Value *values, int row_num, const int *row_end),这个函数里,实现了一次插入多条数据,所以我主要的工作可能还是在语法分析上,主要是改yaac_sql.y文件。
查询元数据校验
在sql/executor/execute_stage.cpp/check_select_meta_data(const Selects &selects,
const char *db,
SessionEvent *session_event)中,对selects中的表,属性和条件进行校验,主要判断表和涉及的属性是否存在(所以需要db参数);如果是多表连接,那么属性一定要带表明前缀,如:school.salary。
多表连接
在sql/executor/execute_stage.cpp/ExecuteStage::do_select(const char *db, Query *sql, SessionEvent *session_event)中,初始化了很多SelectExeNode,但是这些node中的TupleSchema只包含查询属性,并不包含表的所有属性,这就会导致多表连接的一个问题:
假设,t1有col1和col2属性,t2有col1和col2属性,然后执行SQL:select t1.col, t2.col2 from t1,t2 where t1.col2==t2.col2。这些node执行查询后,产生的结果TupleSet中也只包含查询属性,在这个例子中,对t1初始化了执行结点node1,产生tupleset1,对t2初始化了执行结点node2,产生tupleset2,但是tupleset1只包含col1属性,tupleset2只包含col2属性,这样的话,如何基于tupleset1和tupleset2进行多表连接?我觉得以一种解决方法是,node1中不仅要包含查询属性,还要包含必要的在多表连接中需要用到的属性。A
聚合运算
在sql/parser/lex_sql.l文件中,添加了词法规则:
1 | [Cc][Oo][Uu][Nn][Tt] position=strdup(yytext); RETURN_TOKEN(COUNT); |
在sql/parser/yacc_sql.y文件中,添加标识TOKEN:
1 | %token |
添加语法规则:
1 | select_attr: |
以上只是一个例子,其实关于COUNT的语法规则还有别的,以及AVG等其他的规则,而且写的都和上面的差不多。relation_attr_with_agg_init()是在sql/parser/parse_defs.h定义的,实现在sql/parser/parse.cpp中,构造一个RelAttr对象。
在sql/executor/execution_node.cpp中实现AggregationExeNode的很多函数。
在sql/executor/execute_stage.cpp/ExecuteStage::do_select(const char *db, Query *sql, SessionEvent *session_event),添加对聚合的支持:比如,在条件过滤后建立AggregationExeNode来进行聚合运算
1 | AggregationExeNode node; |
多表join操作
支持NULL类型
- 添加词法语法规则
- 在
parser_defs.h中加入对insert, create中null的支持 - 更改
table_mate.h可以在表的元数据中加入对null的支持;还要看数据库启动时如何加载表的元数据的 - 查看select, insert, create, update的流程,看看有没有需要加入null支持的;在输出的时候,有的空字段可能要输出NULL
- 聚合也要改一下,比如t表中有5个行,但是这5行的col2属性有2个是非空的,那么
select count(col2) from t的结果是2;如果某个属性col2全是空的,那么select max(col2) from t的结果就是NULL; - 底层的表结构该如何支持null
insert对null的支持
在storage/common/table.cpp/Table::insert_record(Trx *trx, int value_num, const Value *values)
1 | RC rc = make_record(value_num, values, record_data); |
要改下形成的record结构, 使得它能够标识哪些属性是null的。然后在Value结构体中加入对null的标识。然后改下make_record()函数进行相关校验,以及标识哪些属性是null的。
TupleField也要支持null,用于表示这个属性是否是nullable的,这样在insert的元数据判断时,要检查属性是否是nullable的。
Value也要支持null,当在insert的时候,就可以表示这个插入的值是不是null。
在初始化page页面的时候,需要用到record_size来初始化page的头部,比如根据record_size来计算页面能够容纳多少个record。在table.cpp/Table::insert_record(Trx *trx, Record *record)中有个代码:
1 | rc = record_handler_->insert_record(record->data, table_meta_.record_size(), &record->rid); |
但是幸运的是,不用改这部分,因为代码写的扩展性比较好。
select对null的支持
在sql/executor/tuple.cpp/TupleRecordConverter::add_record(const char *record) 中从record字节数组中读取想要的列,这里估计要改下。
TupleValue要支持null,当add_record()函数读取到schema中的某个属性是null的话,就用支持null的TupleValue来存储。
where条件部分:在condition进行filter的时候,要知道null和谁比较都是false。如果条件中有一个是null值,则可以不做类型兼容性判断。
create对null的支持
table_meta要能够保存哪些属性是nullable的。
在/storage/common/table.cpp/Table::create(const char *path, const char *name, const char *base_dir, int attribute_count, const AttrInfo attributes[])中,改变对table_meta的初始化,table_meta中要保存哪些属性是nullable的,每个属性的null标识指针(指向record中哪个bit,这个bit表示对应属性是否是null)。field_meta中增加了nullable, nulltagoffset, nulltaglen属性,然后它的init(), to_json(), from_json()都要改。
AttrInfo结构体也要支持null,表示这个属性是不是nullable的。attr_info_init()函数要默认AttrInfo的nullable是false。
update对null的支持
修改了执行阶段的对于update的校验。
索引
普通索引的话就 插入数据的时候key是null不给它建索引,按照索引查找的时候本身也用不到null数据, is null单独处理,not null正好遍历存在索引的数据就行了。如果是condition中含有null,则也不用索引。
update要更新索引,如果update某个null的属性为非null,那么就要添加索引项;如果update某个非null属性为null,就要删除索引项。
在table.cpp中,要更新插入索引和删除索引项的代码,当对应属性为null时,直接返回。
在table.cpp中,创建IndexScanner时,如果发现是针对is null创建的,就直接返回nullptr,意思说不对is null的用索引查找。
- 但是,is null用不到索引,可能要全表扫描,效率不好。还有一个问题是,我没有判断当is null时不从索引查找,这就意味着,当在nullable的属性上建立索引时,并查找这个属性is null的所有行,可能完全查找不到,因为是从索引中查找的。
- 支持is not null吗
多表对null的支持
索引
- 如果没有where语句就不用索引来查找
- 如果是is null的where语句,也不用索引来查找。
子查询
condition要改,支持大于tupleset之类的,因为子查询要用。
查询支持表达式
1 | expression: result file difference(`-` is yours and `+` is base) |
我们要重新设计一整套架构,要对原来的代码进行一番重构,从语法分析阶段到查询执行阶段,很多都要重构,下面具体分析该如何做。总的来说,以前的select clause中只有属性,聚合,但是现在要有表达式(基于属性和非null值)和聚合,以前的condition clause中有属性或值比较属性或值,但是现在要有表达式(基于属性和值)比较表达式,这些变化对后面的架构有重要影响。
测试样例
1 | create table texp1(i int, f float, c char, d date); |
Selects结构
原来的Selects结构:
1 | // struct of select |
但是这个结构已经不适用了,因为RelAttr和Condition不可能支持表达式了。
新的架构可以是:
1 | typedef struct { |
RelAttrExp结构
1 | typedef enum { |
1 | typedef struct { |
ConditionExp结构
原来的Condition结构是:
1 | typedef struct _Condition { |
可以改为:
1 | typedef struct { |
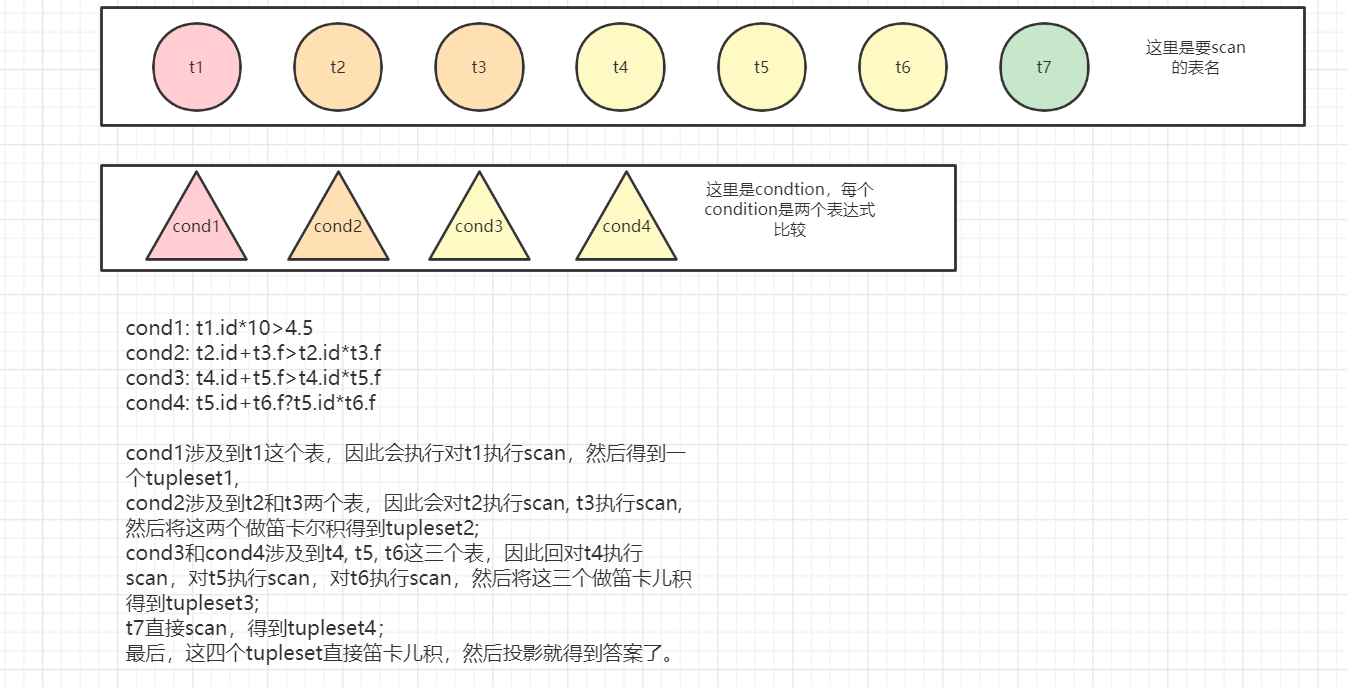
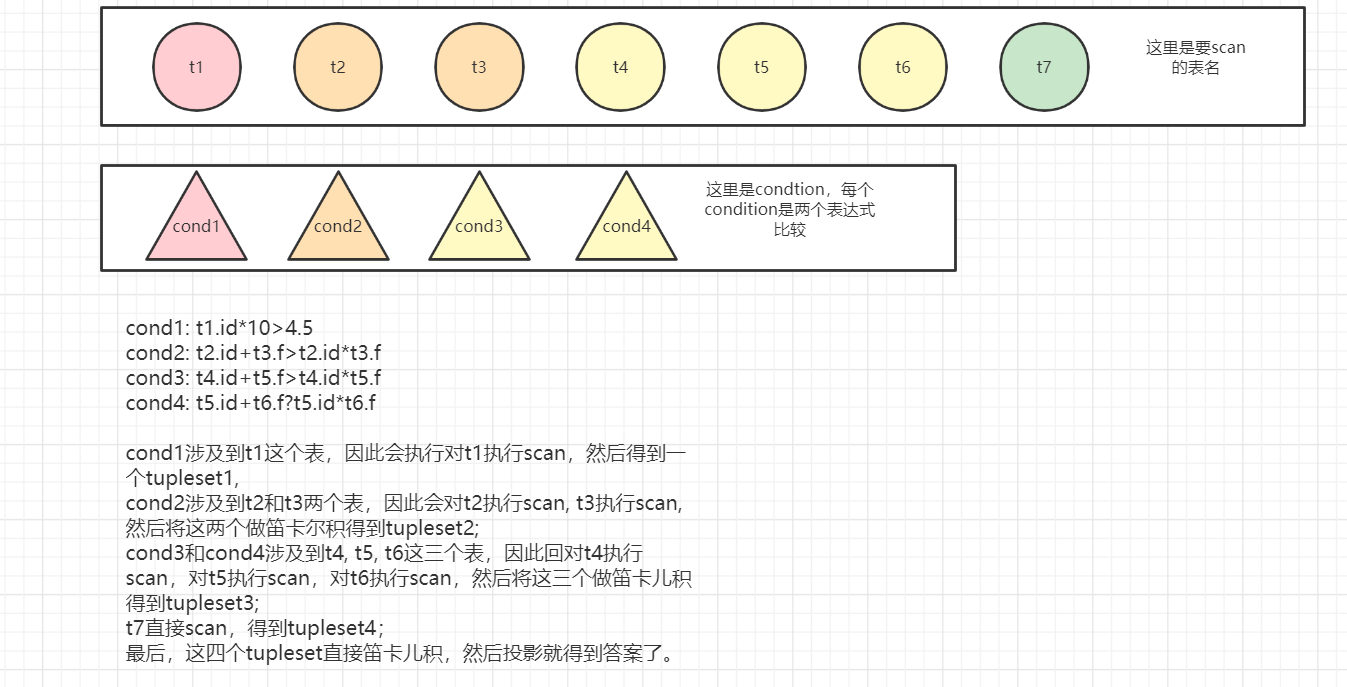
改变value_init_float()函数,使得value可以存储float的字符串完整字符串形式。
在do_select()函数中判断AdvSelects结构是否是简单select形式(select clause只包含简单的属性, where clause中只包含属性或值之间的比较,不包含表达式之间的比较),如果是,就将AdvSelects重构为老版本的Selects,然后走老路线;否则,就直接走新路线。
filter要支持左右两边可以是表达式或者tuplset,支持表达式是为了select语句中where语句可以有表达式,支持tupleset是为了支持嵌套子查询。
当我有了要选择的很多表以及很多condition,我该如何得到最终的tupleset?我需要一个SelectionExeNode,来执行支持表达式比较的单表查询;我需要一个JoinExeNode来执行支持表达式比较的多表连接;我需要一个CartExeNode来执行多个表的笛卡儿积;我需要一个projection来执行投影操作。
selects的destroy函数要改,可能还要涉及到一些属性的destroy函数。
lex文件中加入加减乘除的token
yacc文件中的递推式设计的有问题
修改lex和yacc文件


1 | /* @author: huahui @what for: expression <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<*/ |
1 | /* @author: huahui @what for: expression <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<*/ |
约束
排序
todo:
- 在创建单表schema的时候,要把order_attrs中的属性考虑进来
- 多表的输出是一个未projection的tupleset
- 在多表之后,聚合之前,做好排序和projection的工作。
测试用例:
1 | create table torder(i int, f float, c char, d date); |
分组
把分组的属性放在schema中
在convert_to_selects()中将groupby的属性添加到selects中
groupby的select中不能有星
测试样例:
1 | create table tgroup(i int, f float, c char, d date); |
代码框架介绍
这个是一个视频,在OceanBase社区版 这个页面有。
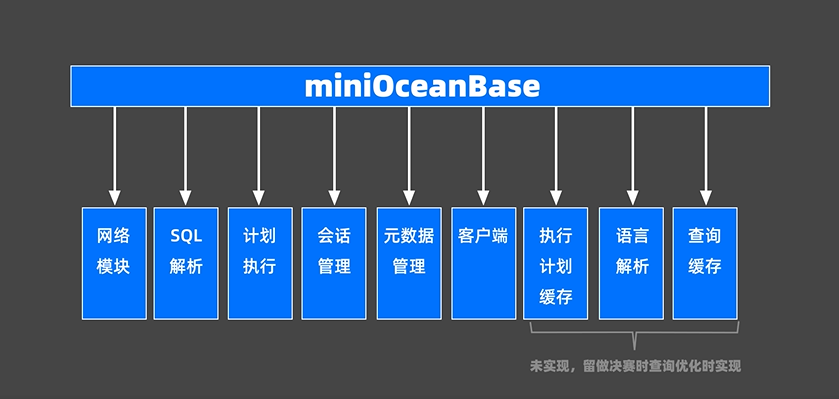
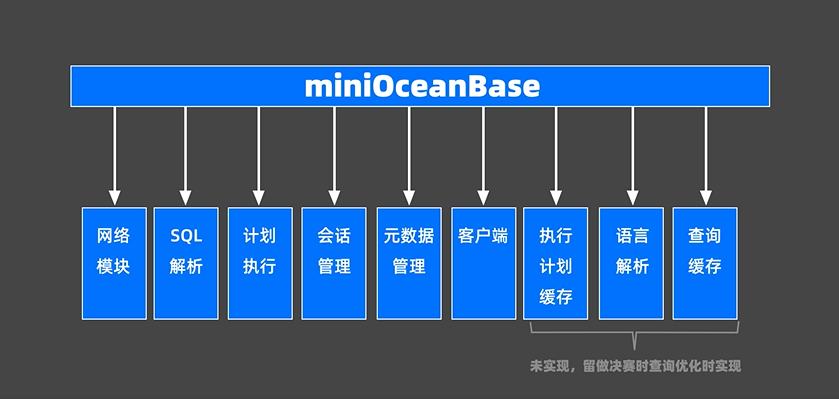
网络模块
主要与客户端交互。在miniob/src/observer/net/server.h中定义。
SQL解析
将用户输入的SQL语句解析成语法树。
在miniob/src/observer/sql/parser/lex_sql.l文件中,负责词法解析,yacc_sql.y负责语法解析
计划执行
根据语法树描述执行并生成结果,miniob/src/observer/sql/executor/execute_stage.h会根据用户输入的SQL命令执行相应的语句,然后将生成的结果返回给客户端。
元数据管理
记录了当前数据库的表,字段和索引的元数据,在miniob/src/observer/storage/common/field_meta.h中。
执行计划缓存
这个和以下两个在决赛时用作查询优化题目的实现。在miniob/src/observer/sql/plan_cache中,将该SQL第一次生成的执行计划缓存在内存中,后续的执行可以反复执行这个计划,避免重复查询优化的过程。
语义解析
将生成的语法树转换成数据库内部的数据结构,在miniob/src/observer/sql/parser中。
查询缓存
将执行的查询结果缓存在内存中,下次查询时可以直接返回query_cache。在miniob/src/observer/sql/query_cache中。
查询优化
查询优化在miniob/src/observer/sql/optimizer中,根据一定的规则和统计数据,调整或重写语法树。
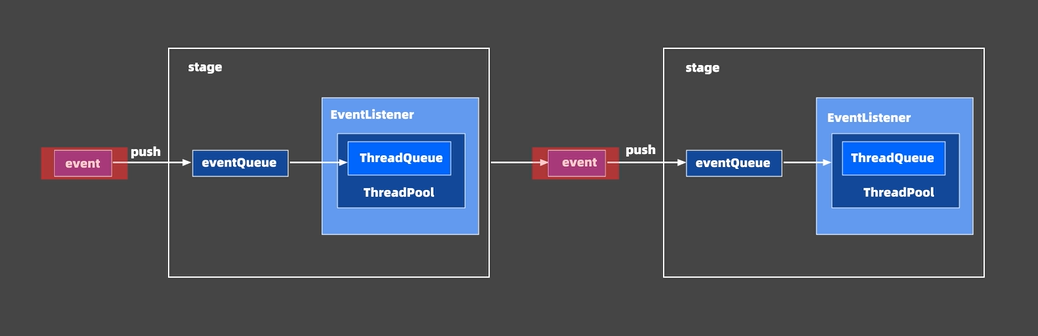
SEDA事件处理框架
结合事件驱动和多线程模式的优点,做到易扩展,解耦合和高并发,代码在miniob/deps/common/seda,代码量很大,使用方法可以参考miniob/src/observer/session/session_stage.h。
源码
weihan学长已经发给我们MiniOB往年源码,但是这是private的。在这个private里面有三个分支:main, feature_org和feature_ob。main分支是原始的文件,没有实现任何题目,但是可以编译成功;feature_org分支实现了一半的update分支,可以从这个分支开始做;feature_ob分支里面实现了必做题的3,4,5题和选做题2,3,4,6,7题。
在ob大赛微信群里,weihan学长发了miniob比赛.doc的文件,记录了他跟踪整个insert操作的过程,非常有参考价值。
编译
WSL下编译
代码的编译是个小问题,因为要在linux系统下编译。我平时写代码都是在windows上的,因为有合适的IDE,但是编译却要在linux下,就很不方便,因此我安装了WSL,写完代码之后拷贝到WSL的文件夹下C:\Users\zhou2\AppData\Local\Packages\CanonicalGroupLimited.Ubuntu20.04onWindows_79rhkp1fndgsc\LocalState\rootfs,然后在WSL下安装cmake来安装。
我的WSL是ubuntu系统的,所以安装cmake是这样的:
1 | sudo apt-get update # 更新软件源 |
还有个问题时,如果你直接将文件夹拷贝到WSL的对应位置,会出现权限问题,你可以这样:
1 | sudo su - |
就是给所有人加上所有权限,就没什么事了。
但是,需要安装支持c14的gcc版本,但是我在WSL下遇到了很多莫名其妙的问题,所以转战centos7虚拟机了。
centos7虚拟机下编译
关于如何在centos7下安装支持c14的gcc, g++, gdb以及高于3.6版本的cmake,可以看linux环境。
然后直接按照docs/how_to_build.md中的做法来做就可以了,只是在最终build miniob阶段,需要按照weihan学长的做法来编译。1
2
3cd build
cmake .. -DDEBUG=1 # 因为我们要用gdb调试
make && sudo make install
坑
- 注意最好不用weihan学长的
make -j all并行编译,可能会导致编译卡死问题,用make就好了。 - make过后会出现找不到
libjsoncpp.so.24的问题,去miniob/jsoncpp/build/lib/下面,拷贝所有文件到miniob/build/lib/下main。
词法与语法文件的编译
build文件夹中的Makefile貌似没有编译.l和.y文件的代码,要我们自己生成。参考OceanBase大赛miniob代码架构框架设计和说明
使用flex编译lex_sql.l文件,产生lex.yy.h和lex.yy.c文件:
1 | flex --header-file=lex.yy.h lex_sql.l |
架构
索引
我们可以从table.cpp中的Table::scan_record(Trx *trx, ConditionFilter *filter, int limit, void *context, RC (*record_reader)(Record *record, void *context)) 函数出发跟踪,了解索引是怎么工作的。
存储系统
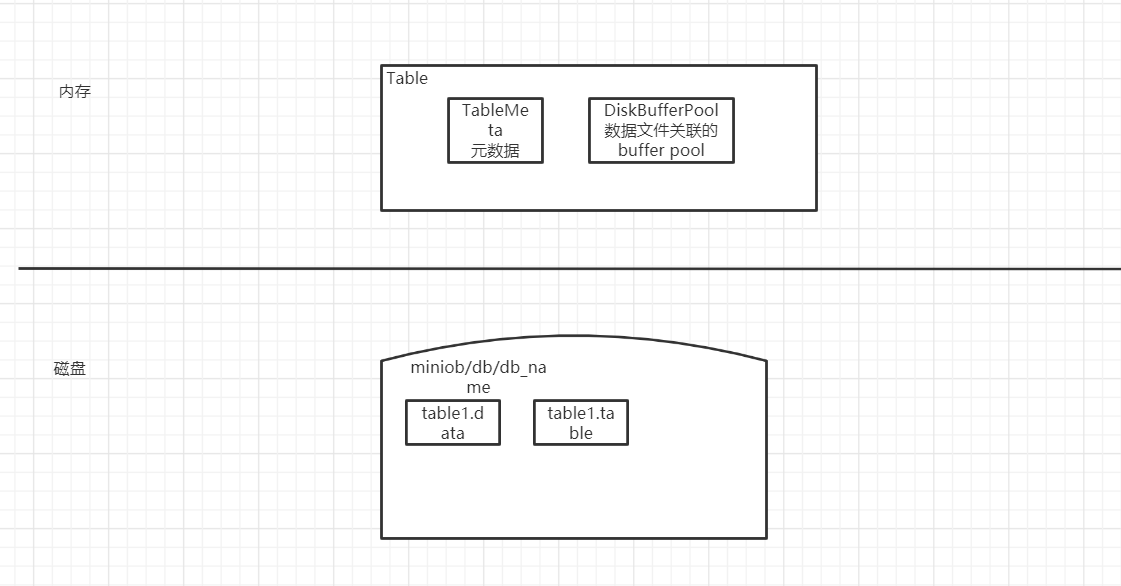
研究了DiskBufferPool这个类的数据结构,以及它和RecordPageHandler之间的关系。
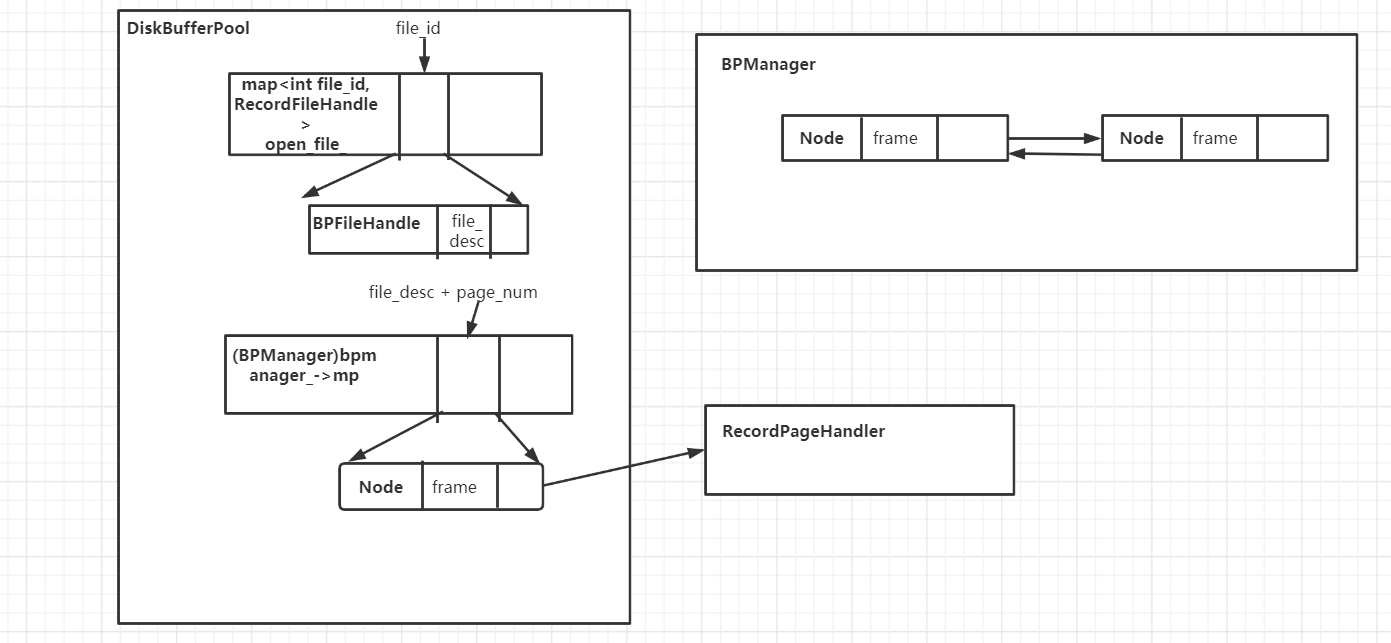
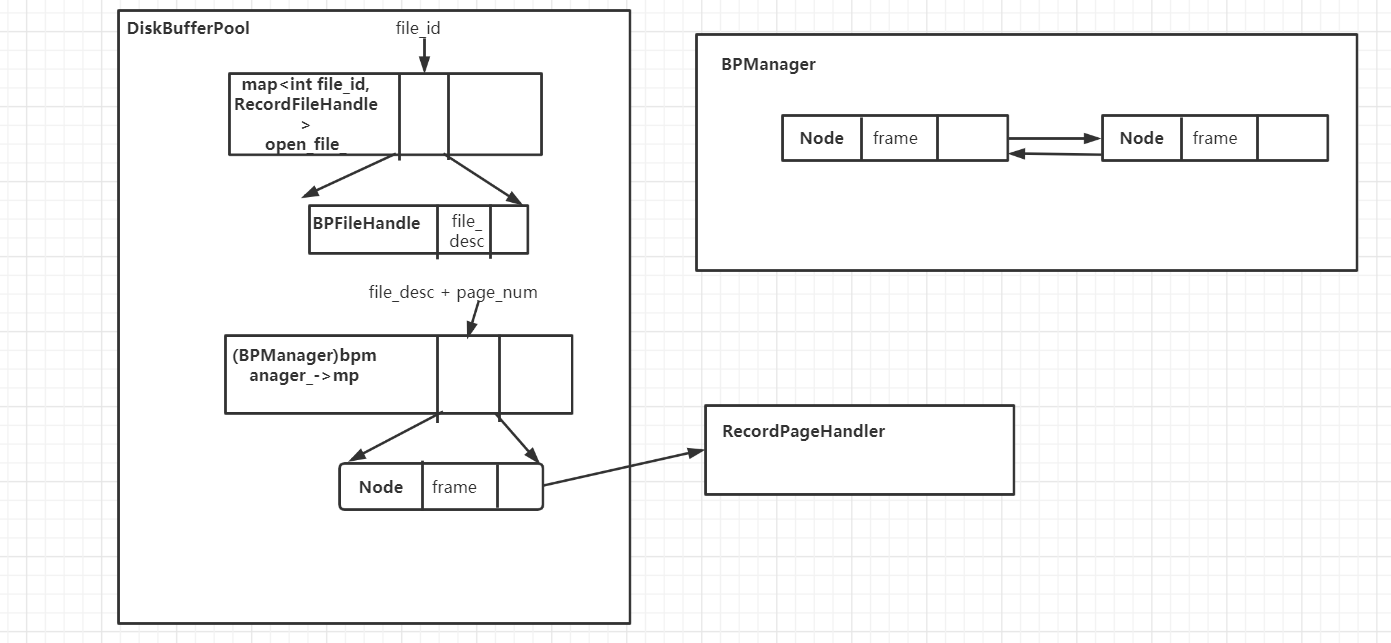
代码结构
rc.cpp里面有一句代码:
1 |
|
deps/common/seda/callback.h
1 | // deps/common/seda/callback.h |
当StageEvent::done()函数调用之后,会调用CompletionCallback::event_done()函数,它的代码是:
1 | // One event is complete |
(过期)observer/handler/handler_defs.h
1 | typedef struct _Condition { |
这个Condition结构体用于表示一个简单表达式,比如:
1 | 2>1 |
1 | // struct of select |
例如,如果有一个sql语句:
1 | select name,loc from person join department on person.dep=department.dep |
那么最终的Selects结构可能包含下述信息:
1 | nSelAttrs: 2 |
我们可以发现Selects中少了join这个表连接信息,and这个条件逻辑关系信息。
1 | // struct of insert |
这个Inserts结构表示向哪个表插入数据,以及插入哪些value,这里面的Value结构体实际上表示属性类型和属性值。从这里我们可以看到,miniob只支持指定全部属性值的元组插入操作,values中必须按顺序保存要插入元组的所有属性信息。
用一个union联合体表示所有可能的sql:
1 | // union of sql_structs |
最后的sqlstr就表示这个sql是哪种类型的sql query以及sql query的内容。
1 | // struct of flag and sql_struct |
observer/net/server.cpp
Server.accept()
更新ConnectionContext* client_context结构。
Server.start()
启动服务器,socket(), bind(), listen()函数都是在这里完成的。
storage/common/record_manager.h
这里定义了一个很重要的数据结构RID,表示一个元组在这个表文件中的位置,也称为元组的标识符。
1 | struct RID |
调试跟踪
创建表
在obclient下,执行sql: create table t(c1 int)
使用gdb调试,设置断点:b ParseStage::handle_request,然后一步一步看程序怎么执行的,里面的变量怎么变化的。
位置1:observer/sql/parser/parse_stage.cpp/ParseStage::handle_request(StageEvent *event)
event的动态类型是SQLStageEvent *,向上类型转换为sql_event。sql_event指向的内容是:
1 | {<common::StageEvent> = { |
sql_event->session_event_指向的内容是:
1 | {<common::StageEvent> = { |
其中的client_是observer/net/connection_context.h/ConnectionContext类型。
Query是observer/sql/parser/parser_defs.h/Query类型,这是语法分析的最终结果,用字符串来存储这个SQL查询的各方面信息,比如查哪些表,哪些属性,修改哪些属性之类的。
1 | RC ret = parse(sql.c_str(), result); |
parse()是observer/sql/parser/parse.h/parse(const char*, Query*)函数。
1 | return new ExecutionPlanEvent(sql_event, result); |
最后,返回ExecutionPlanEvent对象,这个也是StageEvent的子类,它与SQLStageEvent的关系是:
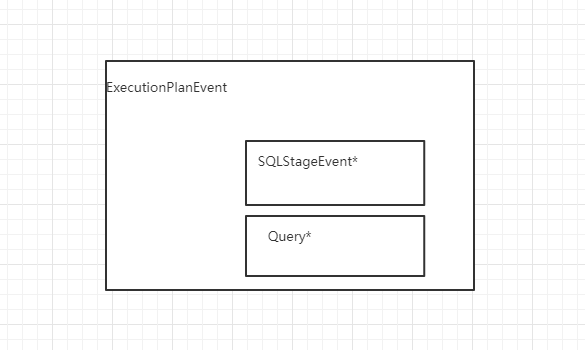
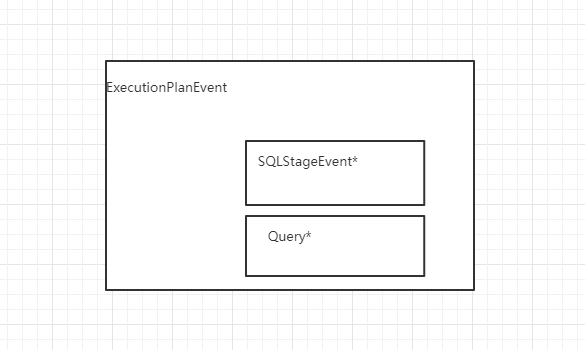
位置2: observer/sql/executor/execute_stage.cpp/ExecuteStage::handle_request(common::StageEvent *event)
我研究了一下这些StageEvent子类的关系:
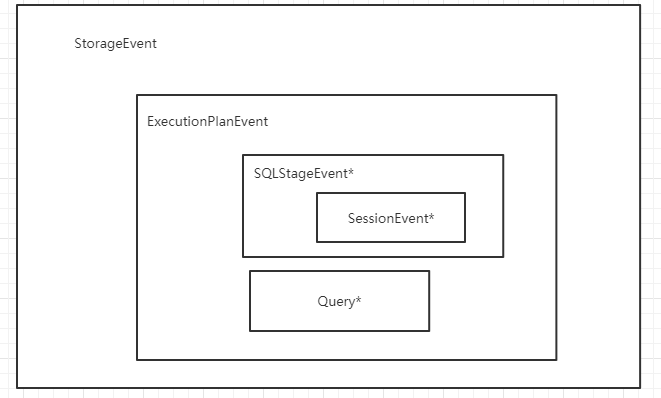
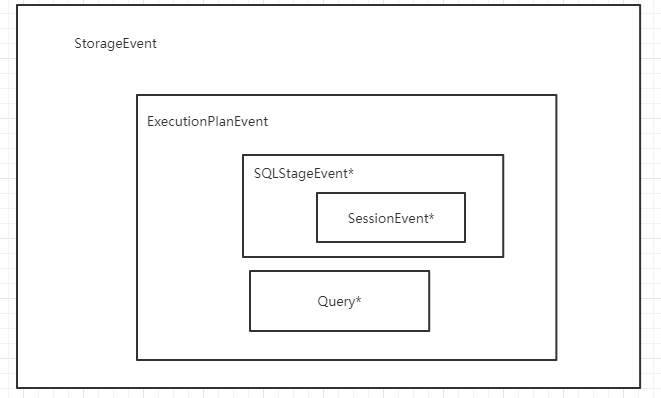
1 | StorageEvent *storage_event = new (std::nothrow) StorageEvent(exe_event); |
又进入了下一个Stage:
位置3:observer/storage/default/default_storage_stage.cpp/DefaultStorageStage::handle_event(Stage *event)
把这个DefaultStorageStage和CompletionCallback绑定起来,这步操作在ParseStage, ExecutionStage和DefaultStorageStage都会存在。
1 | StorageEvent *storage_event = static_cast<StorageEvent *>(event); |
然后,从event(动态类型是StorageEvent)中可以解析出很多关于这个SQL的信息:
1 | Query *sql = storage_event->exe_event()->sqls(); |
如果执行:print sql->sstr.create_table,会得到
因为我正在创建名字为t的表。
接着,到达代码:
1 | const CreateTable &create_table = sql->sstr.create_table; |
位置4:observer/storage/default/default_handler.cpp/DefaultHandler::create_table(const char *dbname, const char *relation_name, int attribute_count, const AttrInfo *attributes)
我们根据字符串类型的dbname找到Db*类型对象,Db的定义是:
1 | // observer/storage/common/db.h/Db |
如果执行gdb: print *db,输出
1 | $5 = {name_ = "sys", path_ = "./miniob/db/sys", |
接着,到达代码:
1 | return db->create_table(relation_name, attribute_count, attributes); |
位置5:storage/common/db.cpp/Db::create_table(const char *table_name, int attribute_count, const AttrInfo *attributes)
1 | std::string table_file_path = table_meta_file(path_.c_str(), table_name); |
执行gdb: print table_file_path,输出:
1 | $6 = "./miniob/db/sys/t.table" |
使用t.table记录名字为t的表的元数据。
执行gdb: print *attributes,输出:
1 | $7 = {name = 0x7fffd0001690 "c1", type = 2, length = 4} |
接着,到达代码
1 | rc = table->create(table_file_path.c_str(), table_name, path_.c_str(), attribute_count, attributes); |
位置6:/storage/common/table.cpp/Table::create(const char *path, const char *name, const char *base_dir, int attribute_count, const AttrInfo attributes[])
我们看下Table这个类关联了哪些数据:
1 | class Table { |
接下来,就要初始化.table文件,先在内存中初始化Table::table_meta_属性,然后将Table::table_meta_serialize到.table文件中。
1 | if ((rc = table_meta_.init(name, attribute_count, attributes)) != RC::SUCCESS) { |
table_meta_.init()函数意图初始化表的元数据,它创建这样一个数组,来表示一个表的所有属性(不仅包括用户定义的属性,比如c1,还包括系统需要的属性):
在table_meta_.init()函数下,执行gdb调试print fields_,查看fields信息,输出:
1 | fs.open(path, std::ios_base::out | std::ios_base::binary); |
将元数据持久化到文件中。
总结
Stage类和StageEvent类的关系已经大致看懂了,可能与SEDA事件处理框架有关:
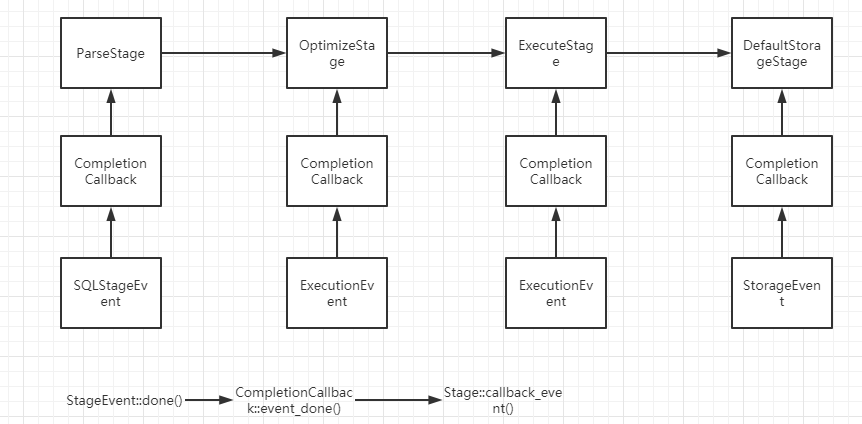
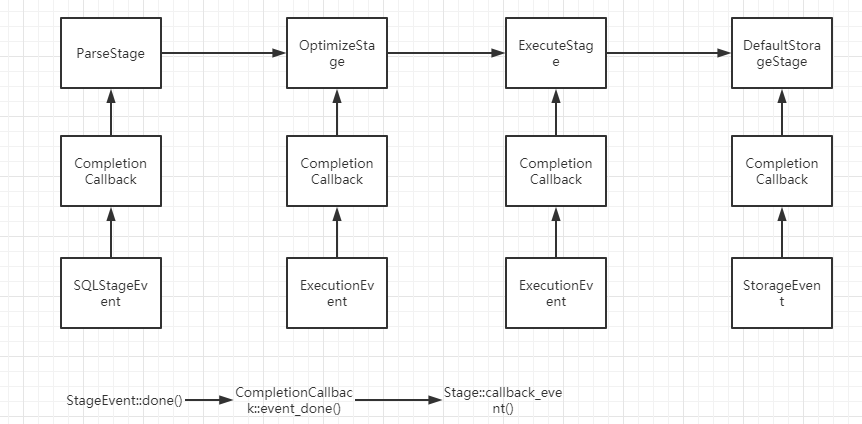
删除表
1 | // storage/common/db.cpp/Db::drop_table(const char *table_name) |
元组插入操作
下面是插入操作的整个过程以及用到的相关主要数据结构:
1 | 1. sql/parser/parser_stage.cpp/ParserStage::handle_event() |
位置1:在storage/common/table.cpp/Table::insert_record(Trx* trx, Record* record)
1 | rc = record_handler_->insert_record(record->data, table_meta_.record_size(), &record->rid); |
使用gdb命令:print *record_handler_,输出:
1 | $10 = {disk_buffer_pool_ = 0x4db810, file_id_ = 1, |
这里bitmap_就是位图,指示这个page种哪些slot有元组,哪些slot没有。
我们可以发现,RecordFileHandler, RecordPageHandler, DiskBufferPool有如下特点:
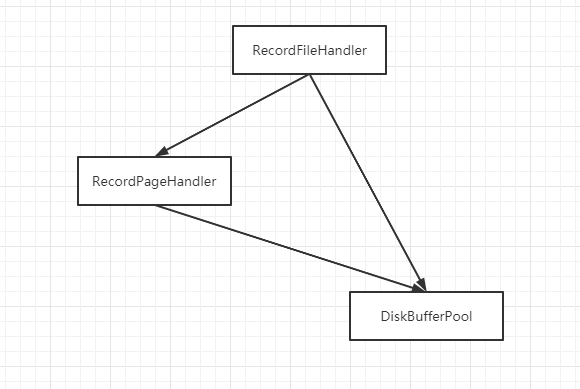
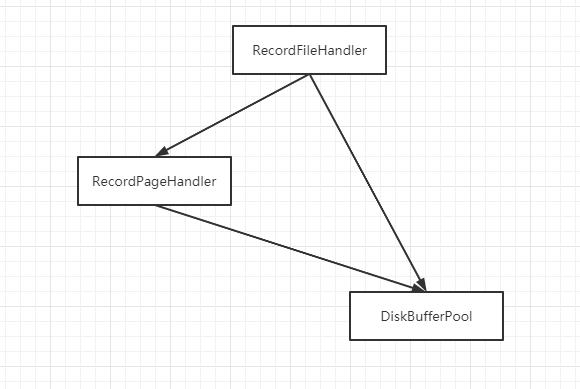
使用gdb命令:print *(record_handler_->record_page_handler_.page_handle_.frame),输出:
1 | $11 = {dirty = true, pin_count = 1, file_desc = 10, |
在RecordPageHandler中保存了完整的一个frame,它是一个Page数据以及状态数据(如,是否脏)的集合。
使用gdb命令:print *(record_handler_->record_page_handler_.page_header_),输出
1 | $13 = {record_num = 1, record_capacity = 252, record_real_size = 12, |
从这里可以看出,这个RecordPageHandler::page_header_保存的是page_num为1的这个Page的一些元信息,比如这个Page已经有1个元组了,总共可以保存252个元组,每个元组的实际大小是12字节,填充后是16字节,第一个元组的offset是56字节。所以,每个元组的大小比较固定,这个是12字节的原因是,我设置的这个表t只有一个int类型属性,再加上两个系统属性,总共3个属性,然后每个属性恰好是4字节,所以是12字节。
位置2:storage/record_manager.cpp/RecordFileHandler::insert_record(const char *data, int record_size, RID *rid)
执行到:
1 | if ((ret = disk_buffer_pool_->get_page_count(file_id_, &page_count)) != RC::SUCCESS) { |
于是step进get_page_count()这个函数:
1 | *page_count = open_list_[file_id]->file_sub_header->page_count; |
执行gdb命令:print *(open_list_[file_id]),输出:
1 | $19 = {bopen = true, file_name = 0x4e6190 "./miniob/db/sys/t.data", |
可以发现,保存在RecordFileHandler和RecordPageHandler的file_id_属性并不是真正的文件描述符,而是记录在DiskBufferPool中的open_list_属性中的下标,它指向的元素是BPFileHandle,表示一个文件的元信息。比如,上面的输出,有文件是否打开,文件名,文件描述符等。这些信息应该在创建表时就初始化好的。
执行gdb命令:print *(open_list_[file_id]->hdr_frame),输出:
1 | $20 = {dirty = true, pin_count = 1, file_desc = 10, |
执行gdb命令:print *(open_list_[file_id]->file_sub_header),输出:
1 |
我们可以看到,表文件的第一个Page是0号的,貌似不保存元组数据,因为我创建这个表后插入了两个元组,但是这里的page_count是2(一个0号,一个1号),而且上面的数据显示,这个两个元组保存在1号Page中。
然后,再返回到RecordFileHandler::insert_record(const char *data, int record_size, RID *rid)。
1 | ret = record_page_handler_.init(*disk_buffer_pool_, file_id_, current_page_num); |
上述代码从disk_buffer_pool中找到一个对应的page的视图,包括page的数据和头部都是视图,而不是拷贝。具体的讲解在get_this_page()函数中。
1 | return record_page_handler_.insert_record(data, rid); |
在这个RecordPageHandler::insert_record()函数里,只将元组插入到缓存区中,但是并没有存储到磁盘文件中。这个是因为,当buffer不够用的时候,才会把脏页给刷到磁盘中,这个miniOB没有后台刷进程。
位置3:storage/default/disk_buffer_pool.cpp/DiskBufferPool::get_this_page(int file_id, PageNum page_num, BPPageHandle *page_handle)
在RecordFileHandler::insert_record()里面需要根据文件描述符和页号找到对应的BPPageHandle,而要找到这个,最重要的是要找到frame,所以要分析这个函数。
首先得到BPFileHandle *file_handle:
1 | BPFileHandle *file_handle= open_list_[file_id]; |
然后根据文件描述符和页号得到frame:
1 | Frame *f = bp_manager_.get(file_handle->file_desc,page_num); |
step进storage/default/disk_buffer_pool.h/BPManager::get(int file_desc, PageNum page_num),看看里面是什么:
1 | Node *node = getNode(file_desc,page_num); |
这个BPManager::getNode()函数是在搜索BPManager::mp映射,找到(file_desc, page_num)对应的Node。系统中的所有frame是连接成一个链表的,因此Node包含frame,以及一些链表指针,这样设计是为了实现LRU;然后,将这个Node放到链表的头部,实现了LRU。
为了更好地理解BPManager是干什么的,看下它的源码:
1 | // storage/default/disk_buffer_pool.h |
BPManager就是管理disk buffer的,将很多frame连接成一个链表,然后设置buffer的最大size是50,最大文件打开数是50。
然后回到DiskBufferPool::get_this_page()函数,从上面可以知道,BPManager::get只能在buffer中找页。如果通过BPManager::get能够得到frame,就直接返回成功;否则,就从磁盘中读取页并设置一个新的frame,函数是BPManager::load_page(PageNum page_num, BPFileHandle *file_handle, Frame *frame),然后将这个frame加入到BPManager管理的链表的头部,但是若链表没有空闲空间了,需要考虑evict一个页。
位置4:storage/trx/trx.cpp/Trx::insert_record(Table *table, Record *record)
在插入元组后,向Trx中也插入元组。
执行gdb命令:print record->rid,输出:
1 |
1 | insert_operation(table, Operation::Type::INSERT, record->rid); |
在Trx类中有一个属性:operations_,它记录了每个Table的所有Operation,这个是type和rid的组合,type表示这个Operaion是增删改的哪个,rid表示这个Operation操作的是哪个元组,因为rid是元组标识符嘛。
感觉这个Operations_就像一个轻量级的日志。
位置5:storage/common/table.cpp/Table::insert_entry_of_indexes(const char *record, const RID &rid)
插入元组后,理所当然地要更新索引。
但是我发现Table::indexes_中并没有任何Index对象,说明索引没有自动创建。
1 | // event/sql_event.h |
1 | // event/execution_plan_event.h |
1 | // storage/common/record_manager.h |
总结
研究了DiskBufferPool这个类的数据结构,以及它和RecordPageHandler之间的关系。
RecordPageHandler是DiskBufferPool的切片(视图)。
元组查找
1 | 1. sql/executor/execute_stage.cpp/ExecuteStage::do_select(const char *db, Query *sql, SessionEvent *session_event) |
最重要的是:
位置1:sql/executor/execute_stage.cpp/ExecuteStage::do_select(const char *db, Query *sql, SessionEvent *session_event)。
这个代码优点难理解。在db和Query信息已知的情况下执行查找。
比较重要的数据结构:
1 | // sql/executor/tuple.h |
从上面可以知道:TupleSet就是保存同一个表的很多元组。而Tuple就是保存了很多TupleValue的指针。画图表示:
1 | // sql/executor/execution_node.h |
SelectExeNode只能够处理与某一个表相关的condition以及查询函数,不支持涉及到多表的查询。比如说,SelectExeNode可以表示一个表t,以及查询条件t.c1<10,但是不能表示t.c1 < t2.c1,因为conditon只能涉及一个表。
1 | // storage/common/condition_filter.h |
SelectExeNode初始化时需要ConditionFilter,它比Conditon更精确地描述了条件,以及涉及的每个属性。
位置2:storage/common/table.cpp/Table::scan_record(Trx *trx, ConditionFilter *filter, int limit, void *context, RC (*record_reader)(Record *record, void *context))。
重要的结构是:RecordFileScanner
1 | RecordFileScanner scanner; |
RecordFileScanner的结构是:
1 | // storage/common/record_manager.h |
使用索引查找
1 | 1. table.cpp/Table::scan_record(Trx *trx, ConditionFilter *filter, int limit, void *context, RC (*record_reader)(Record *record, void *context)) |
聚合查找max
执行下述SQL语句:
1 | select max(salary) from school; |
位置1:sql/executor/execute_stage.cpp/ExecuteStage::do_select(const char *db, Query *sql, SessionEvent *session_event)。
1 | const Selects &selects = sql->sstr.selection; |
这行代码会解析出Query中的Selects结构,得到SELECT查询的信息。
1 | (gdb) print selects.attributes[0] |
1 | Tuple agg_res; |
难点
seda事件处理框架
代码阅读
代码阅读感觉很难,以后我们可以几天交流一次,毕竟如果有大佬已经看懂了,那么我就可以偷懒了,省点时间。
性能优化
这部分应该是要提前考虑的点,我们可以:
- 系统学习查询执行,查询优化相关的知识,比如
数据库系统概念,数据库系统实现, 以及参赛宝典 - 和weihan学长交流
可以有哪些优化:
- 当where条件必为false时,可以直接返回空集,比如
where id=null。 - 当count(1)时,可以直接返回tupleset大小。
错误
- 自豪的drop table还没有实现好。没有删掉table.data文件
- 退出miniob后,select创建的表发现no data。
- 元数据校验支持多表校验。主要查询
t.col中t有没有col属性。 - 聚合查询做更多的校验,比如字符串不能算平均值
做
- 把check_insert_stat拆分
- 基于tuple set做聚合
- update没有做完整的校验,只对set的date字段做了校验
- 要在TupleSchema中重写print()函数。还要添加一个agg属性,表示是不是聚合属性。还要判断聚合与属性是否匹配,比如AVG(string)。
我把代码大改了,元数据校验又加了些东西,TupleSchema也改了很多,这部分和多表以及聚合都相关,目的是,通过调用TupleSchema的print()函数就可以精确无误地输出多表,单表,聚合属性以及group by的属性头。比如id | max(birthday)。
对聚合属性进行合法性校验
update也要做合法性校验;
聚合属性的浮点数的输出规范
date最早限制是1970-01-01
drop table, update table, date都要考虑索引