
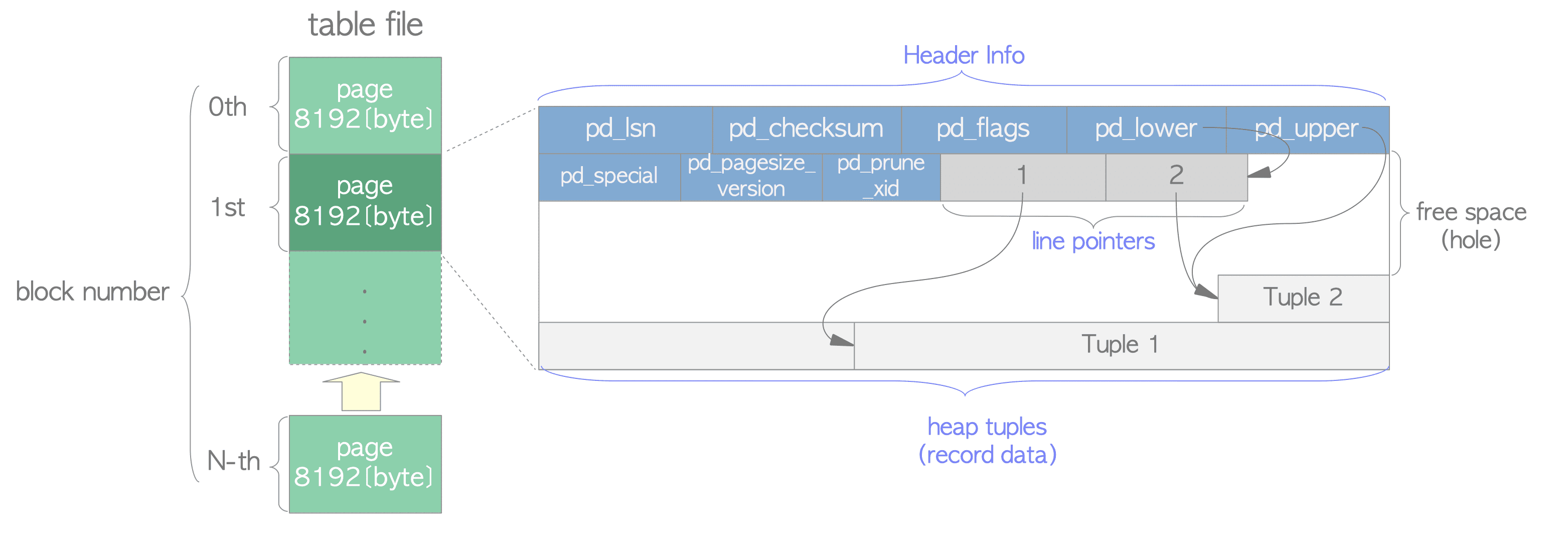
Internal Layout of XLOG Record(version 9.5 or later)
WAL的技术博客来源于interdb Write Ahead Logging,PostgreSQL重启恢复—-XLOG 1.0,PostgreSQL重启恢复—-XLOG 2.0
XLOG Record的data portion可以分为header part和data part。
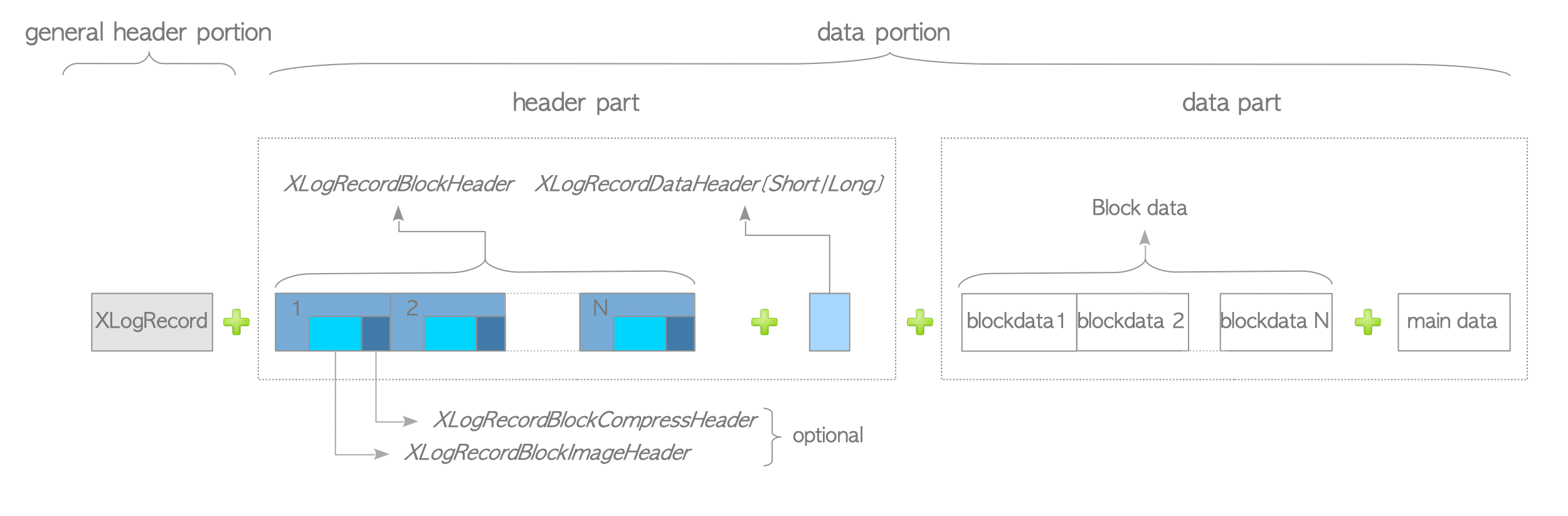
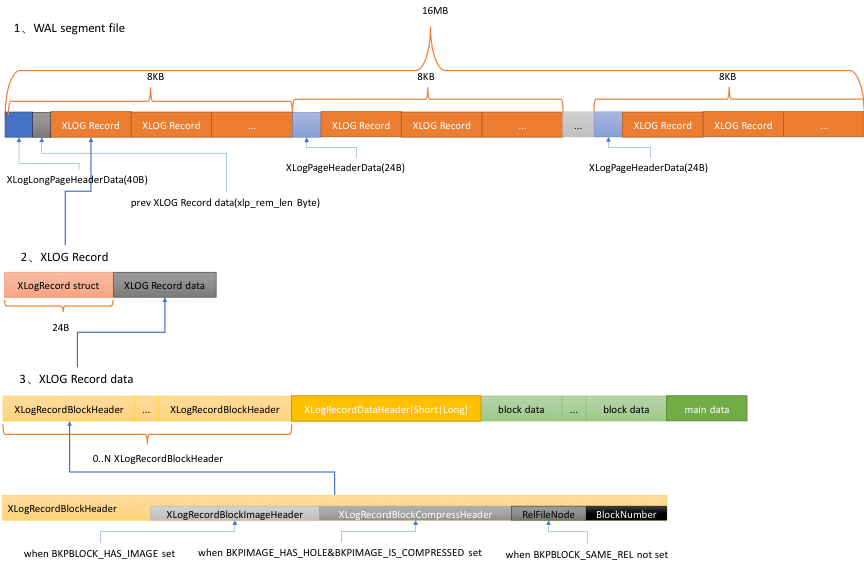
下面是XLOG Record的例子,以INSERT操作为例:
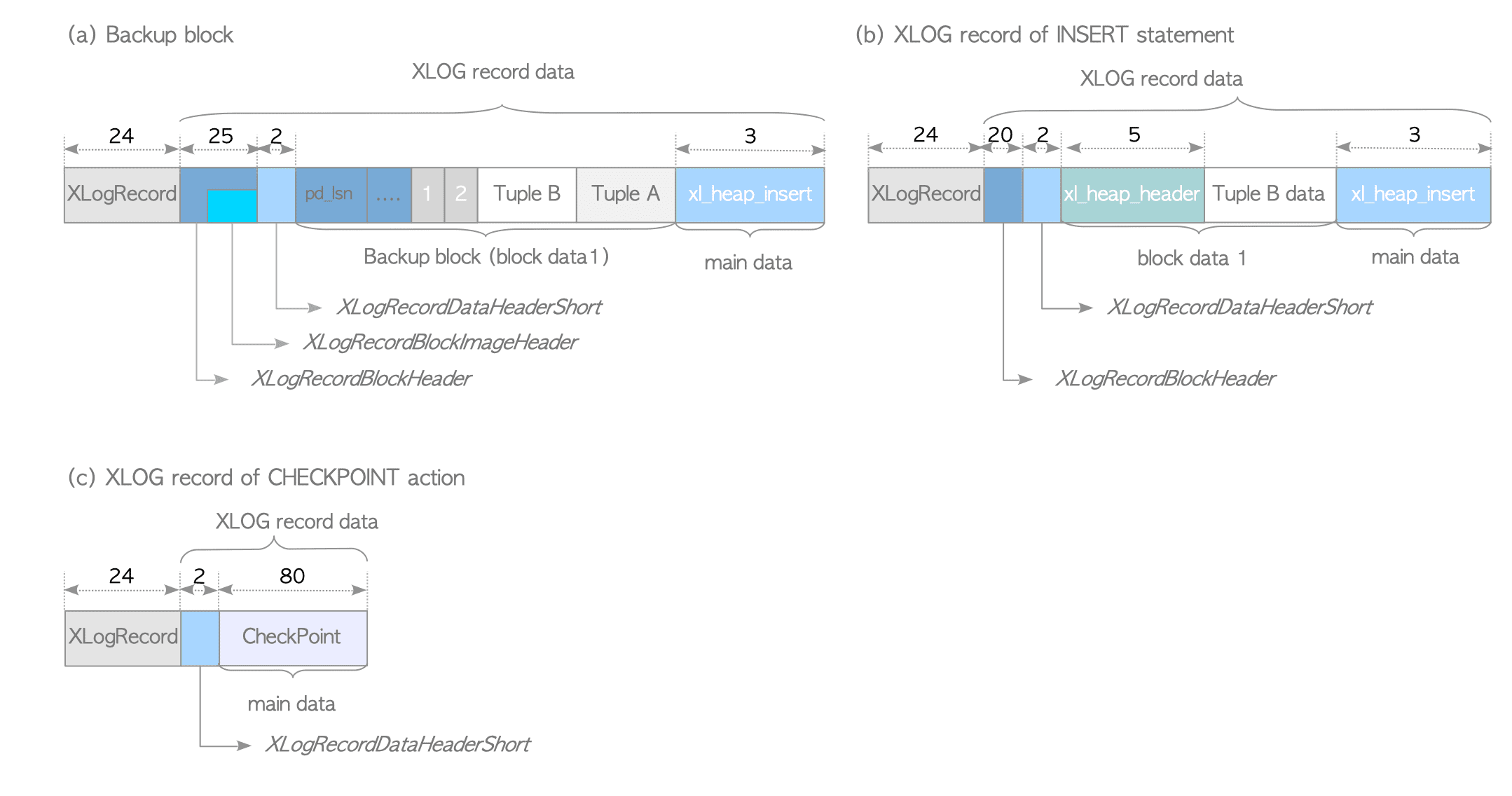
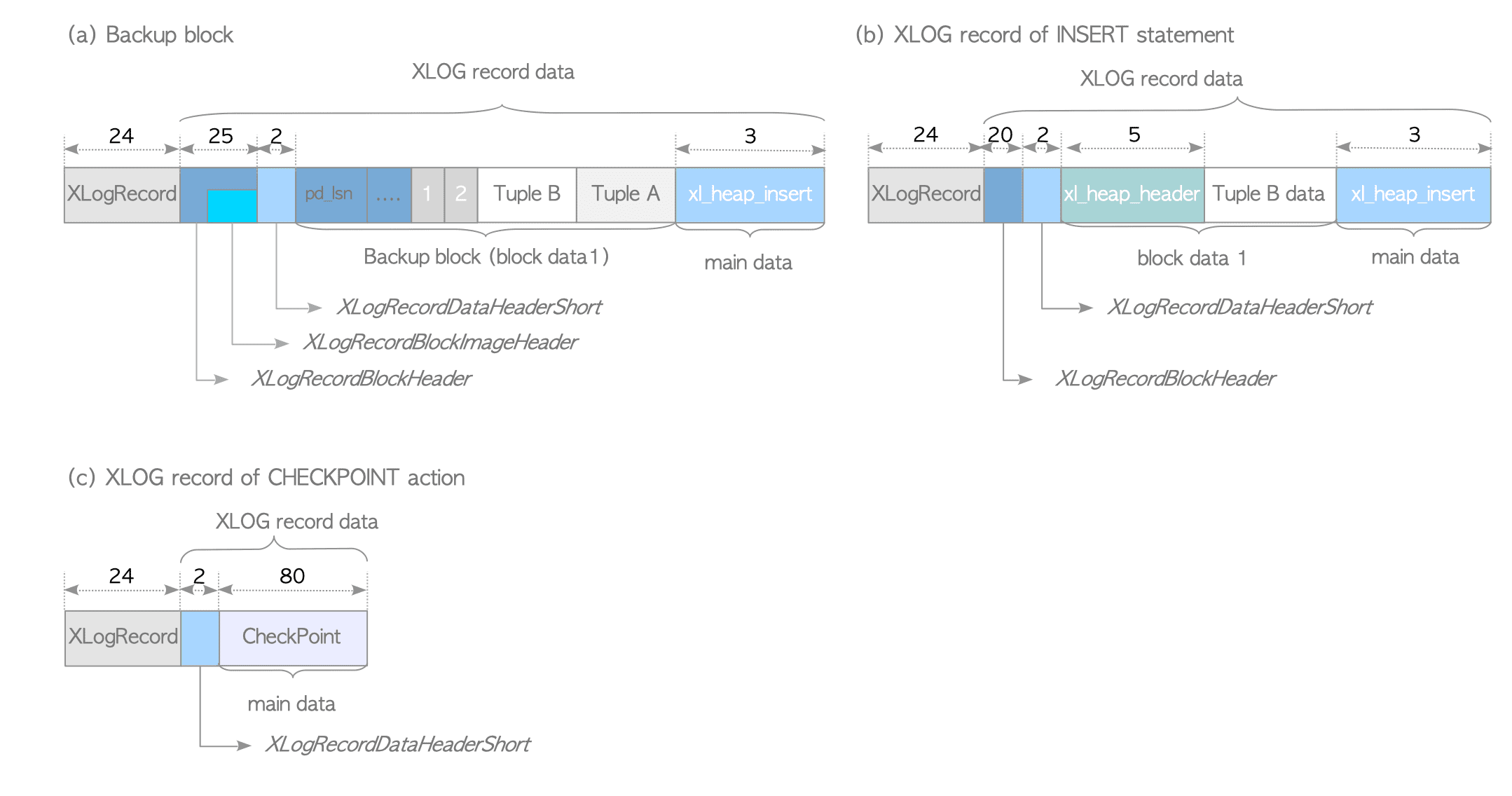
一般情况下,只有一个XlogRecordBlockHeader和block data,在checkpoint的XLOG Record中,甚至连一个都没有。
数据结构
XLogRecord
1 | include/access/xlogrecord.h/XLogRecord |
1 | /* |
- xl_rmid表示资源管理器号,表示当前正在做的是什么操作,当后面恢复的时候就可以调用相应的函数来redo,比如对于insert操作,它的日志的xl_rmid就是RM_HEAP,xl_info就是XLOG_HEAP_INSERT, 后面redo时就用RM_HEAP::heap_xlog_insert()函数;
RelFileNode
1 | /include/storage/relfilenode.h/RelFileNode |
1 | /* |
RelFilNode唯一地标识了一个relation。
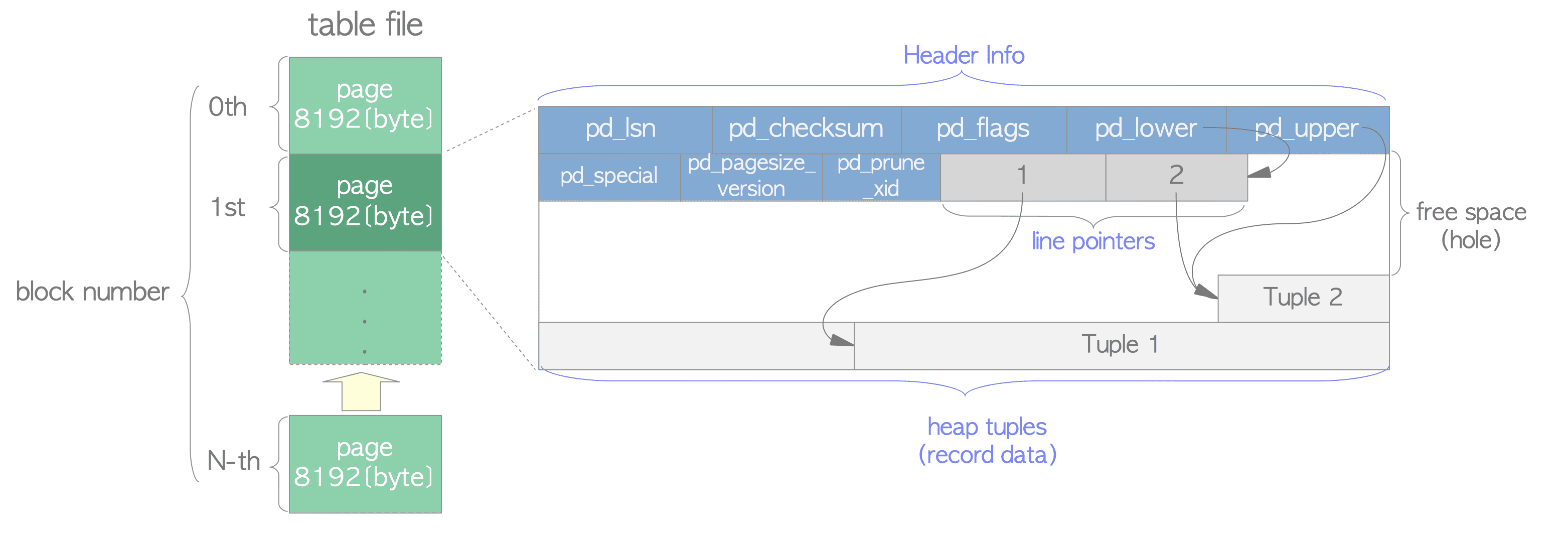
xl_heap_head
存储了heap_tuple的部分头部信息,比如t_infomask2,t_infomask,t_hoff;
1 | /* |
不用将整个HeapTupleHeaderData都写入XLOG,HeapTupleHeaderData中的很多信息都可以重构或者不需要重构。所以只用存放一些必要的信息,而xl_heap_header就用于记录这些必要信息。
main data(xl_heap_insert)
当执行INSERT语句时,产生的XLOG的main data部分就是xl_heap_insert类型。存储了该元组在物理块中的偏移(是ItemIdData,也即ItemPointer,在页面中的偏移,例如,这个元组在页面中对应第2个ItemPointer,那么在xl_heap_insert中就存储2,而不是元组实体在页面中的偏移);以这种方式记录的日志称为物理逻辑日志;如果记录的是元组实体的偏移,就称为物理日志;
1 | struct xl_heap_insert{ |
Page-oriented Log
在明白了XLOG的结构之后,我们就可以来解释什么叫做Page-oriented Log了。从XLOG的信息中,我们不难发现,XLOG描述了一条元组应该被写入到哪个页面的什么位置。从heap_insert的流程中,我们也不难发现,当一条元组写入数据页面后,我们就立即为这次写入操作生成一个XLOG,并写入log buffer。也就是说XLOG描述了页面中的数据变化,这就是Page-oriented Log。与之相对应的是逻辑日志(logic log),逻辑日志通常只是记录一条SQL语句,在redo时,会重新执行这条SQL语句。所以对于Page-oriented Log而言,在redo时元组总是写入到先前写入的那个页面,但对于逻辑日志,redo时的写入就很随意了。
对于Page-oriented Log又分为物理日志和物理逻辑日志两种。前面提到过,对于物理日志会记录元组插入页面中的物理位置(ItemIdData中lp_off的值),而对于物理逻辑日志,只记录元组插入页面中的逻辑位置(ItemIdData自身的偏移)。
对于物理日志而言,由于记录了元组的实际偏移,所以在redo时只用定位到实际位置,然后直接覆盖原有元组(不管元组有没有落盘),这种操作本身是具有幂等性的,不论执行多少次redo结果都一样。但这个方式有一个问题,就是一旦块做了整理(比如:vacuum操作)那么元组的物理位置会发生变化。为了保持精确的物理信息,整理也会产生大量物理日志,这非常影响性能。
所以PostgreSQL采用的是物理逻辑日志,所谓物理是指记录了元组实际插入的数据页,所谓逻辑具体写入到数据页中的什么位置是一个逻辑的值。这样在vacuum的时候只需要保持ItemIdData的位置不变,就没有任何影响。但是物理逻辑日志本身不具有幂等性,如果不加任何处理直接多次redo的话,就会写入多条数据。所以对于物理逻辑日志需要一种手段来判断该XLOG是否需要在对应页面中进行redo操作,这也就是所谓的LSN。
partial write
操作系统会保证一个磁盘块落盘的原子性,但是PG中一个页是两个磁盘页,因此就不能保证在落盘时不出现问题。如果一个页面在落盘的过程中,数据库发生了崩溃,那么这个页面就可能出现一部分落盘,而一部分没有落盘的情况,也就是部分写(partial write)。对于一个部分写的页面,我们是没办法用XLOG来恢复的。这个是为什么呢?
首先,第一点,PG是支持物理逻辑日志的,也就是日志不具备幂等性,重复恢复一个相同的日志,加入恢复相同的插入数据日志,则会在数据库中插入两个相同的元组。
第二,,每一个页面都记录了一个LSN,称为Page LSN(类似于ARIES)。Page LSN表示,所有LSN小于等于Page LSN的XLOG对应的操作都已经落盘。那么在重启恢复时,所有LSN小于Page LSN的XLOG都不会在该页面中做redo操作。但是这一切都必须有一个前提,那就是页面必须完成落盘。如果发生partial write,那么就会出现块头正确落盘,而块数据没有正确落盘,从而无法保证Page LSN之前的所有操作都正确落盘,此时即使知道了这个page是坏的,也不能通过日志恢复(因为之前的第一点)。
为了解决这个问题,PostgreSQL提供备份区块的方式。这种方式的思路是,对于checkpoint 之后,页面的第一次修改,会在 XLOG中记录页面的全部数据。我觉得这是一种undo操作,不过是在极端情况下(数据块没有正确落盘)才会执行的undo。
Writing of XLOG Record
我们以INSERT操作为例,解释PG中Writing of XLOG Record的过程。输入下述SQL语句。
1 | INSERT INTO tbl VALUES ('A'); |
顺序流程
这个语句会触发exec_simple_query()函数,接下来的流程是:
1 | exec_simple_query() @postgres.c |
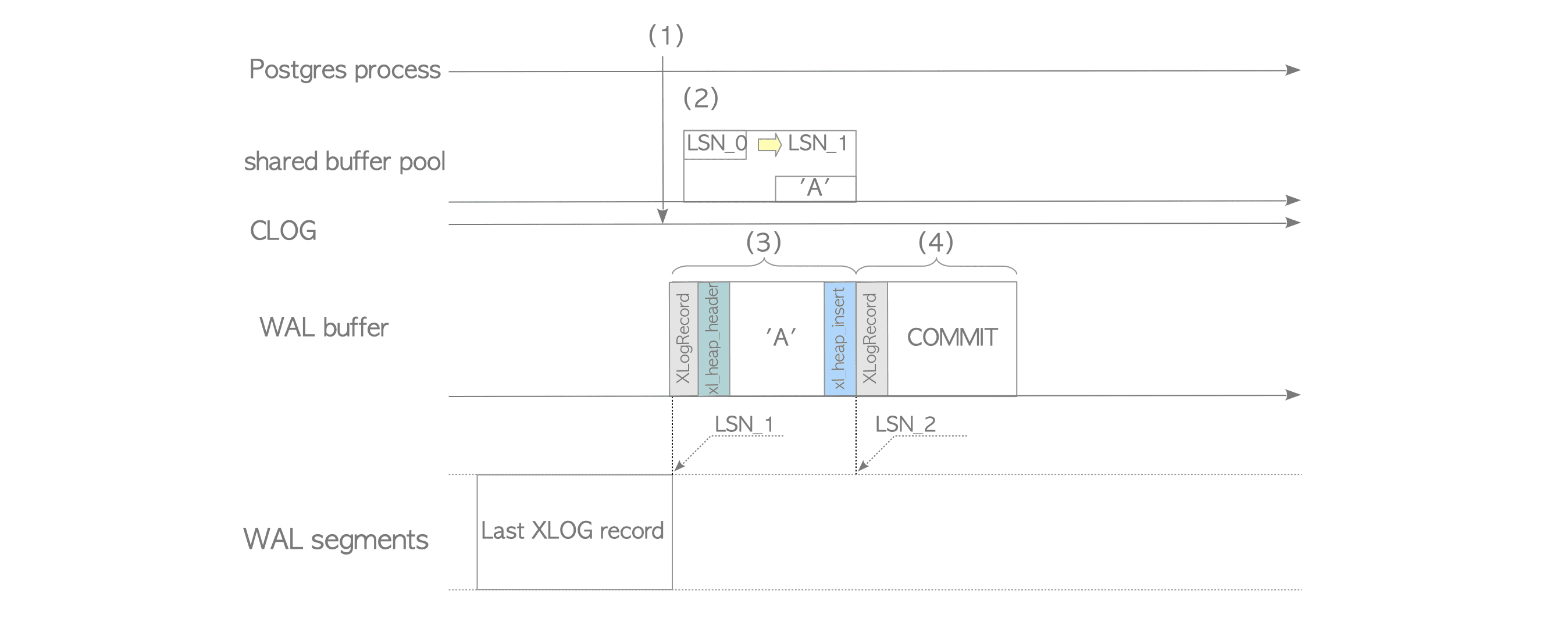
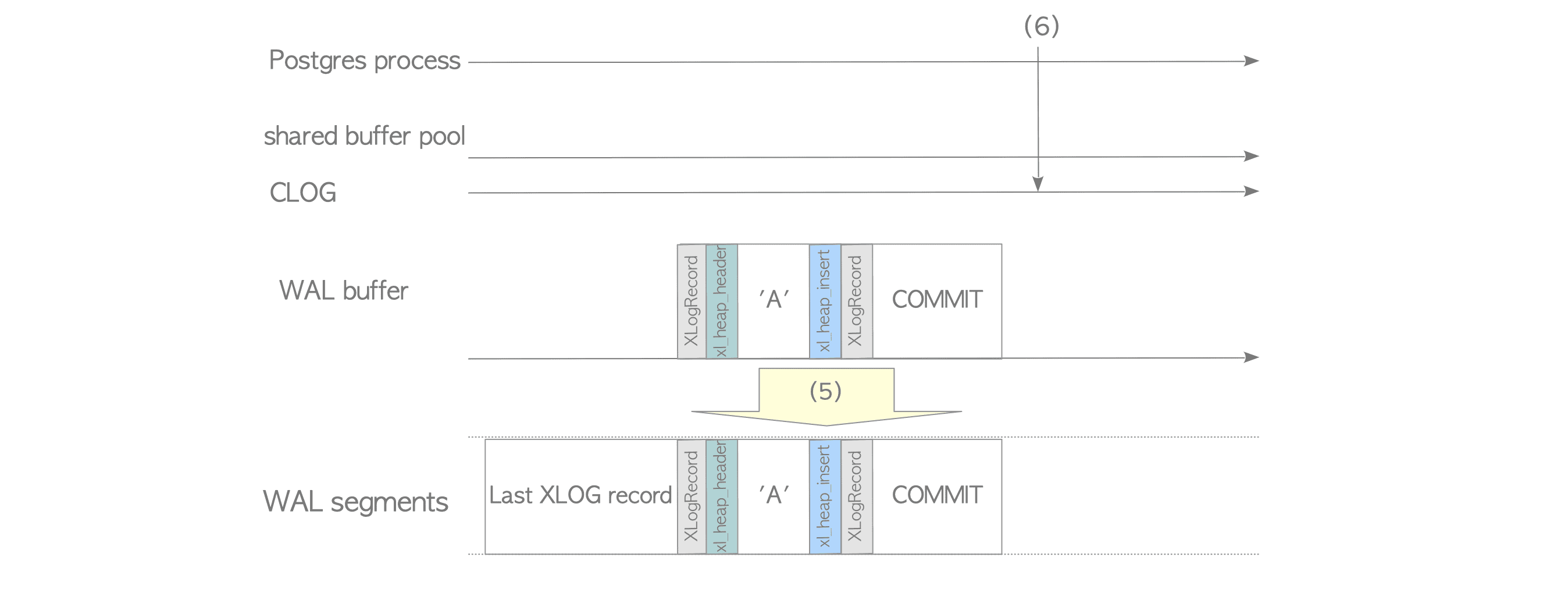
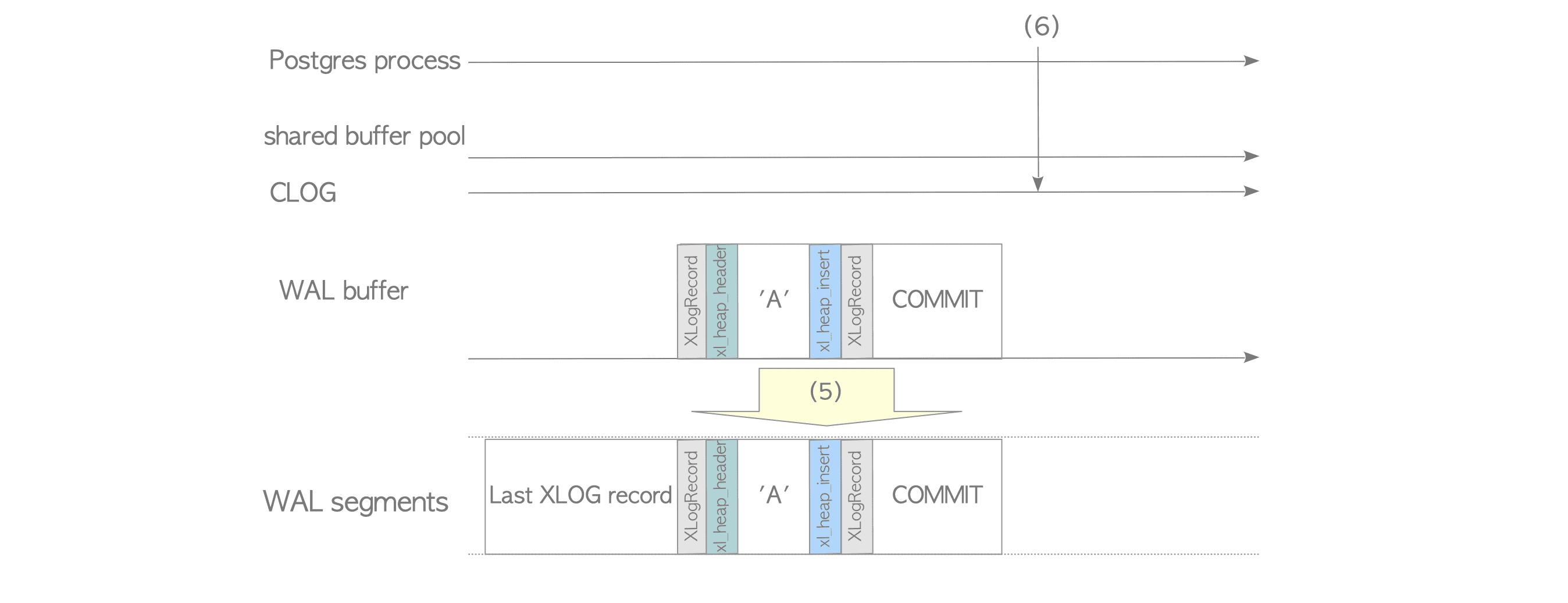
关于CLOG,可以看这张图:
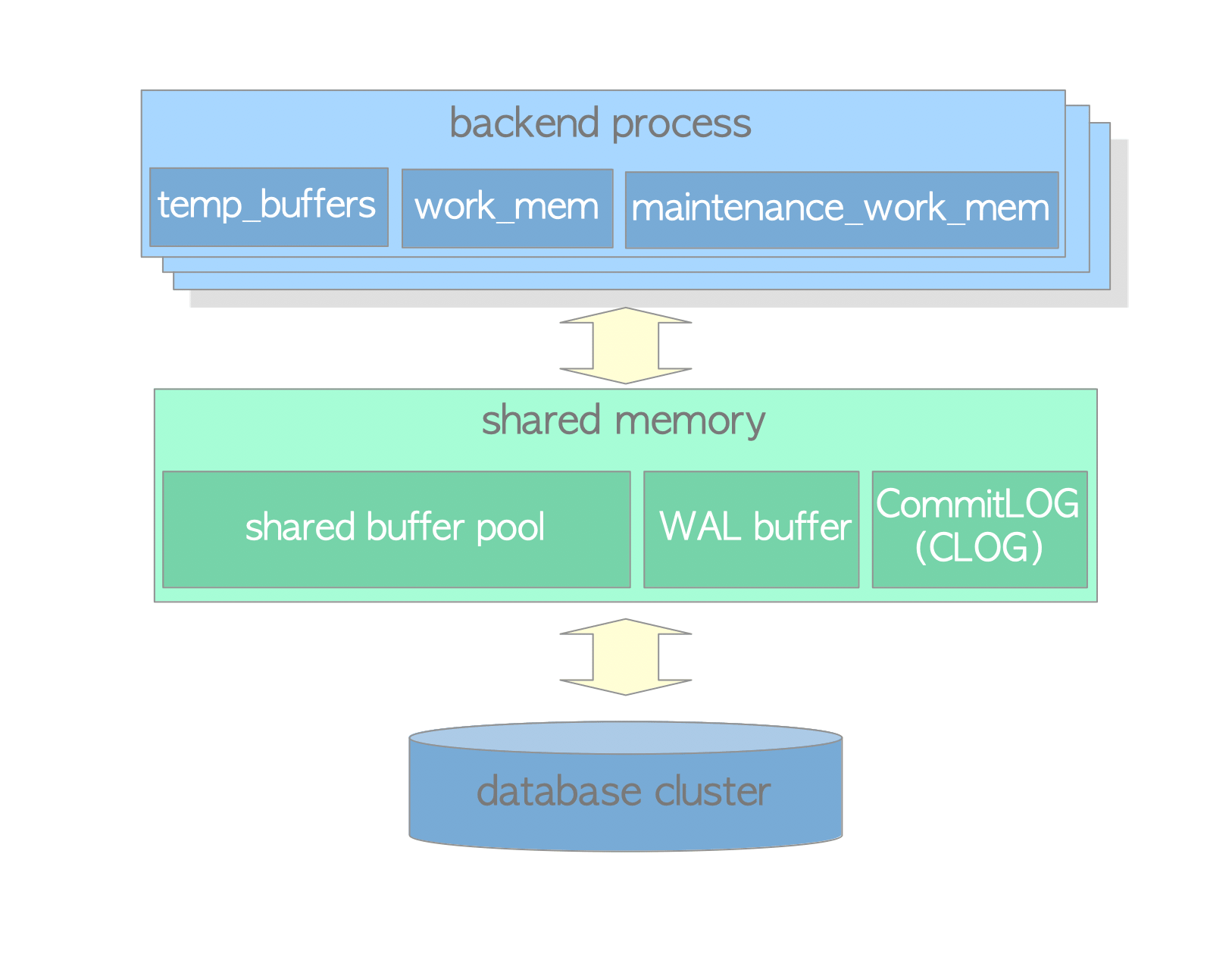
XLogWrite() @xlog.c 函数是将WAL buffer中的数据flush到WAL segments中,它可能在一下几种情况下被调用:
- One running transaction has committed or has aborted.
- The WAL buffer has been filled up with many tuples have been written. (The WAL buffer size is set to the parameter
wal_buffers.) - A WAL writer process writes periodically.
If one of above occurs, all WAL records on the WAL buffer are written into a WAL segment file regardless of whether their transactions have been committed or not.这句话说明flush到wal segments中的日志可能是没有commit日志的,但是PG又是只支持redo日志,这就意味着可能在recover阶段检测:从redo point点开始哪些事务的日志是需要redo的。
Write sequence of XLOG Records
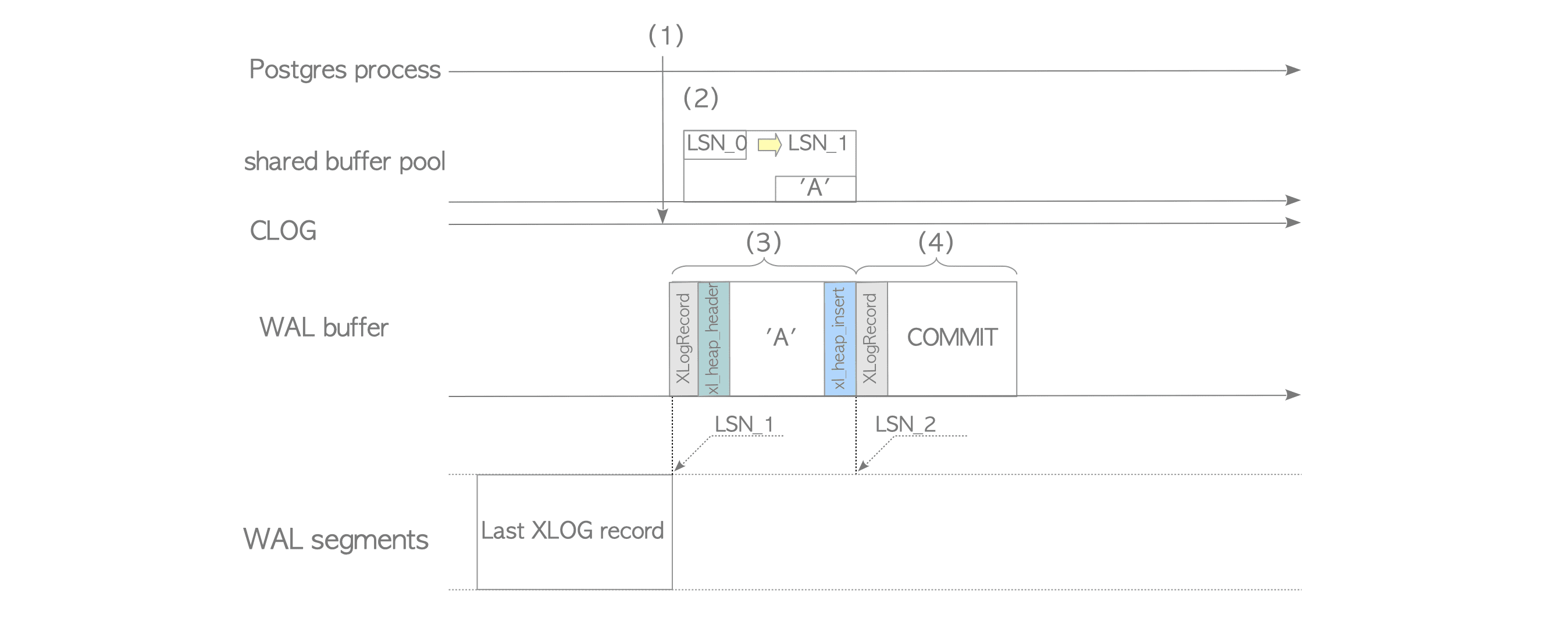
调用栈
1 | 1. /backend/access/heap/heapam.c/heap_insert(Relation relation, HeapTuple tup, CommandId cid,int options, BulkInsertState bistate) |
heap_insert() @heapam.c
1 | /backend/access/heap/heapam.c/heap_insert(Relation relation, |
1 | /* XLOG stuff */ |
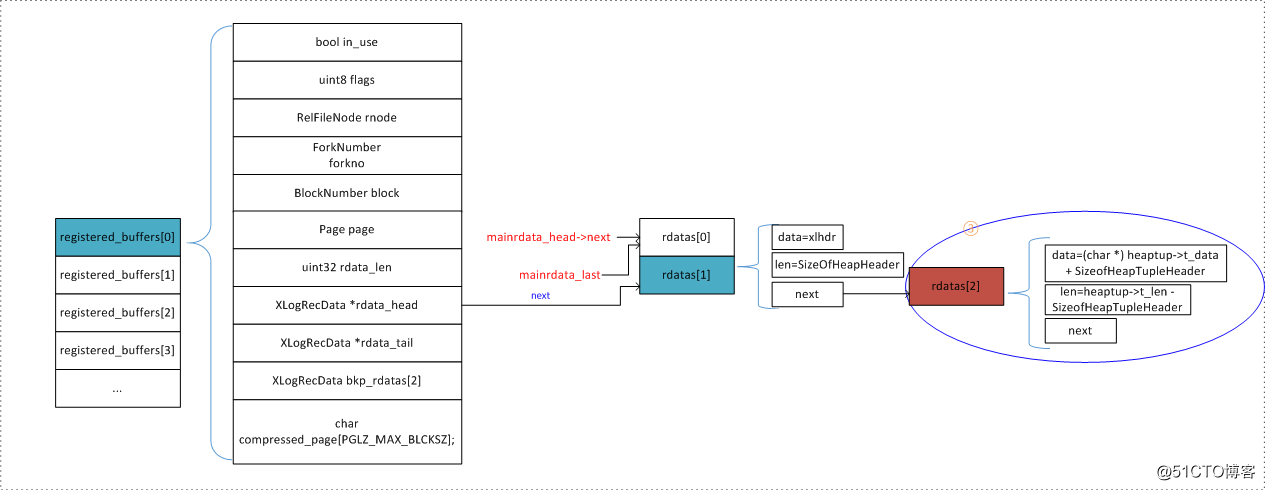
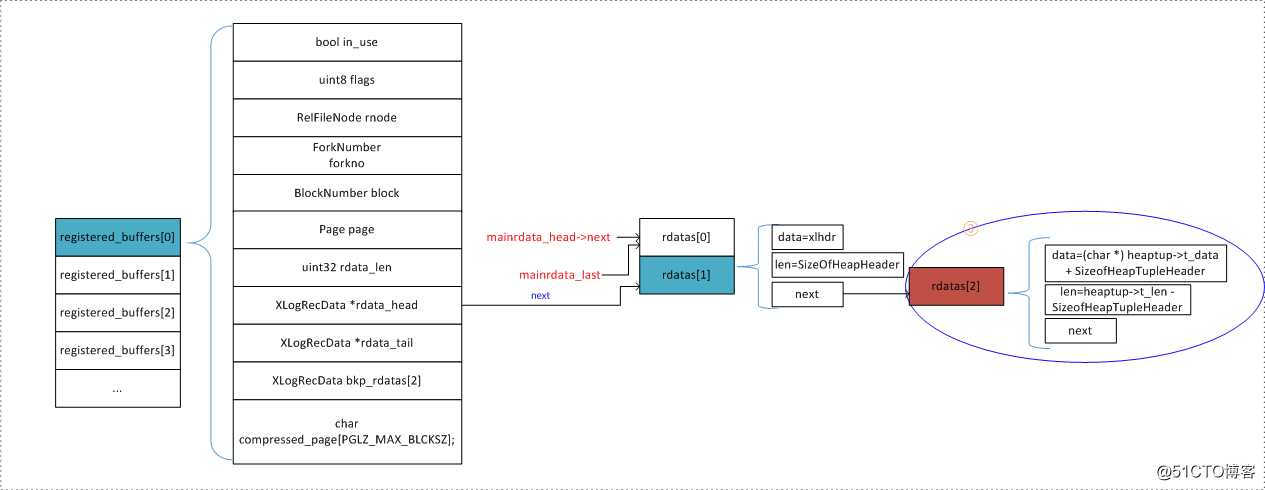
关于注册数据,可以看这张图直接地了解一下
XLogInsert() @xloginsert.c
1 | /backend/access/transam/xloginsert.c/XLogInsert(RmgrId rmid, uint8 info) |
在heap_insert()中主要已经注册了下述数据:
1 | //xlrec为xl_heap_insert结构体 |
通过注册流程,我们现构建了XLOG如下部分的数据(绿色为已构建的,红色为尚未构建的):
XLogRecord+XLogRecordBlockHeader+RelFileNode+BlockNumber + mainrdata_len +
xl_heap_header+ 实际元组数据+ xl_heap_insert
- xl_heap_insert在mainrdata链表中。
- RelFileNode+BlockNumber+xl_heap_header+ 实际元组数据在regbuf链表中。
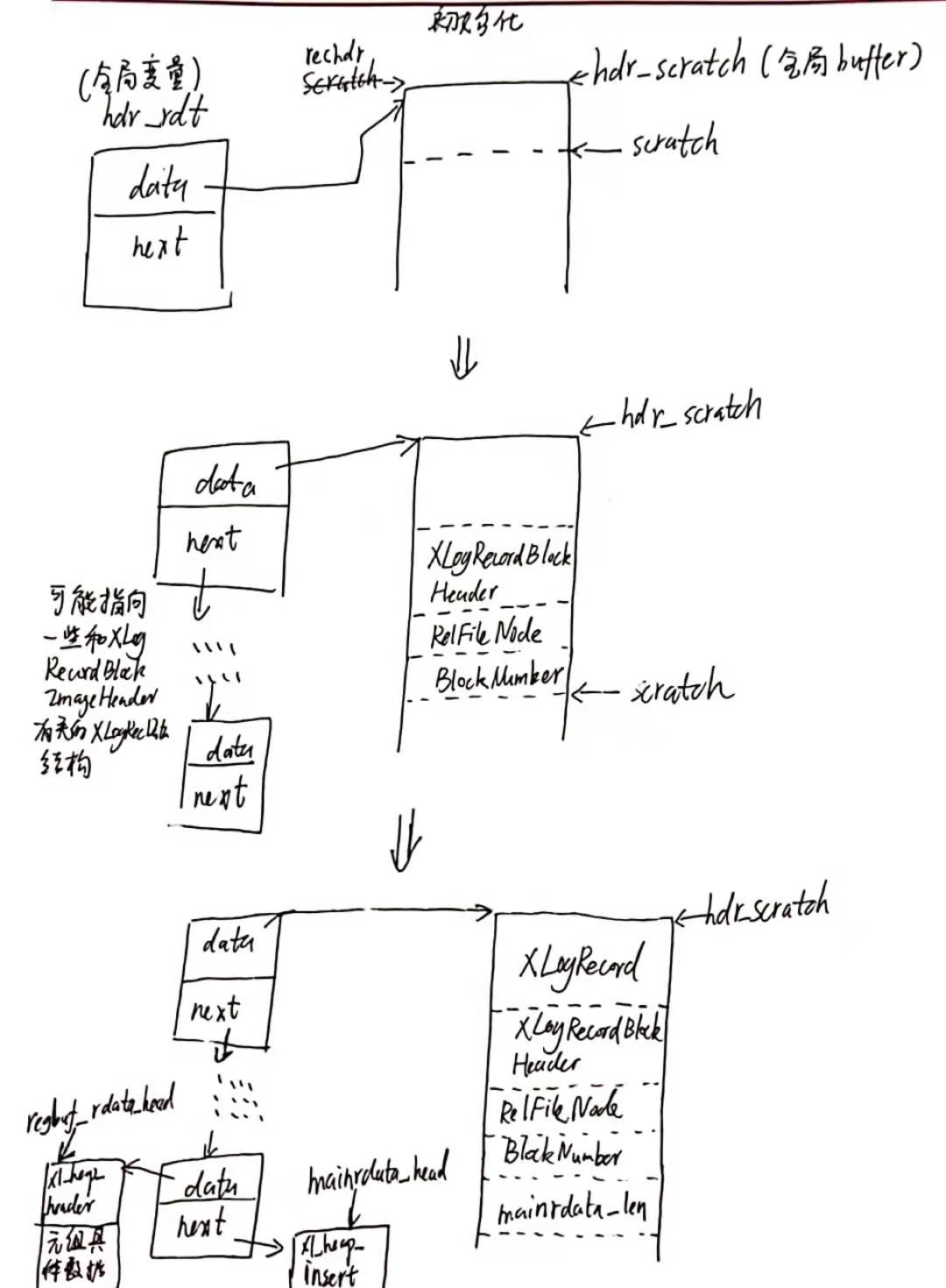
XLogRecordAssemble() @xloginsert.c
1 | /backend/access/transam/xloginsert.c/XLogRecordAssemble(RmgrId rmid, uint8 info, |
XLogRecordAssemble() 负责获取前面红色部分的数据:XLogRecord、XLogRecordBlockHeader、mainrdata_len。然后将XLOG的4个部分:XLOG头部 + xl_heap_header + 元组具体数据 + xl_heap_insert组装成XLogRecData链表。
1 | // src/include/access/xlog_internal.h |
1 | /* |
hdr_scratch指向一块区域,它即将保存XLOG头部,包括XLogRecord, XLogRecordBlockHeader, RelFileNode, BlockNumber;hdr_rdt是链表头,hdr_rdt->data和hdr_scratch相等。
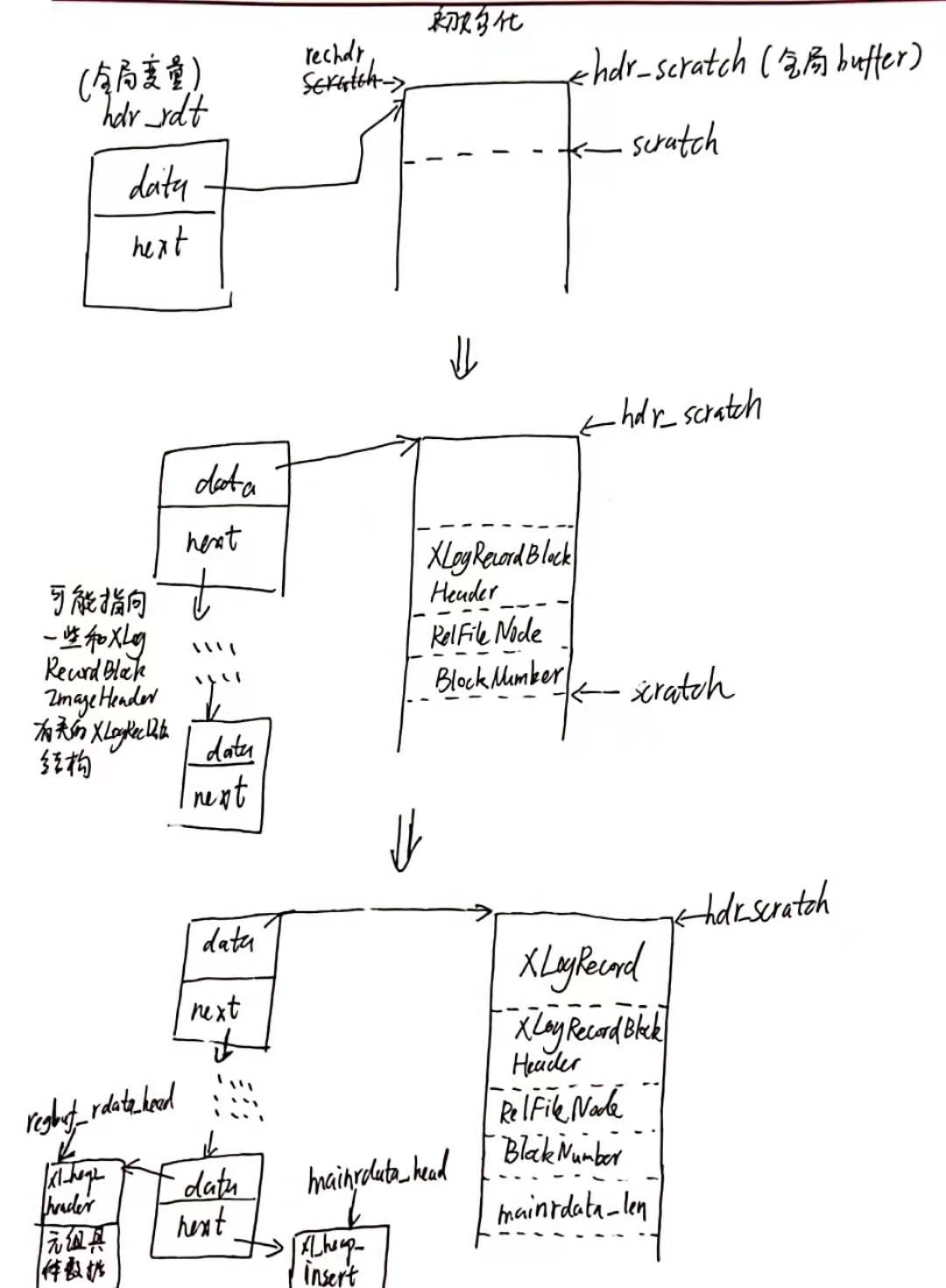
这个函数涉及到很重要的备份区块的问题:在经过判断后,如果一个page需要备份,那么就执行相关操作,但是这个page是没有必要全部放到日志中的,只需要放一部分。可以看这张图理解。
在registered_buffer中,提供了两个临时的XLogRecData,其实就是分别用于存放备份区块的两个部分数据的,第一部分是:page head + item data,第二部分是tuples。
ReserveXLogInsertLocation() @xlog.c
根据日志的大小来预留足够的XLog空间。
1 | /* |
在PostgreSQL中XLOG是顺序写入的,PostgreSQL使用了一个全局的XLogCtlInsert结构体对象来记录日志的写入位置。其中CurrBytePos成员表示日志的当前写入位置,用CurrBytePos+size就可以得到日志的结束位置。然后将这个当前写入位置作为下一条日志的PrevBytePos存放到XLogCtlInsert结构体中。由于XLogCtlInsert是一个全局对象,所以在获取和修改其中成员时,需要加锁,这里直接使用自旋锁。
startbytepos、endbytepos、prevbytepos,这三个位置,实际上是三个逻辑位置。
CurrBytePos每次都递增一个XLOG日志的大小size,这种方式给程序员提供了一个很好的抽象,仿佛xlog buffer中只会存放一条一条的XLOG,但实际上并不是这样。
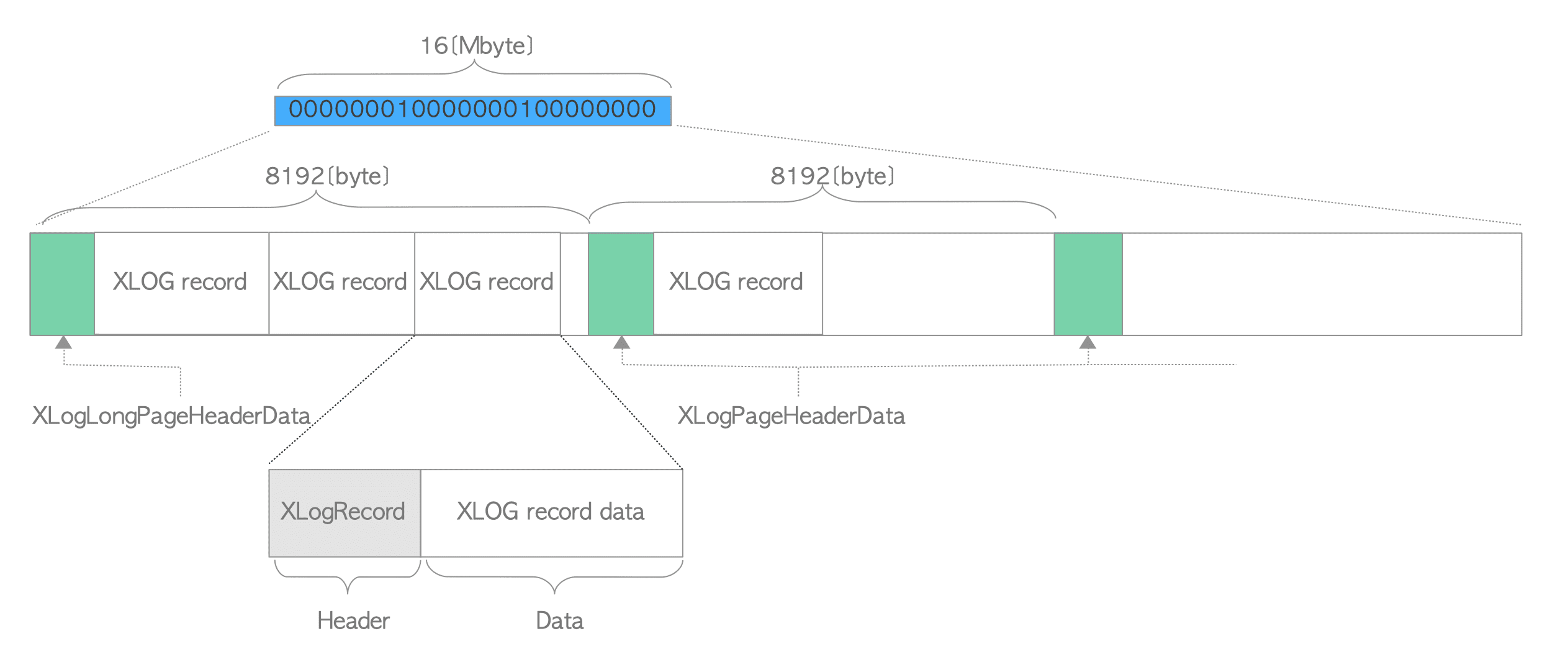
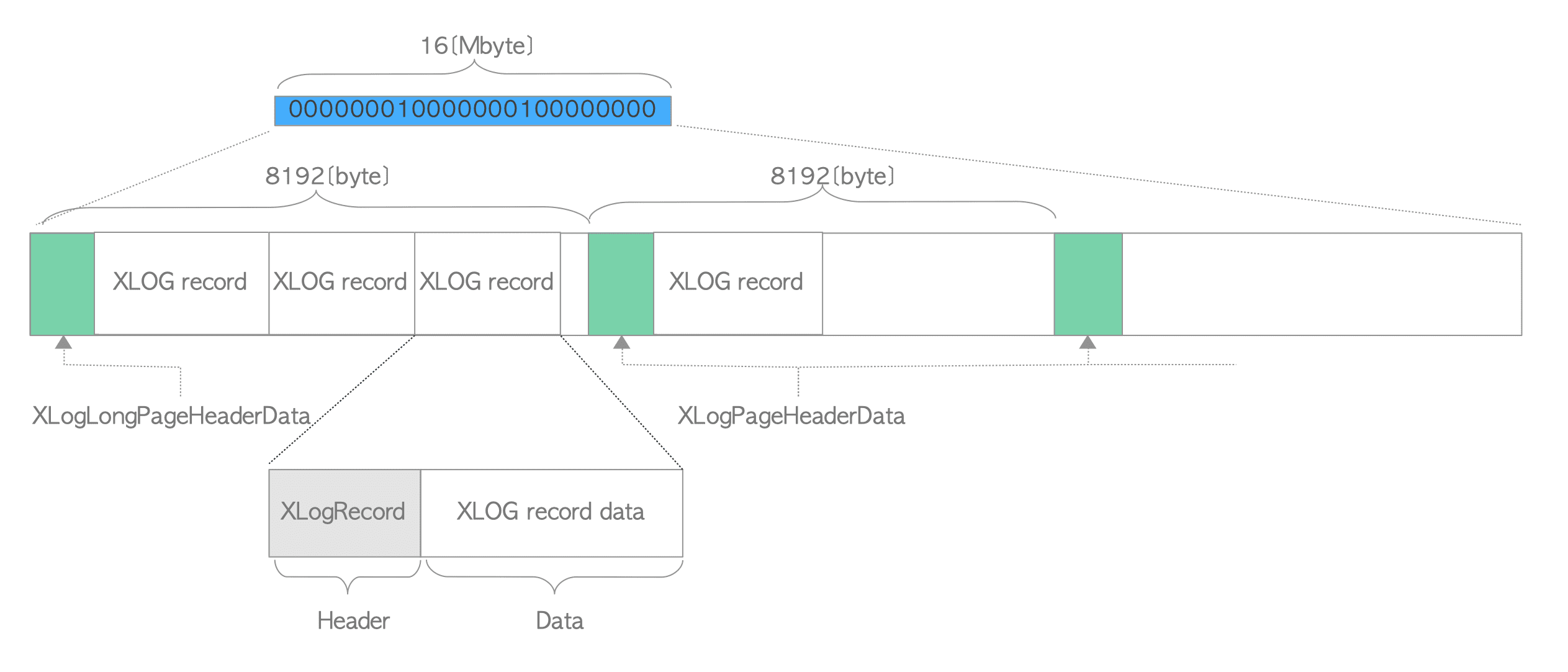
一个WAL段文件的默认大小为16MB,并且其内部被划分成大小为8KB的多个页面。第一个页面包含了由XLogLongPageHeaderData定义的首部数据,其他页面包含了由XLogPageHeaderData定义的首部数据。
真实的物理位置是这样计算的:
1 | /* |
CopyXLogRecordToWAL() @xlog.c
首先调用GetXlogBuffer()获取写入Xlog buffer的位置currpos,然后再进行写入:
1 | while (rdata != NULL) |
内存循环用于处理XLOG长度大于当前page空闲空间的情况,此时需要先将XLOG的一部分存放到当前page的剩余空间中,然后调用GetXLogBuffer为XLOG的剩余部分寻找一个新的page进行写入,而这个新page实际就是当前page的下一个page。如果当前page是log buffer中的最后一个page,那么GetXLogBuffer就会循环到的log buffer的第一个page。
XLOG buffer
XLOG buffer的组织结构
1 | void |
从上述代码中可用看出共享缓存被分了5个部分:
第一部分:XLogCtl
第二部分:LSN数组,数组元素个数和log buffer的页面数一致(XLOGbuffers)
第三部分:WALInsertLockPadded数组,数组元素个数为NUM_XLOGINSERT_LOCKS
第四部分:对齐位
第五部分:log buffer,数组元素个数为XLOGbuffers


XLogCtl是一个XLogCtlData结构体,这个结构体非常重要,用于控制XLOG的写入;其中的pages用于指向log buffer的起始地址;XLogCacheBlck用于存放最大的log buffer页面下标,也就是页面数量-1。
GetXLogBuffer() @xlog.c
在XLogRecordAssemble组装好一条XLOG之后。会经历以下步骤:
- 调用ReserveXLogInsertLocation获取XLOG的物理写入位置,这个位置也是XLOG的LSN。LSN是一个单调递增的整数。
- 调用GetXLogBuffer,将上一步得到的LSN作为入参,获取这个LSN应该写入log buffer的哪个页面,以及写入的位置指针,currpos。
- 将XLOG写入currpos指向的log buffer。
log buffer是由连续内存空间组成的循环队列,XLOG从前向后写log buffer,写满后循环到队头,再重头开始写。
1 | /* |
1 |
由于是循环队列,那么当循环到队头后,队头page中的数据就会被新的XLOG覆盖。既然要覆盖,那么在覆盖之前需要先确保对应page中的数据已经落盘。所以GetXLogBuffer()还有一个非常重要的功能就是在页面覆盖之前判断这个页面是否是脏页,如果是脏页就需要将脏页落盘。它是通过计算expetedEndPtr和实际的endptr然后来进行比较来实现的(如果通过XLogRecPtrToBufIdx()计算出了一个idx,然后若idx对应的xlog buffer page是环形队列的头,或者说是脏页,那么这个脏页的endptr肯定和expectedEndPtr不一样)。
XLOG落盘
XLOG什么时候需要落盘?
事务commit之前
依据WAL的定义,XLOG落盘之后事务才可以commit。所以在事务commit之前,必须将事务相关的XLOG落盘。
log buffer被覆盖之前。这个就是前面说到的情况。
后台进程定期落盘。由于commit之前日志必须落盘,也就是说日志没有落盘,事务就不能commit。所以日志的落盘会导致commit的延迟,为了降低这种延迟,数据库通常都有专门的后台线程或者进程来定期对日志进行落盘。
为了测试第2种情况下的落盘,需要将后台定期日志落盘的进程给挂起。
定期落盘的主要调用栈是:
1 | 1. WalWriteMain() |
数据结构
1 | /*---------- |
Write
Write表示在此位置之前的XLOG已经写入操作系统缓存(不确定是否落盘)。
Flush
Write表示在此位置之前的XLOG已经落盘。
由于,我们只关注同步提交,所以Write和Flush一定是相等的。
- XLogwrtRqst与XLogwrtResult是存放于共享内存中被所有进程共享的,所以在读写时需要加锁。具体来说:读时需要info_lck锁或者WALWriteLock,写时两把锁都需要。
- XLogwrtRqst表示我们需要落盘的XLOG lsn,XLogwrtResult表示已经落盘的XLOG lsn。
XLogFlush() @xlog.c
1 | void |
需要将record之前的所有XLOG进行落盘。
1 | /* |
首先,将record的值与本地缓存的XLogwrtResult.Flush相比较,以判断record之前的XLOG是否已经落盘,如果是则直接返回。(这里是一个优化,缓存的XLogwrtResult肯定比全局的XLogCtl->LogwrtResult要旧,如果record小于XLogwrtResult.Flush,那么肯定也不用访问XLogCtl了,因为访问它,要加锁,加锁是有开销的。)
1 | /* Quick exit if already known flushed */ |
接下来,对info_lck加锁,然后获取全局XLogwrtResult,以更新本地XLogwrtResult。前面讲过对全局XLogwrtResult、XLogwrtRqst的读操作需要对info_lck加锁。更新本地XLogwrtResult后再次判断record之前的XLOG是否已经落盘。
1 | /* read LogwrtResult and update local state */ |
接下来我们需要“wait for all in-flight insertions to the pages we’re about to write to finish”。
1 | /* |
然后,我们需要获取WALWriteLock锁,在对XLOG进行写盘之前,必须获取WALWriteLock锁,获取锁之后,需要再次读取全局XLogwrtResult,然后判断record之前的XLOG是否已经落盘。
接下来,将临时WriteRqst的Write和Flush修改为insertpos,表示我们希望将insertpos(insrtpos可能是record,也可能不是,这个要看在执行XLogFlush()时有没有别的进程先一步flush了)之前的XLOG落盘,然后调用XLogWrite进行真正的写盘操作。
1 | /* try to write/flush later additions to XLOG as well */ |
XLogWrite() @xlog.c
XLogWrite主要接收一个参数,是XLogwrtRqst,表示写入的日志的最大的LSN。这个函数还要依赖其他很重要的上下文:
- XLogCtl。这个变量包含了LogwrtResult, pages, xlbocks等属性需要用到
- openLogFile,当前正在打开的段文件的VFD(虚拟文件描述符, PG中的文件概念)。
- openLogSegNo: 当前正在打开的段文件的文件号。
1 | /* |
第一个场景(最复杂的):
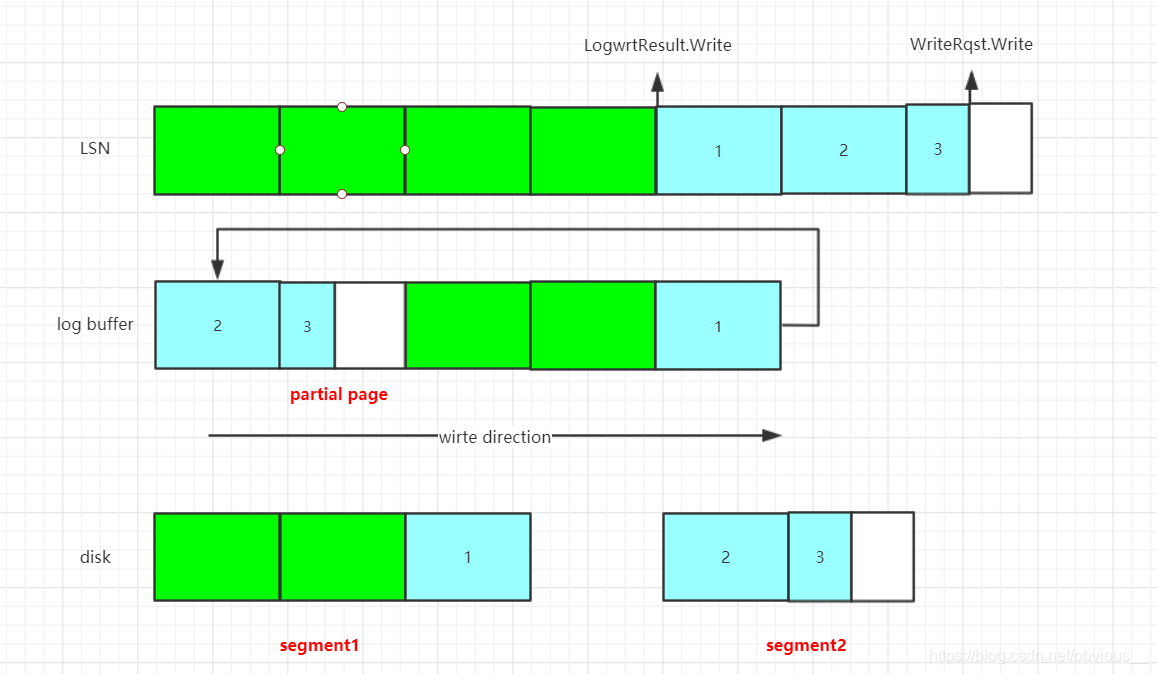
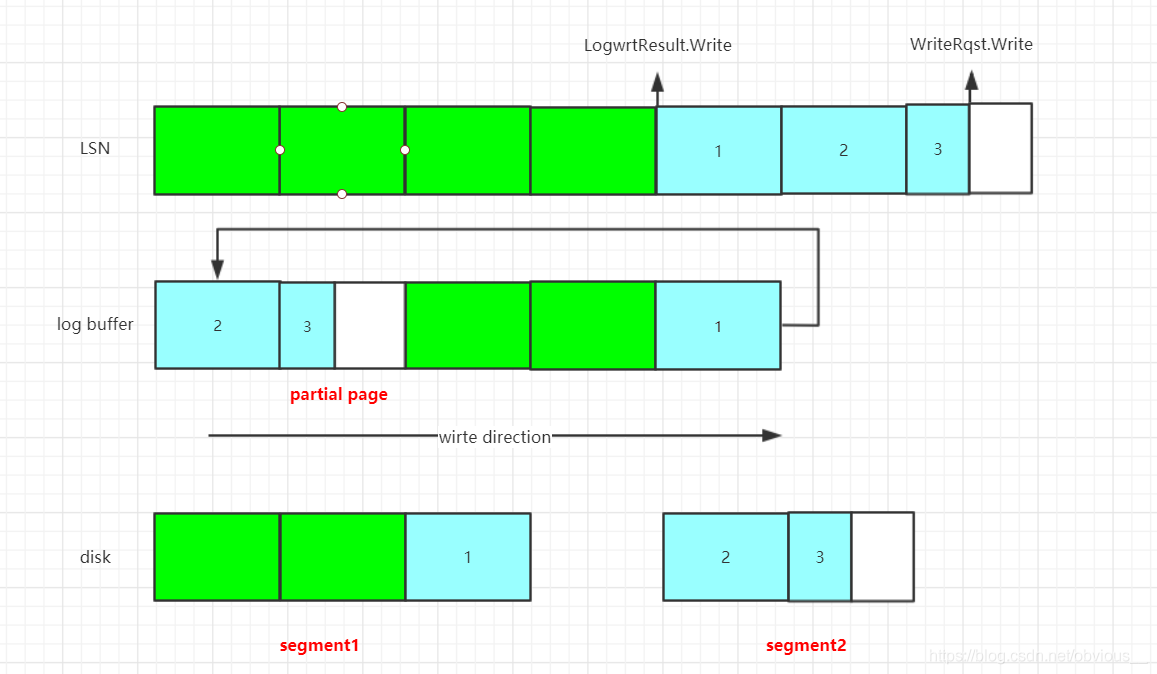
上图展示了LSN、log buffer、物理文件的对应关系。其中绿色部分表示已经落盘的XLOG、蓝色部分表示尚未落盘的XLOG。
- LSN: 如果我们把所有日志(包括段页管理信息)看成一个长段的话,那么当前的日志号,LSN,就是当前日志的末尾(右边是开区间,不包含)。
- log buffer:XLOG首先会写入log buffer,前面讲过GetXLogBuffer会定位一个LSN对应的XLOG应该写入哪个buffer page。log buffer是一个循环队列,1号page在log buffer的队头,队尾写满之后,会循环到队头继续写入(当然,这时要考虑eviction)。
- disk:disk表示物理文件,log buffer中的XLOG最终都会落盘到物理文件。那么我们如何知道buffer page和物理块的对应关系呢?实际上也是通过LSN。一个segment对应一个单独的物理文件,一个page对应物理文件中的两个个物理块(PG中的页是8KB,磁盘页是4KB)。段号 = LSN / XLogSegSize, 段内块偏移 = LSN % XLogSegSize
1 | npages = 0; |
npages用于记录需要落盘的页面数量;startidx表示第一个需要落盘的xlog buffer page的下标;startoffset表示段文件需要写入的起始位置。log buffer以数组形式存放在XLogCtlData的pages成员中,数组元素为一个buffer page。而startidx、curridx均表示pages数组的下标。
1 | while (LogwrtResult.Write < WriteRqst.Write) |
xlblocks与buffer page一一对应。xlblocks数组来表示某个buffer page当前可写入的XLOG的LSN的上限。由于buffer page的大小固定为XLOG_BLCKSZ,所以通过xlblocks-XLOG_BLCKSZ就可以得到该page可写入XLOG的LSN的下限。
1 | /* Add current page to the set of pending pages-to-dump */ |
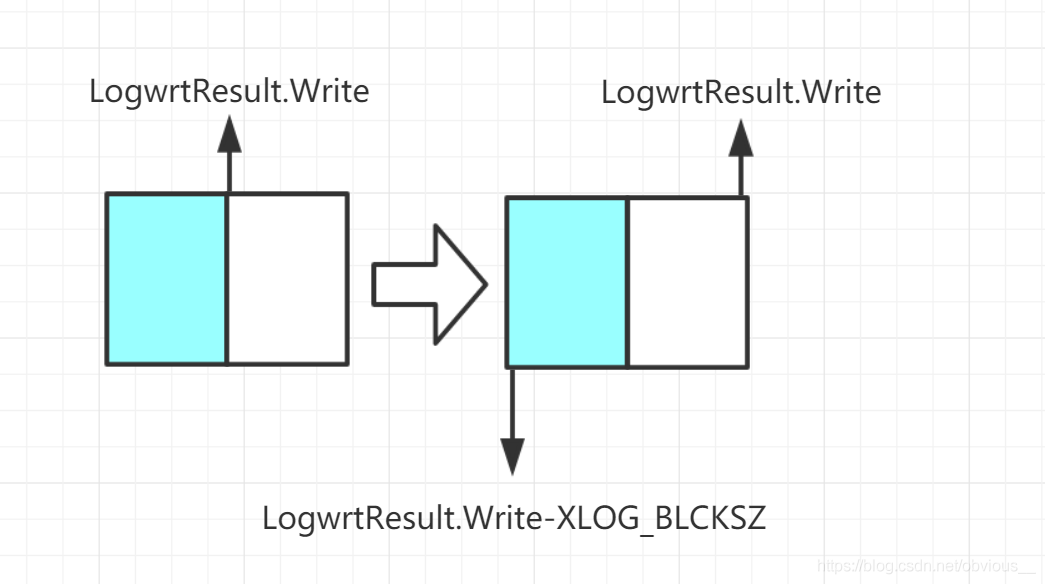
1 | /* |
checkpoint
WalWriterMain中主要是调用XLogBackgroundFlush把相应XLOG写入事务日志文件。
参考PostgreSQL启动过程中的那些事十九:walwriter进程一,PostgreSQL启动过程中的那些事十九:walwriter进程二