
LEX&YACC
简介
Lex & Yacc 是用来生成词法分析器和语法分析器的工具。
Lex (A Lexical Analyzer Generator)用于生成词法分析器,用于把输入分割成一个个有意义的词块(称为token)。
Yacc(Yet Another Compiler-Compiler)用于生成语法解析器,用于确定上述分隔好的token之间的关联
Lex
Lex结构
lex文件内容分为三个段分别为:定义段、规则段、用户子程序段
三个段用 %% 进行分隔:
1 | /* 定义段 */ |
第1段是声明段,包括:
1-C代码部分:include头文件、函数、类型等声明,这些声明会原样拷到生成的.c文件中。
1 | %{ |
2-状态声明,如%x COMMENT。
1 | 状态声明将会在第二段用到,例如: |
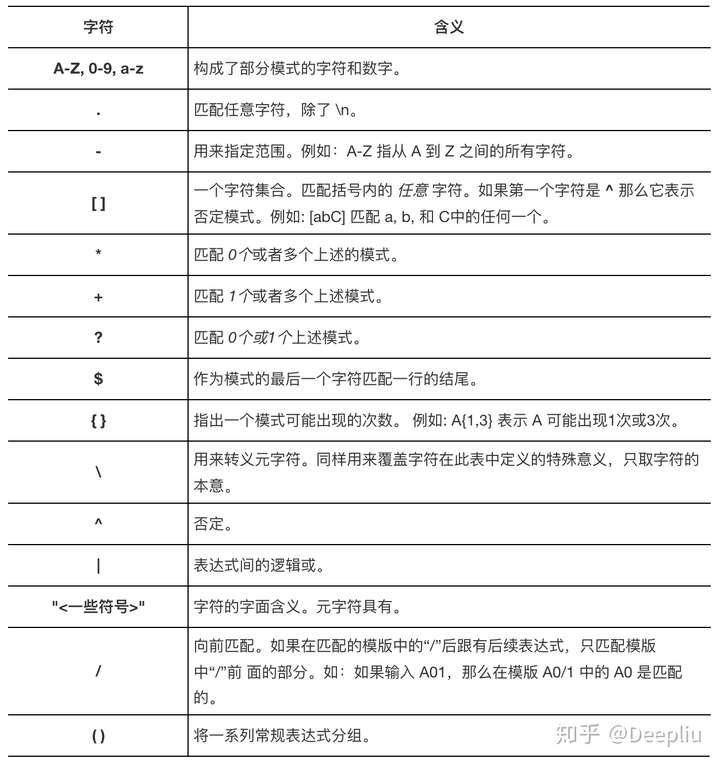
3-正则式定义,如ID [A-Za-z_]+[A-Za-z0-9_]*。
1 | WS [\ \t\b\f] |
第2段是规则段,是lex文件的主体,包括每个规则是如何匹配的,以及匹配后要执行的C代码动作。
1 | {WS} /* ignore whitespace */; |
第3段是C函数定义段,如yywrap()的定义,这些C代码会原样拷到生成的.c文件中,该段内容可以为空。
1 | yywrap() |
lex文件中其他常见函数和变量
1 | lex不仅返回相应的token,同时还会向yacc传递相应数据,如: |
Yacc
简介
yacc(Yet Another Compiler Compiler),是Unix/Linux上一个用来生成编译器的编译器(编译器代码生成器)。
使用巴克斯范式(BNF)定义语法,能处理上下文无关文法(context-free)。出现在每个产生式左边(left-hand side:lhs)的符号是非终端符号,出现在产生式右边(right-hand side:rhs)的符号有非终端符号和终端符号,但终端符号只出现在右端。
1 | 举个例子: |
语法结构
yacc语法包括三部分:定义段、规则段和用户子例程段
1 | ...定义段... |
各部分由以两个百分号开头的行分开,尽管某一个部分可以为空,但是前两部分是必须的,第三部分和前面的百分号可以省略。
定义段:
1、C代码部分:include头文件、函数、类型等声明,这些声明会原样拷贝到生产的.c文件中
2、记号声明,如%token
3、类型声明,如%type
1 | %{ |
yyerror会对无法解析的语句进行处理
1 | //标识tokens |
规则段:
规则段由语法规则和包括C代码的动作组成。
规则中目标或非终端符放在左边,后跟一个冒号(:),然后是产生式的右边,之后是对应的动作(用{}包含)。
1 | %% |
以下面这个select语句解析为例
1 | select name,old from stu where old>10; |