
连接到ECS
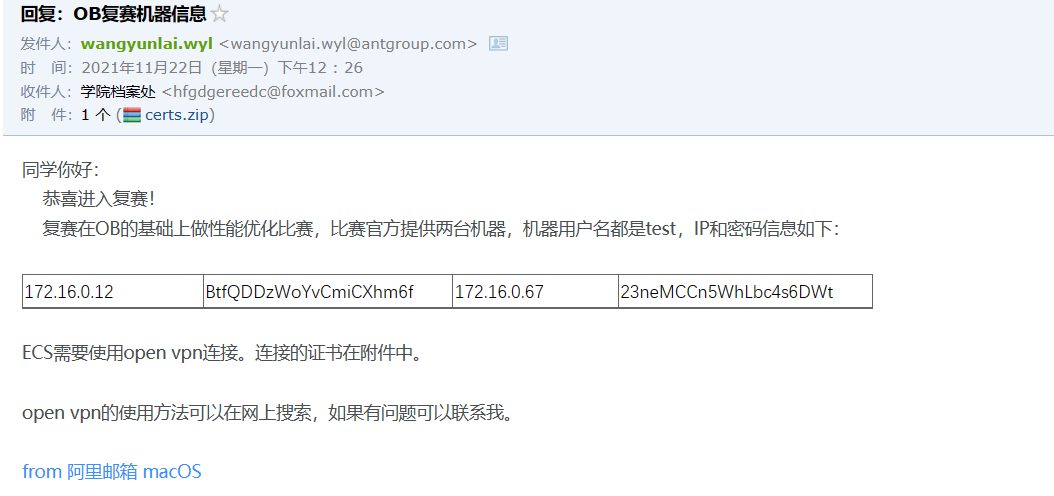
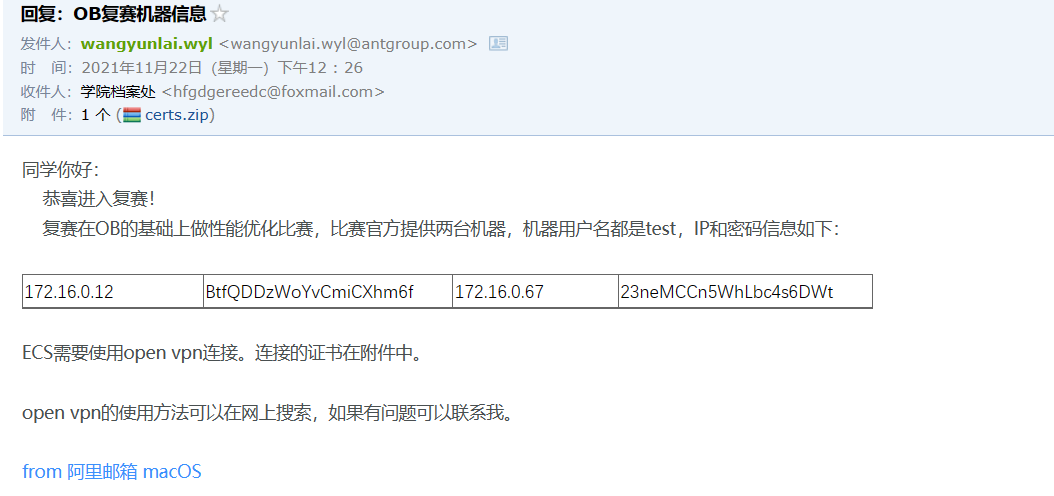
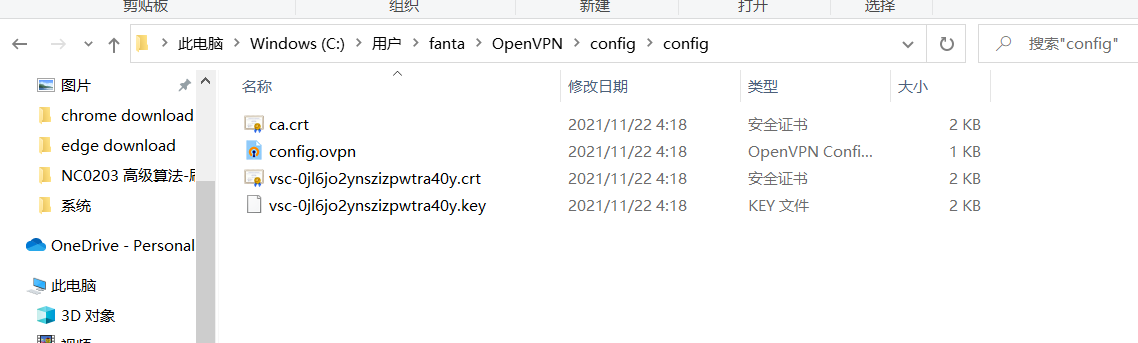
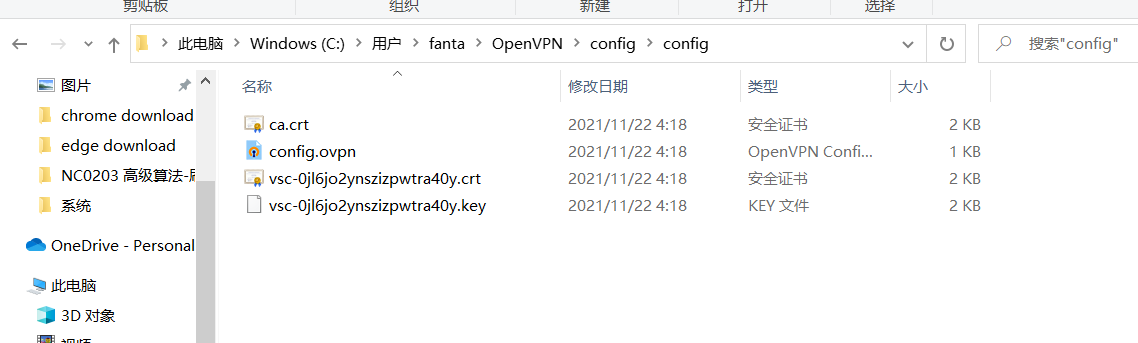
首先下载Open VPN,然后使用附件的certs配置来配置open vpn,然后连接。下面是配置文件夹内的内容,基本把附件certs中的文件复制过去就好了。
然后打开finalshell,连接到对应的ip。
172.16.0.12 BtfQDDzWoYvCmiCXhm6f 172.16.0.67 23neMCCn5WhLbc4s6DWt
密码修改为:zhou19981209
使用VS code插件remote development来开发
参考 vscode连接远程服务器+SFTP同步本地文件 其实可以不用安装sftp,因为在vs code中可以直接上传本地文件和更改服务器文件
为了不用每次都输入密码,我们可以把公钥传输到远程服务器:


在authorized_keys中加入很多行公钥。然后把.ssh和authorized_keys的访问权限更新为至少可读。
如何使用源码进行测试
查看系统架构:
1 | uname -a |
在执行sudo yum install rpm*时,出现了错误:
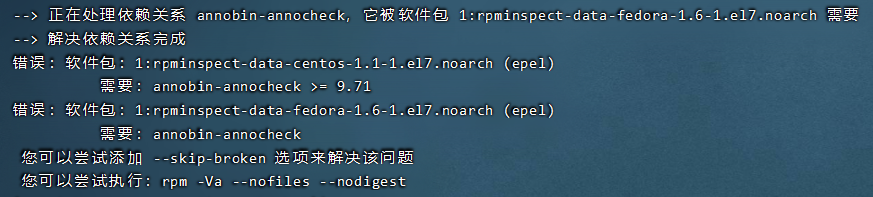
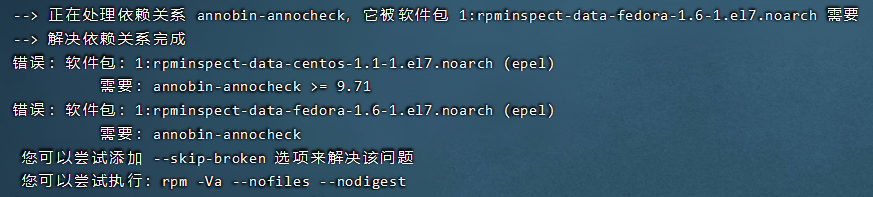
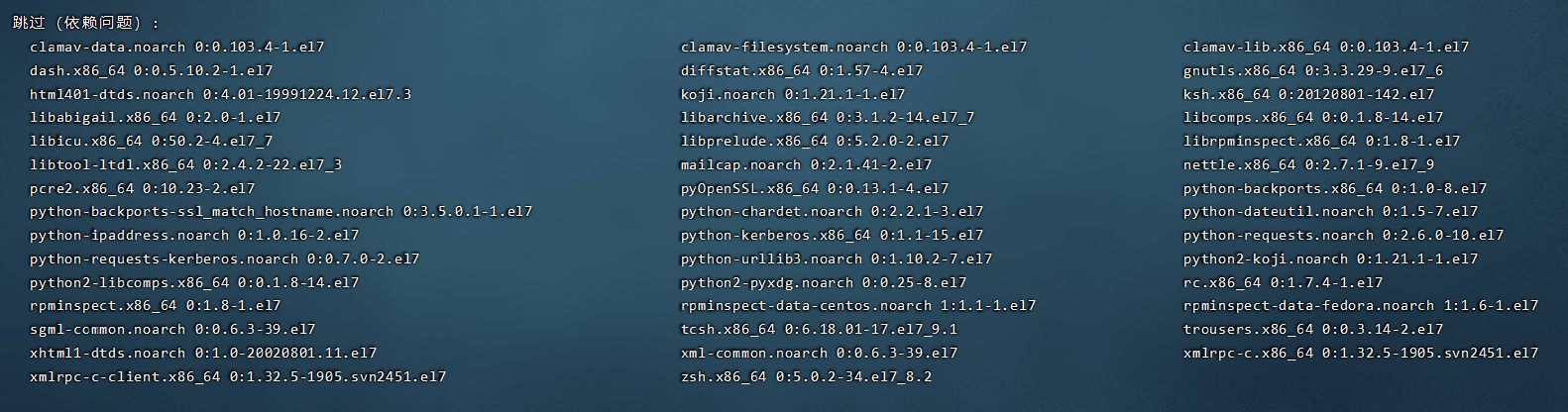
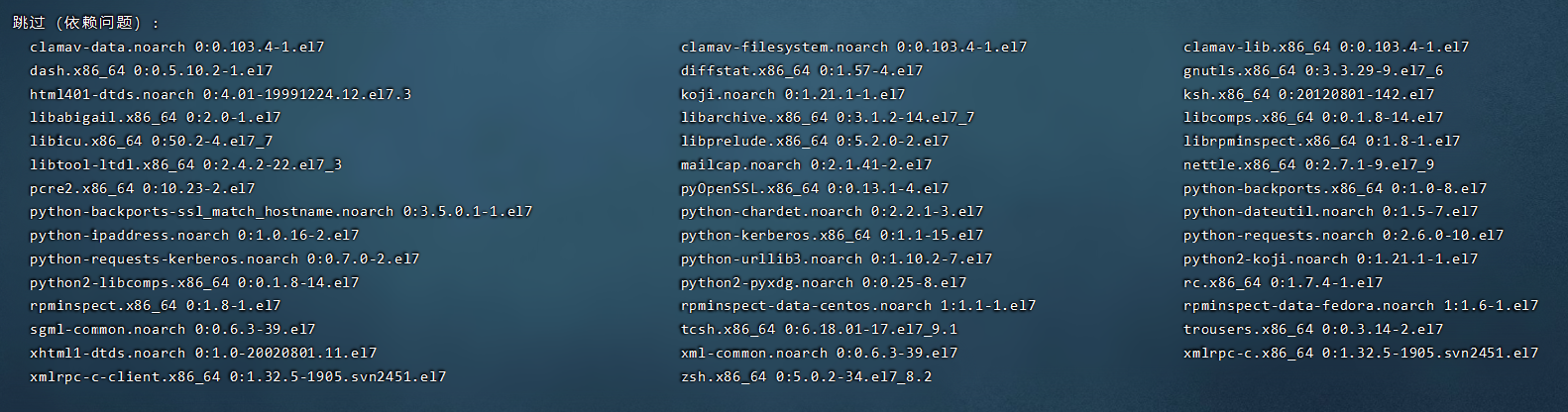
我直接跳过有依赖问题的包了,sudo yum install rpm* --skip-broken。


采用 sudo -E。简单来说,就是加上-E选项后,用户可以在sudo执行时保留当前用户已存在的环境变量,不会被sudo重置,另外,如果用户对于指定的环境变量没有权限,则会报错。
安装sysbench 1.0.20是可以的。直接在sysbench 上参考二进制的安装方法,推荐的那个。
如何多人在同一个服务器上协作
在同一台电脑上添加多个ssh key - 简书 (jianshu.com)
调试oceanbase
gdb
我们调试的时候要在oceanbase的根目录下调试,然后设置断点的时候要指定函数所在的文件,例如:
1 | break ./src/sql/parser/ob_parser.cpp:ObParser::parse |
我们要把build_debug/src/observer/observer作为~/zhouhuahui/ob-advanced-data/bin/observer的软链接,才能使用gdb调试成功,或者直接在gdb下使用:
1 | dir /home/test/zhouhuahui/Github/oceanbase |
定位到源文件也是可以的。
vscode attach
如何在vs code上调试:参考 如何debug OceanBase。但是这种不够,我是是使用attach的方式来调试,写了下面的launch.json
1 | { |
在点击调试之后,在DEBUG CONSOLE界面输入:
1 | -exec dir /home/test/zhouhuahui/Github/oceanbase |
就可以正确定位到源文件的位置了。
vscode launch
如果还要使用launch的方式,要在程序的参数加一个”-N”参数,来指明程序在前台运行,(因为默认程序在后台运行),如果不加的话,会出先调试程序刚打开却退出的现象。
1 | { |
跟踪sql的执行
1 | obclient -uroot@test -h127.0.0.1 -P 2881 -c |
1 | use test; |
理论教程
揭秘 OceanBase SQL 执行计划(一) (qq.com)
OceanBase SQL 执行计划解读(二)──── 表连接和子查询_OceanBaseGFBK的博客-CSDN博客
两个表join时,谁作为外部表,谁作为内部表不好说,由过滤条件应用后的结果集大小来定。
OceanBase 存储引擎高级技术 - 知乎 (zhihu.com)
OceanBase的索引创建流程 - 知乎 (zhihu.com)
MySQL中的semi-join_lppl010_的专栏-CSDN博客 讲解了什么是semi-join。
OB有两种从表中获取行的方法,一个是TABLE_SCAN,一个是TABLE_GET,为了方便,就直接说scan和get了。scan表示直接从头到尾扫描OB的索引组织表,然后获取这些行;get表示通过索引的key来找到这些行或者行的key。使用scan还是get是由SQL中的where部分决定的,假如查询条件涉及的列是有索引的,就可以使用get,假如没有,就只能使用scan。
但是还有一个问题是:假如A,B表进行嵌套循环连接,那么谁作外表,谁作内表呢?根据A,B获取行的方法不同,分为三种情况来讨论:
- A使用scan,B也使用scan。那么需要预估A的结果集大小和B的结果集大小,哪个小就作为内表。
- A使用scan,B使用get。那么A作为外表,B作为内表。
- A使用get,B使用get。哪个结果集小就作为外表。
性能优化之Block Nested-Loop Join(BNL) - 云+社区 - 腾讯云 (tencent.com)
分析patch
reset和reuse分别在哪些地方被用到了,reset和reuse的具体语义是什么,为什么要这么用?
reuse:
- ObTableAccessContext.reuse
- ObTableScanStoreRowIterator.reuse_row_iters
分析群里给的patch的更改前后对比
更改前
1 | namespace oceanbase { |
1 | void ObMultipleGetMerge::reset_with_fuse_row_cache() |
1 | void ObMultipleMerge::reset() |
ObStoreRowIterator 只有空的reuse()函数,没有reset()函数。
ObMemtableScanIterator和ObMemtableMGetIterator的reuse()函数都是调用了自己的reset()函数。
ObSEArray.reset()函数最终调用了ObSEArrayImpl.destroy()函数。
1 | template <typename T, int64_t LOCAL_ARRAY_SIZE, typename BlockAllocatorT, bool auto_free> |
更改后
1 | void ObMultipleGetMerge::reset_with_fuse_row_cache() |
1 | void ObMultipleMerge::reset() |
如果按照简单的sql语句:select /*+ordered use_nl(A,B)*/ count(*) from t1 A, v1 B where A.c1 = B.c1 and A.c2 = B.c2,在rescan阶段将会执行ObTableScanStoreRowIterator::rescan() -> ... ObMultipleScanMerge::reuse() -> ObMultipleMerge::reuse(),
patch2(sysbench: 3850)
1 | diff --git a/etc/observer.config.bin b/etc/observer.config.bin |
patch3
1 | diff --git a/src/storage/blocksstable/ob_block_sstable_struct.cpp b/src/storage/blocksstable/ob_block_sstable_struct.cpp |
patch4
1 | diff --git a/diff b/diff |
patch4的主要思想就是缓存了微块(rescan场景下缓存了微块,然后在ObSSTableRowIterator的reuse()中标记这是rescan场景);然后将read_hanldes_和micro_handles_重用了。
ObSSTableRowIterator等memtable或者sstable的iterator的reuse_try()函数是如何被调用的呢?因为每次rescan都会调用ObMultipleMerge的reuse()函数(其实它的子类的reuse()函数基本上也要调用这个函数),然后这个reuse()函数里面调用了ObMultipleMerge::reuse_iter_array()函数,然后我们修改了ObMultiMerge::reuse_iter_array()函数,使得它不是简单地reset所有iterator,而是reuse_try它们。
在ObSSTableRowIterator::reuse_try()函数中,我们取消reset read_handles_和reset micro_handles_ ,这样就可以再次用这两种handle了,并且在ObSimpleArray类中reset()函数中加入对所有元素的释放操作,这个操作比较重要。因为我们是通过stmt_allocator来给read_handles_和mico_handles_来申请空间,应该要找个合适的时机来释放这个空间。
我想我已经搞清楚了为什么使用HandleCache,也即在rescan场景下缓存微块,并且将read_handles_和micro_handles重用,可以提升性能。HandleCache是将这次scan右表需要的所有微块都缓存下来,micro_handles是将这些缓存的微块按照扫描顺序排好,micro_handles最里面有buf指针,指向微块数据,HandleCache也是的,这两个buf指针是相同的,也即HandleCache和micro_handles是对同一个微块数据的引用。当我们重用HandleCache和micro_handles时,下一次rescan就省了两部分工作:
- 不用重新从磁盘读取微块了,因为可能在上一个rescan微块已经缓存在内存中了。
- 不用重新给micro_handles和read_handles分配空间了。以前每次rescan都要给micro_handles和read_handles分配空间,但是这两个的分配器换成了stmt_allocator后,这两个的空间就不会在新的rescan处被回收,我们就可以复用这个空间。但是有一点需要注意
1 | int reserve(common::ObArenaAllocator& allocator, const int64_t count) |
这是micro_handles和read_handles的空间分配函数,当我们不reset它们时,capacity_属性就不用清0,因此就不会走if路线了。
源码阅读
架构
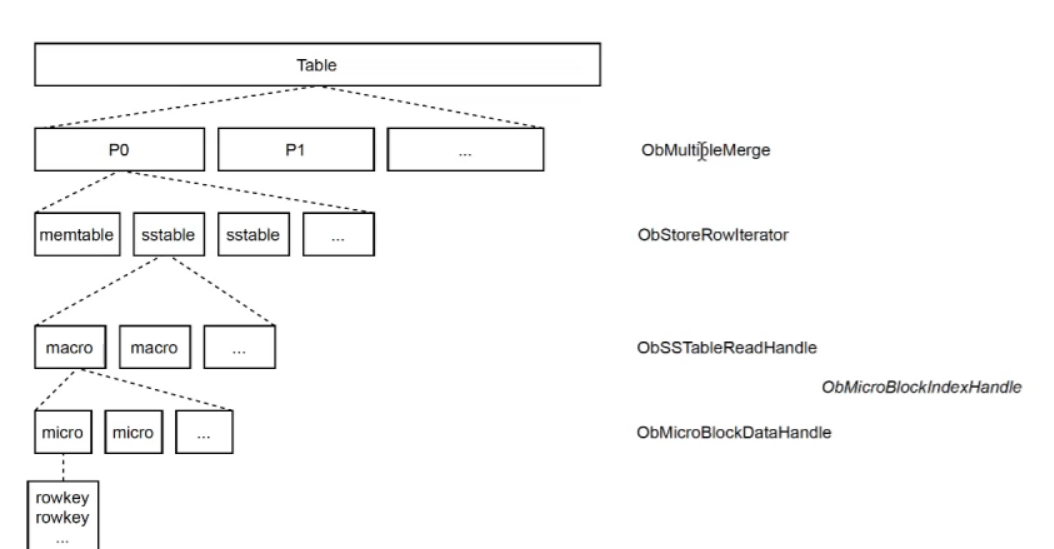
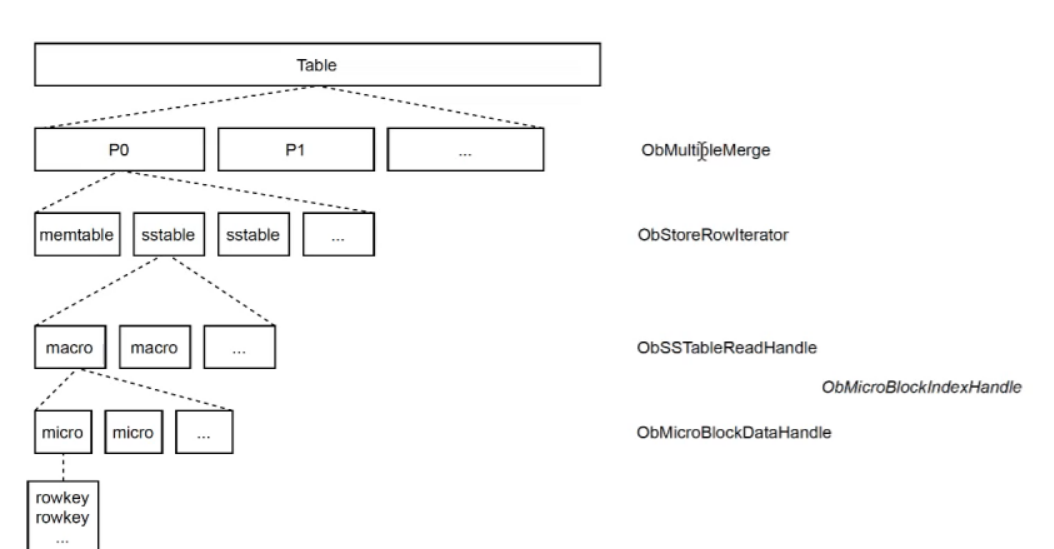
OB的block cache是微块级的,不建议缓存宏块。但是不懂是怎么通过range或者rowkey定位到宏块,又从宏块中找到对应的微块,反正最后是能够在一个rescan内,把所有微块给拿到内存中的。
OB的ObMicroBlockIndexHandle存储的是ObMicroBlockIndexCache,它是宏块中对微块的索引,通过它可以方便地在宏块中找到微块。
在ObHandleMgr::init()函数中,如果是is multi并且is ordered,说明这个不断传下来的rowkey或者range都是有序的,例如rowkey是1, 2, 4, 8, 20这样的,这样的话,我们就只需要对一个ObMicroBlockHandle进行缓存就好了,不需要HandleCache来缓存那么多的ObMicroBlockHandle。
从ObExecuteResult::get_next_row()函数读NLJ的流程
1 | int ObExecuteResult::get_next_row(ObExecContext& ctx, const common::ObNewRow*& row) |
1 | ret = get_next_row(); |
我们可以看到get_next_row()函数应该是实际得到一行数据,结果保存在static_engine_root_.get_spec().output_中。
其实这里的static_engine_root_是ObOperator*类型的,是一个算子。
1 | int ObExecuteResult::get_next_row() |
1 | while (OB_SUCC(ret) && !got_row) { |
调用ObOperator::get_next_row()得到下一行数据,如果是OB_ITER_END,那就switch_iterator(),但是不明白这个函数是做什么的?
1 | int ObOperator::get_next_row() |
1 | if (OB_FAIL(startup_filter(filtered))) |
不懂startup_filter()函数是做什么的。当filtered为true时,表示过滤不成功。当还没有得到第一行记录的时候,记录一下当前的时间到op_monitor_info_中。
1 | int ObNestedLoopJoinOp::inner_get_next_row() |
1 | if (OB_UNLIKELY(LEFT_SEMI_JOIN == MY_SPEC.join_type_ || LEFT_ANTI_JOIN == MY_SPEC.join_type_)) { |
在构造ObNestLoopJoinOp的时候
1 | ObNestedLoopJoinOp::ObNestedLoopJoinOp(ObExecContext& exec_ctx, const ObOpSpec& spec, ObOpInput* input) |
join_row_with_semi_join()不知道干什么的?
在构造函数,state_初始化为JS_READ_LEFT。我们看到首先有一个while循环,所以肯定是在while循环中先read_left_operate(),然后再执行read_left_func_going(),在read_left_func_going()的最后,设置state_为JS_READ_RIGHT,然后就继续循环,读取右表中的一行read_right_operate(),然后就继续循环执行read_right_func_going(),这里会调用ObJoinOp::calc_other_conds()函数进行判断是否满足filter条件,如果满足,就设置output_row_produced_为true,这样就可以结束循环。所以这个循环的目的就是为了得到一行满足filter的数据,当然在上层,我们也进行了一个filter判断,我觉得这是多余的了。
这里state_是个很重要的属性,控制着NLJ的执行方向,是读左表,还是读右表,还是read_left_func_going(),具体这些执行怎么做的,后面具体说。
内存管理
ObArenaAllocator
我们先看page_arena.h这个文件中是怎么定义和实现ObArenaAllocator这个类的。
alloc
1 | // class ObArenaAllocator final : public ObIAllocator |
1 | // template <typename CharT = char, class PageAllocatorT = DefaultPageAllocator> |
ObArenaAllocator每次是在一个page内进行内存分配的,如果在当前的page内可以分配,就分配,如果不能,就用ModulePageAllocator分配一个新的页,在这个页内进行分配。所有用ModulePageAllocator分配的页是用链表连接起来的。
1 | // template <typename CharT = char, class PageAllocatorT = DefaultPageAllocator> |
使用PageArena::extend_page()来扩展一个页。
1 | // template <typename CharT = char, class PageAllocatorT = DefaultPageAllocator> |
PageArena::alloc_new_page()调用了ModulePageAllocator::alloc()函数来分配一个内存页。这个alloc最终会调用到
1 | void* ObMallocAllocator::alloc(const int64_t size, const oceanbase::lib::ObMemAttr& attr) |
1 | } else if (OB_UNLIKELY(inner_attr.tenant_id_ >= PRESERVED_TENANT_COUNT)) { |
这里可以发现,我们要分配内存,就要使用allocator池中的一个allocator来分配,这里超过了我的知识范围,但是使用哪个allocator可能是和租户什么的有关。我看过一篇文章,解释过OB的租户的内存:OB 内存分配概述 (qq.com)
读左表的流程
ObNestLoopJoinOp::read_left_operate() 函数调用 ObJoinOp::get_next_left_row()函数。
1 | int ObJoinOp::get_next_left_row() |
设置左表读出的row还没有join,然后调用left_的get_next_row(),它是ObTableScanOp动态类型。
1 | int ObTableScanOp::inner_get_next_row() { |
get_next_row_with_mode()成功后,就让output_row_count_增加。
1 | int ObTableScanIterator::get_next_row(common::ObNewRow*& row) { |
这里有个iter_和row_iter_属性,iter_是ObTableScanIterIterator对象,row_iter_是ObTableScanRangeArrayRowIterator对象。iter_可以产生多个row_iter_,当一个row_iter_遍历到结束后,就让iter_下一个row_iter_来继续遍历。结合多range和多rowkey的前提,可能是在ObTableScanIterator中多个ObTableScanRangeArrayRowIterator,它们由ObTableScanIterIterator来管理,并且和多range一一对应,比方说,根据主键来查表,where中主键的范围是key<7 或者 key > 100,那么这两个range就会对应两个ObTableScanRangeArrayRowIterator。(由于OB中的表是索引组织表,因此只要知道要查找的主键的范围,那么就可以根据索引轻松找到想要的元组记录在哪,这也是为什么OB有range的概念的原因,想一下,要是记录随便放在表文件中,有range有什么用呢,还是要一个页一个页地扫描)。
1 | int ObTableScanStoreRowIterator::get_next_row(ObStoreRow*& cur_row) { |
这个函数就调用了get_next_row()。main_iter_是ObQueryRowIterator类型,动态类型估计是ObMultipleScanMerge。
1 | int ObMultipleMerge::get_next_row(ObStoreRow*& row); |
这个get_next_row()函数很长,里面大致有这几个过程:
- access_ctx_相关的操作
- refresh_table_on_demand(),在必要的时候刷新table,可能会执行一些reuse_iter_array, reset_tables等的操作
- inner_get_next_row(),得到一个没有投影的行
- check_row_in_current_range(),不知道check什么
- row_filter_->check() 判断这个行是否被过滤
- project_row() 将行进行投影
- 其他关于行的操作
- 最后是更新access_ctx_中的一些统计量。
NLJ的rescan流程
sql层的ObTableScanOp.cpp的inner_close()函数可以看到有table_allocator_的reuse()调用,这个时候就是把以前用allocator申请的空间给释放掉。
rescan的实现是在ObTableScanStoreRowIterator.cpp中的rescan()函数中可以看到,其实就是调用ObMultipleMerge::reuse_iter_array()把很多iterator给重用了,然后再调用open_iter()函数重新打开这些iterator,并没有涉及到数据的操作。
在ob_table_scan_op.cpp中的rt_rescan()函数中写了单机rescan的大致流程。
NLJ的右表读取流程
左表肯定是通过scan方式来得到数据,因为是要遍历左表的所有满足条件的行。
由于在我们的case中,右表是通过索引回表的方式得到数据的,因此是这样的流程:ObIndexMerge中先访问索引,得到每个rowkey,然后通过rowkey通过get的方式访问主表,来得到具体的行数据。这个流程实现在ObIndexMerge::get_next_row()函数中。
考虑src/storage/ob_handle_mgr.h/oceanbase::storage::ObHandleMgr::init()函数,它的部分调用链是:ObSSTableRowIterator::inner_open() -> ObSSTableRowIterator::init_handle_mgr() -> ObHandleMgr::init()。
我们可以发现这里面有一个HandleCache对象:
1 | } else if (is_multi) { |
“当is_multi为true时,说明有多个range或者rowkey传下来,这样就可以走这个分支,然后就可以使用这个HandleCache。我们考虑rescan的场景,每次rescan都会有新的range下来,而且这个range和上次rescan的range是连续的,因此就相当于is_multi为true的情况,如果这个时候我们不使用HandleCache,就是不够优化的。”
考虑src/ob_sstable_row_iterator.cpp/prefetch_block()函数。这个函数就是预取micro block的,但是为什么要预取呢,因为OB内部取磁盘数据是异步执行的,我们可以边读A微块边从磁盘取B微块,当A微块读取完成之后,说不定B微块就读好了。
ObHandleMgr和预取没有太大关系,只是我们在预取之后的数据之上,加了层Handle的cache。
我们是先从cache中找我们需要的微块,
1 | for (int64_t i = 0; OB_SUCC(ret) && i < sstable_micro_cnt; ++i) { |
如果没有找到,再从磁盘IO来找。因为每次找新的range或者rowkey会定位到一个微块,可能这个微块和上个读取微块相同,如果这时发现这个相同的微块在HandleCache中找到了,就很好。
1 | // ob_micro_block_handle_mgr.h |
1 | // ob_sstable_row_iterator.h |
1 | // ob_sstable_row_iterator.h |
问题
rescan中的prefetch是怎么回事?
stmt_allocator申请的空间在何时释放的?
迭代器打开时做了什么事情?
ObTableScanOp的ObNewRowIterator result_属性在哪初始化的?
在ObTableScanOp::do_table_scan()函数中调用了
1 | if (OB_FAIL(das->table_scan(scan_param_, ab_iters_))) { |
这个das最终又调用了
1 | ObPartitionService::table_scan(ObVTableScanParam& vparam, common::ObNewRowIterator*& result) |
这里的result就是我们要的输出参数;然后又调用了
1 | ObPartitionStorage::table_scan(ObTableScanParam& param, const int64_t data_max_schema_version, common::ObNewRowIterator*& result) |
在这个函数里面有一条调用
1 | if (OB_UNLIKELY(NULL == (iter = rp_alloc(ObTableScanIterator, ObTableScanIterator::LABEL)))) { |
在什么层级下是线程安全的?
钉钉群消息
线程检查工具:https://www.jianshu.com/p/1f29ae9fceee
https://github.com/oceanbase/oceanbase/issues/488 这里面的issue,认领的话,在这里回复就好了
@王运来 来哥 发的机器不能访问外网吗?
export http_proxy=’http://172.16.0.232:8259‘
export https_proxy=$http_proxy
测试主机密码:6vqSJOonTr52LhzFmnUm
首发!OceanBase社区版入门教程开课啦!https://mp.weixin.qq.com/s/04YjSUsNoKtIRsC0OC394A
@nauta ob支持执行请求时打开trace_log,打开方式有两种,一种是通过hint中的trace_log字段,这种方式只对携带hint的当前语句生效;另一种是通过session变量ob_enable_trace_log,这种方式对这个session的后续所有语句生效。 打开trace_log后,通过show trace可以拿到上一次的trace_log,从中可以获取trace_id。同时show trace还可以看到这条请求大致的性能统计。 使用示例如下, # 语句级 select /+ trace_log=on /c1 from t1 limit 2; show trace; # session级 set ob_enable_trace_log = ‘ON’; select count(*) from t1; show trace; last_trace_id 使用select last_trace_id();可以查看上一条语句执行的trace_id,然后在日志中grep查找相关信息。