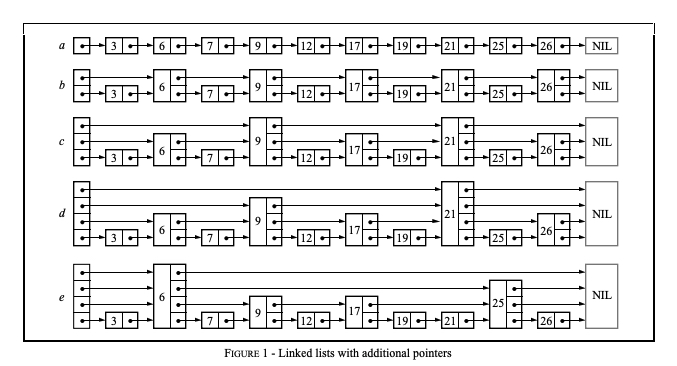
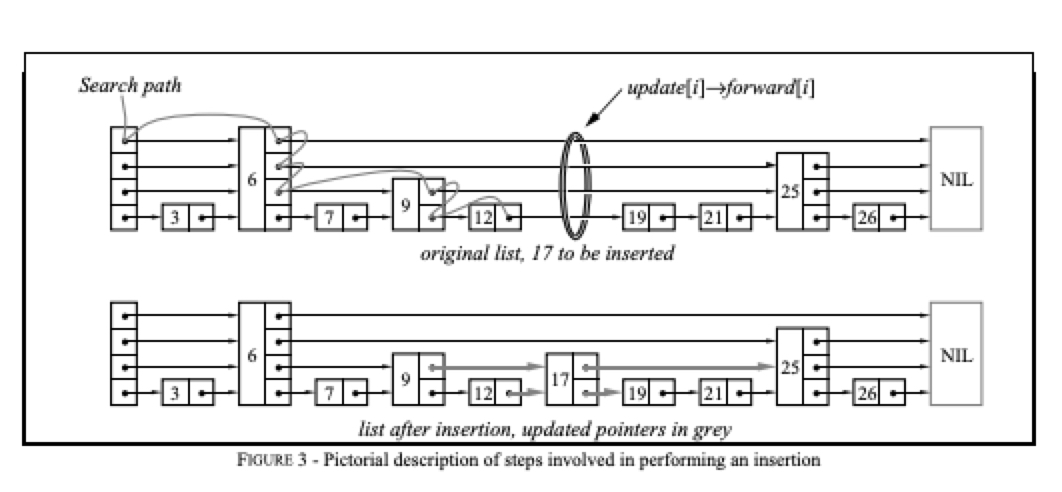
4 median of two sorted arrays
1 | class Solution { |
68 左右文本对齐
1 | class Solution { |
95 Unique Binary Search Trees II(moderate)
1 |
|
146. LRU Cache(moderate)
网址:https://leetcode.com/problems/lru-cache/


1 | /* |
上述解法的速度只超过了6%的用户,为什么这么慢?
166 分数到小数


1 | class Solution { |
187 重复的DNA序列
1 | class Solution { |
212 单词搜索2
解法1
1 | class Solution { |
解法2
前缀树解法,将words中的所有单词组织在一个前缀树中,然后从board的所有点开始遍历。
1 | struct TrieNode{ |
223 矩形面积
1 | class Solution { |
273 整数转换英文表示
1 | class Solution { |
352 将数据流变为多个不相交区间


1 | class SummaryRanges { |
371 两整数之和
1 | class Solution { |
405 数字转换为十六进制数
1 | class Solution { |
414 第三大的数
1 | class Solution { |
430 扁平化多级双向链表
思路:当p指针移动到3号点时,会做下述事情:
- 递归将
p->child扁平化,并返回子链表扁平化后的头结点和尾结点ht, 保存p->next到next中 - 更改相关指针:p与ht.first之间的,ht.second与next之间的


1 | /* |
437 路径总和3
思路:


1 | /** |
441 排列硬币
解法1
1 | class Solution { |
解法2
1 | class Solution { |
解法3
1 | class Solution { |
447 回旋镖的数量
解法1
使用组合算法,从size个点中找出3个点的所有组合,然后计算这三个点的6个排列中有哪些是符合飞镖的。
但是这个算法超时了。
1 | class Solution { |
解法2
1 | class Solution { |
470 Implement Rand10() Using Rand7()
https://leetcode.com/problems/implement-rand10-using-rand7/
1 | // The rand7() API is already defined for you. |
502 IPO
1 | class Solution { |
517


1 | class Solution { |
524 通过删除字母匹配到字典里的最长单词(middle)
解法1
采用双指针法来找到一个串是否含有给定子串
1 | class Solution { |
解法2
我们可以优化一下解法1的代码,解法1的代码可以发现指向源字符串的指针i是一点一点移动的,如果这个指针能够一下子移动到目标串的指针j所指向的字符,就高效了。
1 | 源:abcdefg |
我们可以计算源串的每个字符从该位置开始往后每一个字符第一次出现的位置。


f[i][j]表示i位置的字符对应j号字符第一次出现的位置(j=0表示’a’)
1 | class Solution { |
565 Array Nesting(moderate)
使用unordered_map记录加入s数组的数字。
1 |
|
使用visited数组记录插入到s数组中的数字。
1 |
|
注意:在C++中,不要在类中使用全局变量,否则会出现非常难以察觉的底层错误。比如上述代码的visited数组应该放在类成员函数中。
583 两个字符串的删除操作
思路:


1 | class Solution { |
587 Erect the Fence(hard)
解法1
https://www.cnblogs.com/hxsyl/p/3222688.html
1 |
|
600 不包含连续1的非负整数
解法1


1 | class Solution { |
解法2
朋友写的rust解法代码
1 | impl Solution { |
639 解码方法2
1 | class Solution { |
673 最长递增子序列的个数
解法 1
我将{长度,结尾值}保存进pq优先队列中,比如有一个长度为5的子串,它的结尾是7,那么就把{5, 7}push到pq中。每次考虑以nums[i]为结尾的最长子串时,就要从pq中分析:
1 | class Solution { |
以上代码超时了。分析以上代码,发现有很多改进之处,比如我可以用map<int, map<int,int>> mp的数据结构代替pq,因为mp[i]表示长度为i的所有子串,mp[i][j]表示长度为i,以j结尾的子串的个数,mp的键降序排列
1 | class Solution { |
678 有效的括号字符串
解法1
我们很自然的会仍然用两个栈记录目前为止不能匹配的字符,也就是*和(,每次出现右括号我们就应该去两个栈匹配可以匹配的左括号。
而*可以作为任何括号,也可以作为空字符串,所以我们应该优先用左括号匹配,所以我们出栈的策略如下:
遇到左括号,直接进栈,记录括号的位置。
遇到星号,直接进栈,记录星号的位置。
遇到右括号:
a: 左括号栈里有元素,直接出栈。
b: 左括号栈里无元素,*栈里有元素,直接出栈。无元素的话就已经匹配失败了。
如果遍历完数组的话,我们可能会发现左括号栈里还有结余元素。如果是20题的情况,已经失败了。但现在我们可能还有一些星号可以作为右括号用,所以我们进行下面的匹配操作:
对左括号栈逐一出栈,然后去看此时星号栈的栈顶,如果栈顶元素的位置大于左括号栈顶元素的位置,说明星号在括号的右侧,可以匹配。否则不可。
1 | class Solution { |
解法2
反转法:
1 | class Solution { |
725 分隔链表
1 | /** |
834 Sum of Distances in Tree
https://leetcode.com/problems/sum-of-distances-in-tree/
解法1
采用n次BFS的做法,假如要算i点到其他点的距离之和,就从i点做BFS,然后标记每个遍历到的点的层次(i点是第0层),然后将它们的层次加在一起,就是最终的答案。但是这种做的时间复杂度很高。
解法2


1 | class Solution { |
899 Orderly Queue
样例分析
样例1
1 | abd efa move a |
样例2
1 | bdc zyxa move b |
样例3
1 | bdc zayxpn move b |
解法1
1 | class Solution { |
1436 旅行终点站
解法1
1 | class Solution { |
解法2
1 | class Solution { |
1894 找到需要补充粉笔的学生编号
https://leetcode-cn.com/problems/find-the-student-that-will-replace-the-chalk/
1 | class Solution { |
5870 每棵子树内缺失的最小基因值
https://leetcode-cn.com/problems/smallest-missing-genetic-value-in-each-subtree/
基本思路
主要思路是:首先根据parents父亲表示法构造图的邻接表表示法graph;genes存储每个结点的对应树的所有基因,但是为了之后的编程方便,每个结点都默认有0这个基因;ans存储每个结点的最小缺失基因。
采用递归算法dfs,计算一个结点的ans值和genes值,计算方法如下图所示:


1 | class Solution{ |
上述代码超时了,原因是23-25行的set插入操作。我们在set合并时,永远把小的set合并到大的set中。
1 | class Solution{ |
栈排序
https://leetcode-cn.com/problems/sort-of-stacks-lcci/
解法1
采用手写堆的方法
1 | class SortedStack { |
解法2
采用priority_queue的方法,其实priority_queue底层也是堆实现的
1 | class SortedStack { |