
https://zxjcarrot.github.io/publication/spitfire/spitfire.pdf
introduction
our approach
Since the CPU is capable of directly operating on NVM-resident data, Spitfire does not eagerly move data from NVM to DRAM. We show that lazy data migration from NVM to DRAM ensures that only hot data is promoted to DRAM.
要决定怎么eager,怎么lazy。
background
NVM-aware Optimizations in Hymem
Data Migration Policy
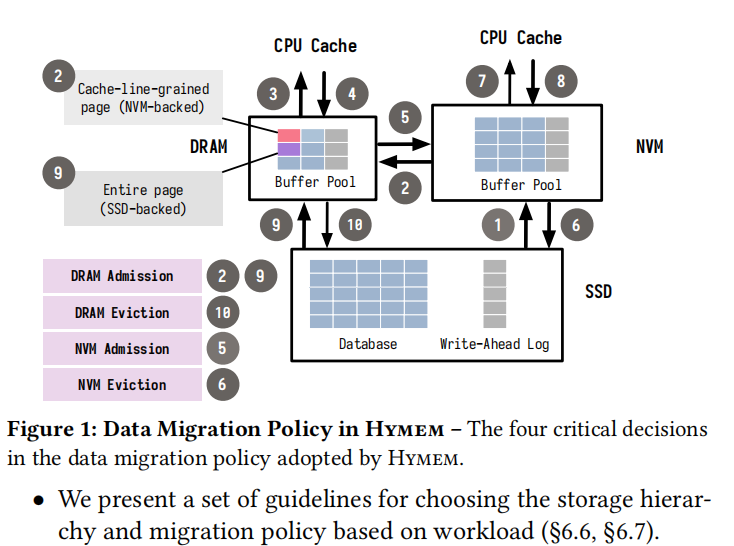

the four critical decisions in the data migration policy adopted by Hymem include: DRAM admission, DRAM eviction, NVM admission, and NVM eviction:
- dram admission:数据要么从NVM读到DRAM,要么从SSD读到DRAM;
- DRAM eviction:解决数据要evict的话,要evict到NVM还是SSD。
如果page在admission queue里面,则从admission queue中删除这个page,然后将page放到NVM中;
否则,将page加入到admission queue中,然后evict到SSD中。
Cache-line-grained Loading
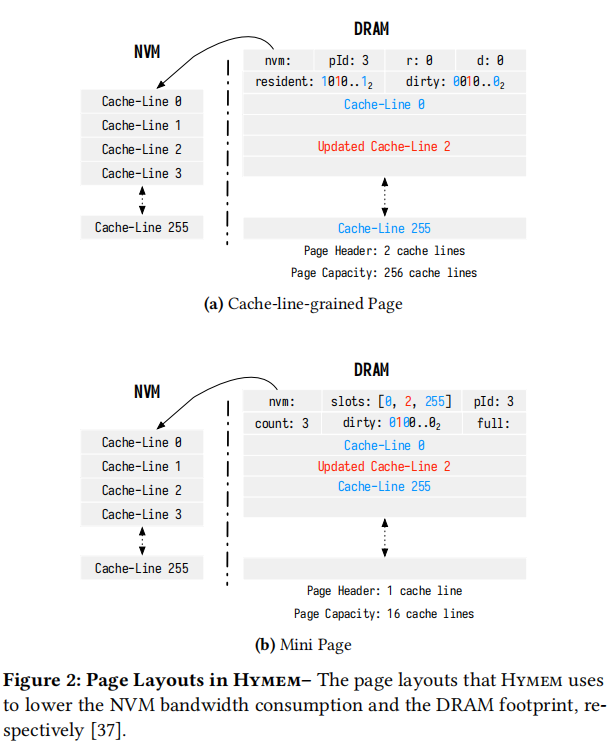

我们使用一个DRAM page来存储正在访问的NVM page,但并不是把这个NVM page的所有cache line都加载进来。在DRAM page中有header,存储page的元信息,其中resident表示DRAM page中256个cache line中第几个是已经从NVM page的对应cache line加载进来的,nvm表示这个DRAM page对应哪个NVM page;接下来,有256个cache line,至于哪些是从NVM page加载进来的,这要看resident位了。以上就是所谓的cache-line-grained page。
如果只加载了NVM page中的很少几个cache line怎么办,不能这样DRAM page中的256个cache line中会剩下很多cache line没有用,造成了空间浪费,于是我们决定使用mini page,只有16个cache line,只存储加载进来的cache line,比如figure 2(b)中,count=3表示目前只加载了3个cache line,slots数组中存储了这个3个cache line分别对应NVM page中的哪些cache line。
NVM-Aware Data Migration
Once a page is selected for eviction or promotion, Spitfire uses the probabilistic data migration policy for determining the storage tier to which the page must be migrated.
spitfire相对于Hymem的不同点是它采用概率技术来决定当要evit的时候,到底evict到哪里。
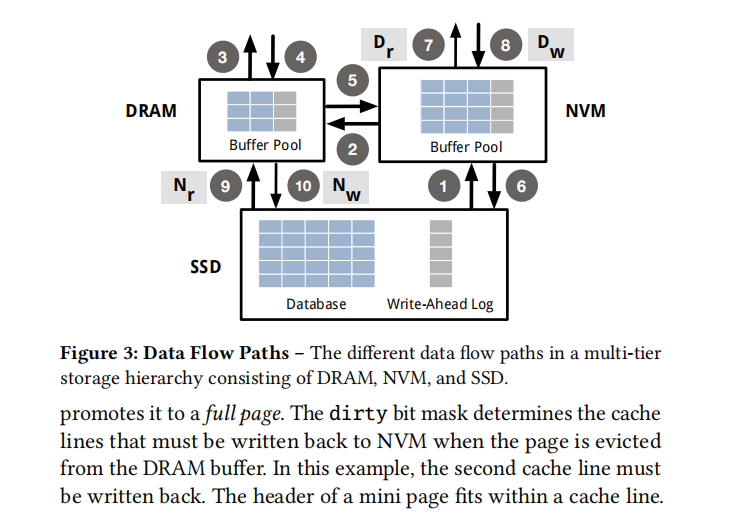

We now describe how Spitfire leverages the additional data flow paths introduced by NVM (❼,❽,❾,❿) to minimize the performance impact of NVM and to extend the lifetime of the NVM and SSD devices:
- 最小化NVM的performance impact,也就是最大化发挥NVM的性能优势
- 提高SSD和NVM的使用寿命
之后介绍的data migration是基于两个原则的:
- 不要破坏DRAM中原有的热数据
- 不要破坏NVM中原有的温数据
Bypass DRAM during Reads(Dr)
Let Dr represent the probability that Spitfire moves data from NVM to DRAM during read operations.
在读数据的时候有好几种可能(不包括CPU cache):
- 直接在DRAM中找到数据
- 如果在DRAM中找不到 并且 在NVM中找到了,就把数据从NVM迁移到DRAM(对应figure3 的2路径)
- 如果在DRAM中找不到 并且 在NVM中找到了,就直接读取数据(对应figure3中的7路径)
- 如果在DRAM中找不到 并且 在NVM中找不到,就把数据从SSD中迁移到NVM(对应figure3中的1路径)
- 如果在DRAM中找不到 并且 在NVM中找不到, 就把数据从SSD中迁移到DRAM(对应figure3中的9路径)
下图是读数据的路线图。

Dr的数值对应的就是figure3中路径2的概率,也即把数据从NVM迁移到DRAM的概率。如果Dr是1,那就意味着eager migration,每次都要经过DRAM;“when Dr = 0.01, Spitfire moves a page from NVM to DRAM only once every hundred times,Otherwise, it directly serves the read operation using the page residing on NVM”
They are beneficial when the capacity of DRAM is smaller than that of NVM. A lazy migration strategy ensures that warm pages on NVM do not evict hot pages in DRAM.
那么这个Dr就是一个参数了,需要调优,怎么调整才好呢?文章中的思想是采用机器学习的思路,也就是让set fits within DRAM的工作集采用较大的Dr,让不那么fit的工作集采用较小的Dr。This strategy ensures that only hot data is stored in DRAM。(不懂)
即使采用了lazy migration,如果对一个page频繁访问的话,这个page也迟早会放到DRAM中,这就保证了hot data会最终在DRAM中。
Bypass DRAM during Writes(Dw)
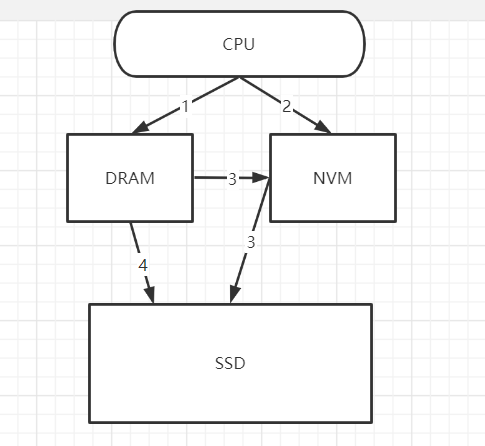

在传统的系统中,“ As transactions tend to generate multiple log records that are each small in size, DBMSs use the group commit optimization to reduce this I/O overhead”;但是,“Unlike SSDs, the CPU is capable of directly persisting data on NVM via write operations (❽) . Spitfire leverages this path to provide synchronous persistence with lower overhead”。其实,直接将日志之类的信息持久化到NVM中,可以减少总体的延迟,而且也避免了evict DRAM中的hot data。
Dw表示写数据到DRAM中的概率,也即figure3中路径8的概率。我们可以直观地知道,如果对于日志之类的信息,Dw肯定要很小,也就是lazy policy。
“Our evaluation demonstrates that this optimization improves Spitfire’s performance on write-intensive workloads”
Bypass NVM During Reads(Nr)
Spitfire instead makes use of the data flow path from SSD to DRAM (❾). When it observes that a requested page is not present in both the DRAM and NVM buffers, it copies the data on SSD directly to DRAM, thus bypassing NVM during read operations.
这个情况对应于读数据的第4种或第5种可能性。
但是具体使用哪一种,是由超参数Nr决定的。Nr表示从SSD读数据时copy到NVM的可能性,这个Nr越大,就意味着越不lazy。
When a page is fetched from SSD and later evicted from DRAM, an eager policy necessitates two writes to NVM: once at fetch time and again when it is evicted from DRAM. With a lazy policy (e.g., Nr = 0.01), Spitfire installs a copy of a modified page on NVM only after it has been evicted from DRAM. This eliminates the first write to NVM when Spitfire fetches the page from SSD.
如果Nr比较大的话,我们就可能有两次写NVM的操作,第一次是在从SSD读数据的时候,写到了NVM中,第二次是把数据从DRAM evict到NVM的时候。如果Nr比较小的话,就可以避免了第一次操作NVM的可能性,但是文章中没有提到省略第一个NVM写和不省略第一次NVM写之间有什么trade-off,我猜测是这种情况:如果省略第一个NVM写的话,只能把数据存到DRAM中,这就导致了如果这个数据是冷数据,就会evict掉DRAM中的热数据;如果不省略第一个NVM写的话,虽然多了一个NVM写,但是后续的读写会直接读写NVM,避免了DRAM中热数据的eviction。
虽然作者没有明说上述的trade-off,但是后面一段也能推出这个思想。
It employs: a lazy policy for migrating data from NVM to DRAM (Dr = 0.01), and a comparatively eager policy while moving data from SSD to NVM (Nr = 0.2). While this scheme increases the number of writes to NVM compared to the lazy policy, it enables Spitfire to deliver higher performance than Hymem。
Hymem采用的是直接将SSD中的数据迁移到DRAM中,也就是完全的lazy策略。但是spifrie没有那么lazy,它有一定的可能性将数据从SSD复制到NVM中,虽然也不是很大,但也不是完全lazy。这样可以使得CPU 直接读写NVM有较大的可能。
Bypass NVM During Writes(Nw)
By bypassing NVM during writes, Spitfire ensures that only pages frequently swapped out of DRAM are stored on NVM. (不懂)
Besides reducing the number of writes to NVM, this optimization also ensures that only warm pages are stored in the NVM buffer. If Spitfire employs a lazy policy while copying data from NVM into DRAM (Dr = 0.01), this optimization prevents colder DRAM-resident pages from polluting the NVM buffer.
Lower values of Nw reduce downward data migration into NVM. Such a lazy policy is beneficial when the capacity of DRAM is comparable to that of NVM since it ensures that colder data on DRAM does not evict warmer data on NVM.
如果随便就把数据从DRAM迁移到NVM中,本身NVM空间也不是很大(和DRAM差不多大),那么NVM中的warm数据很容易被evict掉。所以要采用从DRAM到NVM迁移的lazy模式比较好。
Adaptive Data Migration
以上的参数组合P: {Dr, Dw, Nr, Nw}应该是什么,才能对一个工作任务达到最好的效果呢?文章中有说。
Cost Function
这里spitfire运用了机器学习的思路,来在一段时间内收集系统运行的数据,然后观察吞吐量,最后计算损失函数,找到参数P使得损失函数最小。
The crux of our approach is to periodically track a set of target metrics, and then adapt P in the background. Spitfire evaluates a candidate policy across millions of buffer pool requests to ensure that its impact on the target metrics is prominently visible to the search algorithm. Over time, the search algorithm automatically optimizes P for the target workload and storage hierarchy.
transactional throughput (T) metric to guide the adaptation mechanism.
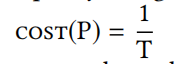

Search Algorithm
Spitfire adapts the policy using simulated annealing (SA,模拟退火) [21]. This iterative search technique finds a policy Popt that minimizes the cost function.
采用了模拟退火算法来minimize损失函数。
System Architecture
Multi-tier buffer management
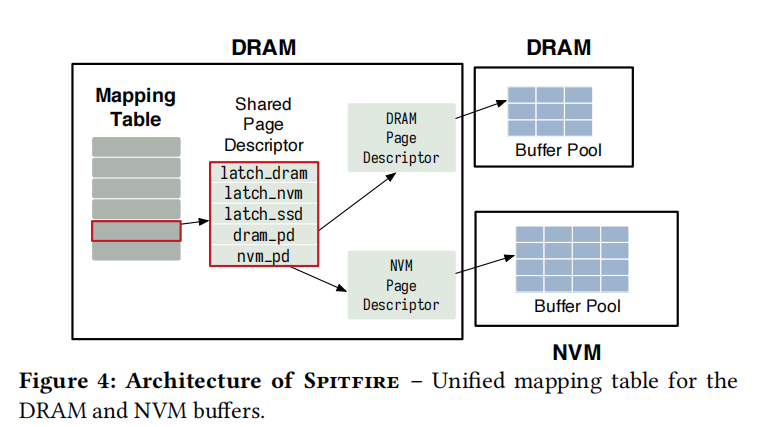

With this configuration, Spitfire seeks to keep the hot, warm, and cold database pages on DRAM, NVM, and SSD, respectively. Since the CPU is capable of directly operating on both the DRAM and NVM buffers, Spitfire maintains a mapping table on DRAM to bound latency. This mapping table serves to keep track of pages buffered in DRAM and NVM.
As shown in Figure 4, Spitfire maintains a shared page descriptor for every logical page P in the mapping table. The descriptor contains latches for thread-safe data migration and pointers to the DRAM and NVM page descriptors.
device-specific page descriptors contains:
- number of users of the page
- a bit indicating whether the page is dirty
- a physical pointer to the page freme residing on the device
Similar to Hymem, Spitfire adopts the CLOCK cache replacement policy to reclaim space in the DRAM and NVM buffers.
Concurrency Control and Recovery
为了实现并发操作,利用了下面的数据结构和协议:
- concurrent hash table for managing the mapping from logical page identifiers to shared page descriptors
- concurrent bitmap for the cache replacement policy
- multi-versioned timestamp-ordering (MVTO) concurrency control protocol
- ) concurrent B+Tree for indexing with optimistic lock-coupling
- lightweight latches for thread-safe page migrations
现在有很多问题:什么是optimistic lock coupling;latch和lock有什么区别;复习一下B+Tree,现在参考【2】【3】【4】
Concurrent Index
由于NVM的存在,IO开销减少了,因此computational overhead asscociated with index lookups所占的比例增大了,这就是为什么使用B+Tree with optimistic lock-coupling的原因,因为乐观锁耦合技术减少了与悲观锁耦合相关的争用开销。
Thread-Safe Page Migration
引用
【1】论文阅读:Spitfire:https://zhuanlan.zhihu.com/p/355572739
【2】《乐观锁耦合:扩展性强且高效的通用同步方法》https://www.jianshu.com/p/32cb5f107a01
【3】《论文解读:optimistic lock coupling》https://zhuanlan.zhihu.com/p/269533719
【4】lock和latch的区别:https://github.com/sdg-sysdev/bdb-study/blob/master/btree_locking.txt